AIエージェントと強化学習の深い統合:分離から革命へ
2025年9月10日Ollie @puppyone
核心的な観察: AIエージェント開発の初期の波は、主にプロンプトエンジニアリングに依存しており、従来の強化学習(RL)とはほとんど関連がありませんでした。しかし、最近の研究は、RLが現在、エージェントを汎用知能へと推進する中心的な駆動力になっていることを示しています。2025年5月から8月までの最先端の研究に基づき、このレポートは3つの主要な統合トレンドを明らかにします。
シングルエージェントRLにおけるパラダイム革新
RLHFからRLVRへ:客観的報酬設計におけるブレークスルー
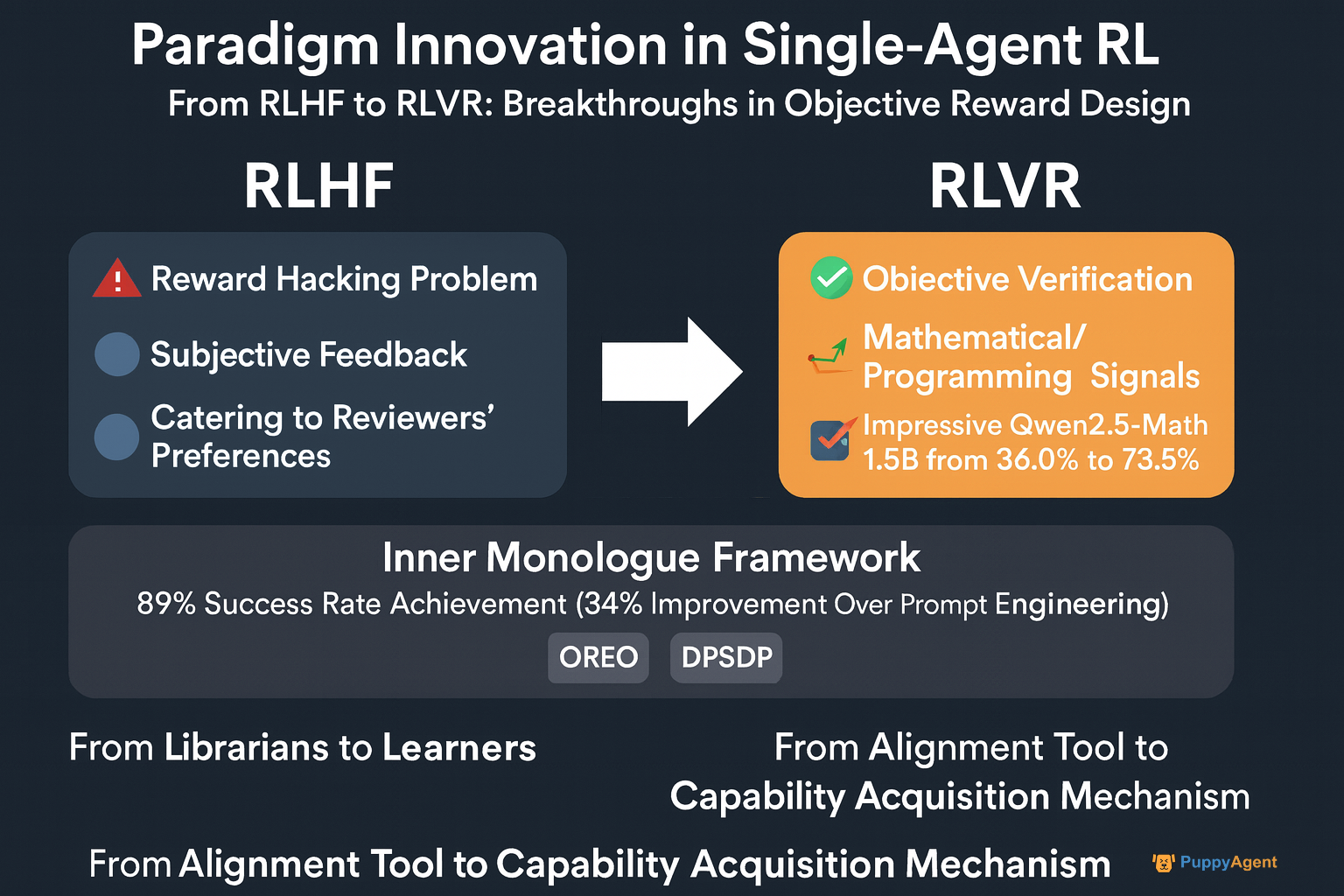
従来のRLHF(人間からのフィードバックによる強化学習)は、主観的な人間のフィードバックに依存し、「報酬ハッキング」の問題に悩まされていました。ICML 2024で、OpenAIの研究者ジョン・シュルマンは率直に次のように述べました。「モデルは、問題を純粋に解決するのではなく、レビュー担当者の好みに合わせることを学習することがわかりました。」これにより、数学やプログラミングなどの分野からの客観的で検証可能なシグナルを活用するRLVR(検証可能な報酬による強化学習)への移行が促進されました。アリババのQwenチームは、このアプローチを適用して、MATH500ベンチマークにおけるQwen2.5-Math-1.5Bの精度を36.0%から73.6%に向上させ、RLが「アライメントツール」から「能力獲得メカニズム」へと進化していることを示しました。
