AI自己進化:LLMクローズドループシステムとマルチエージェントフロンティアの包括的レビュー
2025年9月4日Ollie @puppyone
なぜ今、「LLMの自己進化」を真剣に研究しなければならないのでしょうか?端的に言えば、今日の強力なモデルのほとんどは「静的な成果物」です。一度きりのオフライン学習を経てデプロイされた後、分布シフト、新しいタスク形式、そして急速に進化するツールエコシステムに直面します。それらは、高価で遅れがちな人間の再トレーニングに頼って追いつくしかありません。このパラダイムは、非定常な世界で損失を生み出し続けます。時代遅れの知識による技術的負債、データのラベリングとクリーニングにかかる継続的なコスト、そしてロングテールの複雑な推論や領域横断的な協調における脆弱性です。私たちが必要としているのは、単に大きなモデルではなく、実行中に学習し、環境の中で自己修正し、クローズドループで継続的に成長できるシステムなのです。
 画像ソース: puppyone
画像ソース: puppyone
私たちは2025年6月から8月にかけての「LLM / AIエージェントの自己進化/自己改善」に関連する研究に焦点を当て、包括的なレビューと進捗アップデートを提供しました。開発者や研究者のために、「自己進化」の設計空間と実現可能な道筋を明らかにしたいと考えています。どの問題からループを閉じるべきか、最小実行可能システムをどう構築するか、「本当に強くなっている」ことを測定するためにどの指標を使うか、そして「自己進化」と「制御可能で信頼できる」ことをエンジニアリングレベルで両立させるにはどうすればよいか、といった点です。
概要(2025年6月~8月の概観)
定義
学術界および産業界は、「自己進化」について統一された定義にまだ至っていません。しかし、8月には「自己進化エージェント/自己進化AIプロキシ」に焦点を当てた2つの体系的なレビューが相次いで発表されました。これらは、「何を、いつ、どのように進化させるか」を中心に据えた構造化されたフレームワークを提案し、対話型のフィードバック、環境シグナル、クローズドループ最適化による継続的なシステム改善に焦点を当てています。これは、このトピックが段階的な収束のコンセンサスウィンドウに入ったことを示しています。
代表的なアプローチ
 画像ソース: puppyone
画像ソース: puppyone