カリフォルニア大学バークレー校のセルゲイ・レヴィン教授は次のように述べています。「私たちは根本的な変革を目の当たりにしています。初期のエージェントは広大な記憶を持つ司書のようでしたが、今では彼らを真の学習者に変えることを目指しています。」彼のチームのインナーモノローグフレームワークは、この変化を例証しています。エージェントは環境との閉ループフィードバックを通じて「内なる対話」を発達させ、ロボットナビゲーションタスクで89%の成功率を達成しました。これは、純粋なプロンプトエンジニアリング手法よりも34%高い数値です。一方、DeepMindのOREOアルゴリズムは、ベルマン方程式を最適化することで多段階の推論を強化し、DPSDPはマルチエージェントシステムに直接的なポリシー検索機能を提供します。
身体性知能とマルチエージェント統合
身体性知能における実践的なブレークスルー
MITのダニエラ・ルス教授はインタビューで次のように述べました。「私たちはついにロボット知能の質的な飛躍を目の当たりにしています。」彼女が言及していたのは、大規模言語モデルと強化学習を統合したシステムであるLLaRPフレームワークの画期的なパフォーマンスでした。このシステムは、これまでに見たことのない1,000の身体性タスクで42%の成功率を達成し、これは従来のベースラインよりも1.7倍高い数値です。さらに注目すべきは、凍結されたLLMを汎用的なポリシーに変換するために、少数の知覚および行動デコーダーをトレーニングするだけで済むことです。
NVIDIAの研究科学者であるリンシー・ファンは次のようにコメントしています。「ユーレカプロジェクトは、報酬設計に対する私たちの理解を完全に変えました。」このプロジェクトでは、GPT-4が強化学習のための報酬関数コードを自動的に生成します。複雑なロボットアーム操作タスクでは、AIが生成した報酬関数は、人間の専門家が丹念に作成したものよりも実際に優れたパフォーマンスを発揮しました。同様に、Google DeepMindのロボットチームもこの道筋でブレークスルーを達成しています。彼らのRT-2システムは、視覚-言語-行動モデルに基づいており、ロボットが複雑な自然言語の指示を理解し、対応する行動を実行することを可能にします。
マルチエージェント協調の進化
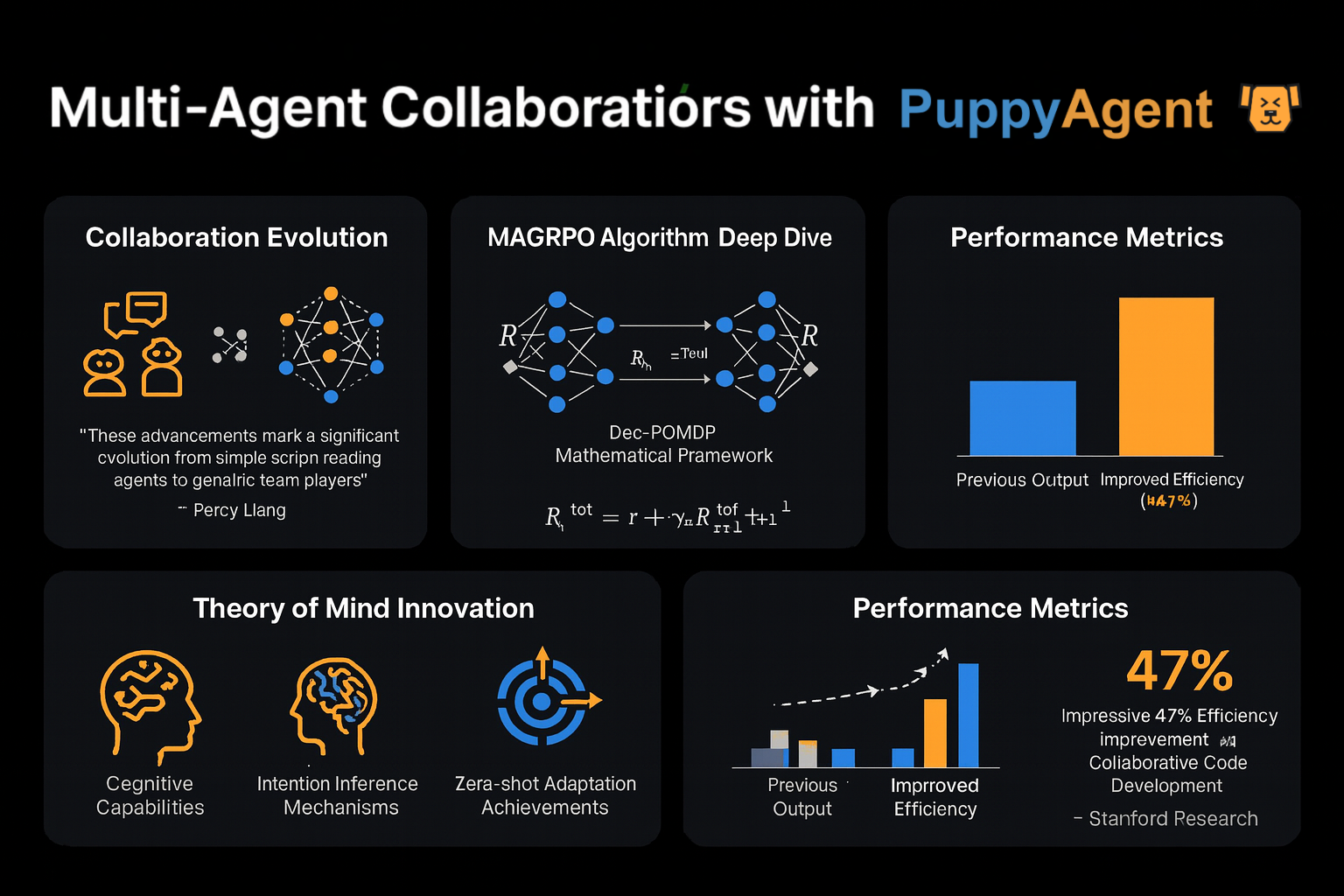
スタンフォード大学のパーシー・リャン教授は次のように述べています。「初期のマルチエージェントの議論は、数人が独立して台本を読んでいるようなものでした。今では、真のチームワークが見られます。」最新のMAGRPOアルゴリズムは、LLMの協調をDec-POMDP(分散型部分観測マルコフ決定過程)としてモデル化し、共同報酬の最適化を通じて真の協力を実現します。協調的なコード開発テストでは、このアプローチは従来のマルチターン対話手法と比較して効率を47%向上させました。さらに興味深いことに、別のスタンフォード大学のチームは、エージェントに「心の理論」モジュールを装備させ、他の参加者の意図や戦略を推測できるようにしました。これにより、ゼロショットのゲーム環境で驚くべき適応能力を発揮しました。
学術的トレンドの変化
トップカンファレンスでの焦点
学術的トレンドの変化は明らかです。ICML 2025でのチュートリアル「生成AIと強化学習の出会い」は2,000人以上の参加者を集め、講演者のチェルシー・フィン教授は次のように切り出しました。「もしあなたがまだ純粋にプロンプトエンジニアリングに頼っているなら、すでに取り残されている可能性が高いでしょう。」ACL 2025では、初の「REALM」ワークショップが開催され、RLベースのエージェントトレーニングが議題の中心に据えられました。予想の3倍の論文投稿がありました。ICLR 2025では、人間のようにコンピュータを操作し、複雑なタスクで前例のないレベルの自動化を達成するオープンソースのAgent Sフレームワークなど、複数のブレークスルーが紹介されました。
最も注目すべきは、NeurIPS 2024での「オープンワールドエージェント」ワークショップでヤン・ルカン氏が基調講演を行い、次のように強調したことです。「静的な知識検索はもはや十分ではありません。私たちが必要としているのは、オープンエンドな環境で継続的に学習し、適応できるエージェントです。」この視点は参加者の間で広く共感を呼び、円卓会議では、複数のチューリング賞受賞者が、強化学習が人工汎用知能の核心的な課題に取り組むための最も有望な道筋を提供することに満場一致で同意しました。
課題と機会
現実世界の課題と産業界の機会
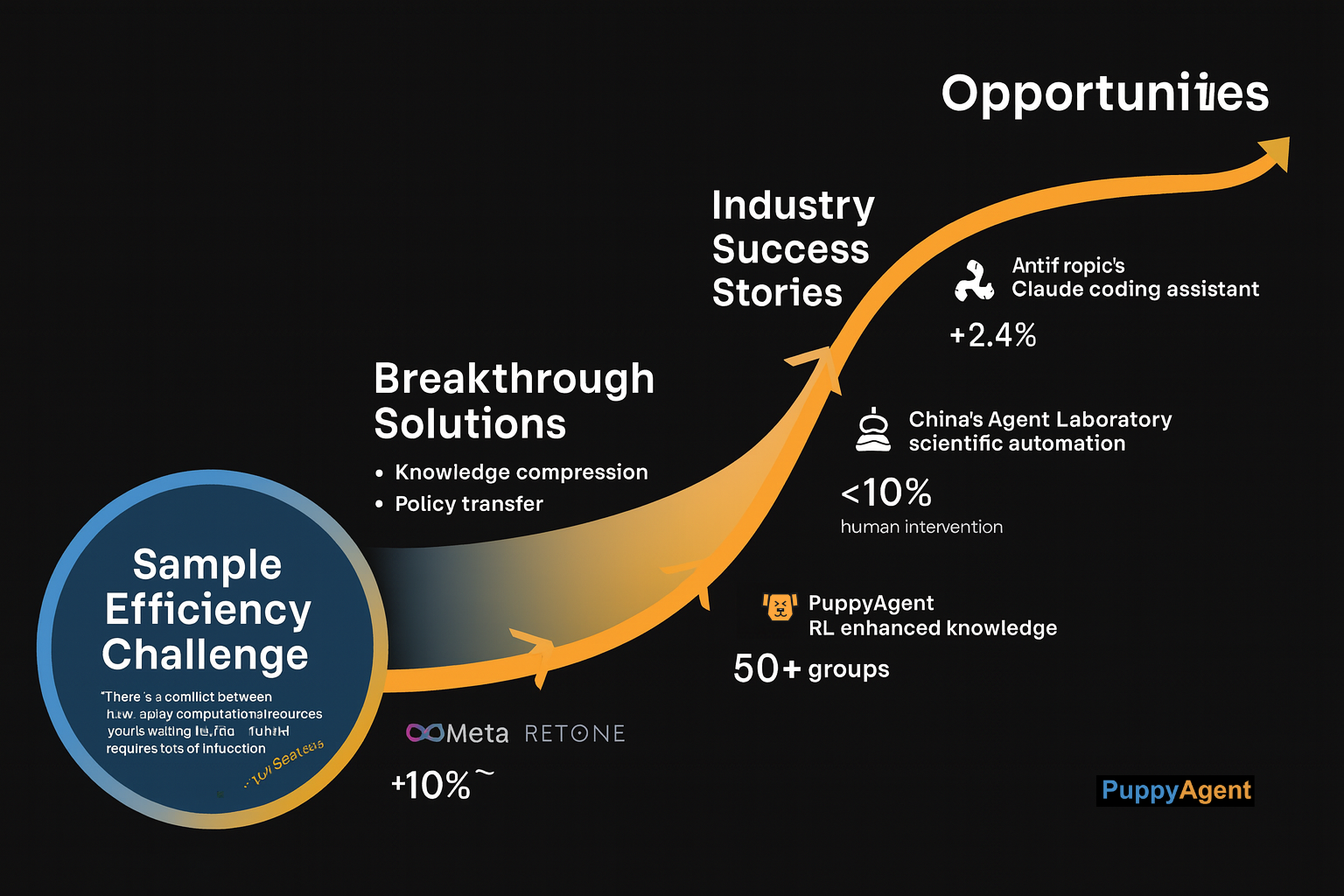
もちろん、重大な課題は残っています。OpenAIを去る前の最後の公式スピーチで、イリヤ・サツケバーは率直に認めました。「私たちの最大の困難はサンプル効率にあります。各LLMの推論は膨大な計算リソースを消費しますが、従来のRLは何百万ものインタラクションを必要とします。」この矛盾が、新たな解決策を生み出しています。例えば、Metaの研究チームは、大規模モデルから知識を圧縮して小規模モデルに移し、RLトレーニングを行い、学習したポリシーを大規模モデルに戻す「蒸留ベースの学習」手法を開発しました。
産業界の反応も同様に迅速です。AnthropicのClaudeチームは現在、RLを活用したコーディングアシスタントのベータテストを行っており、内部関係者によると、複雑なプログラミングタスクにおけるそのパフォーマンスは「驚異的」だということです。一方、中国のエージェント研究所プロジェクトは、文献レビューや実験計画から論文執筆まで、科学研究ワークフローの完全な自動化をすでに達成しており、人間の介入は10%未満です。この自動化のトレンドは、より多くの垂直ドメインに急速に浸透しています。例えば、知識管理では、puppyoneのようなインテリジェントな知識ベースシステムが、文書理解、知識抽出、自動質問応答に強化学習メカニズムを適用し始めています。ユーザーのクエリパターンやフィードバックから継続的に学習することで、このようなシステムは知識の整理と検索戦略を反復的に最適化し、受動的な情報リポジトリから能動的なインテリジェントアシスタントへと変貌を遂げています。深センAIRSがリリースしたAIRSTONEオープンソースプラットフォームは、身体性知能研究に前例のない計算サポートを提供し、すでに50以上の国際的な研究グループによって使用されています。
結論

エージェントとRLの分離は確かに存在しましたが、MITのトミ・ヤッコラ教授が適切に表現したように、「これは初期のインターネットが静的なウェブページしか持っていなかったようなものです。動的なインタラクションこそが真の未来です。」 私たちは、事前訓練された知識に基づく静的な推論から、経験からの継続的な学習による動的な最適化へと、根本的な変化を目の当たりにしています。RLVRはエージェントが数学的推論のようなハードスキルを獲得することを可能にし、LLaRPはクロスシナリオの汎化能力を示し、MARLベースのマルチエージェントシステムは真の協調的知能の出現を明らかにしています。
DeepMindの創設者デミス・ハサビスが最近述べたように、「強化学習は単なる訓練方法ではなく、知能そのものの核心的なメカニズムです。」試行錯誤による学習、ポリシーの最適化、環境への適応に関する深い洞察を持つこのかつて「見過ごされた分野」は、今やエージェントが人工汎用知能へと向かう旅路における最も堅固な理論的基盤となりつつあります。この収束は、テクノロジーの単純な積み重ねではなく、基礎科学に裏打ちされた認知主導の革命なのです。
主要参考文献: ICML 2025チュートリアル、ACL 2025 REALMワークショップ、Qwen2.5-Mathテクニカルレポート、LLaRP論文、MAGRPOアルゴリズム、インナーモノローグ、およびその他の最新研究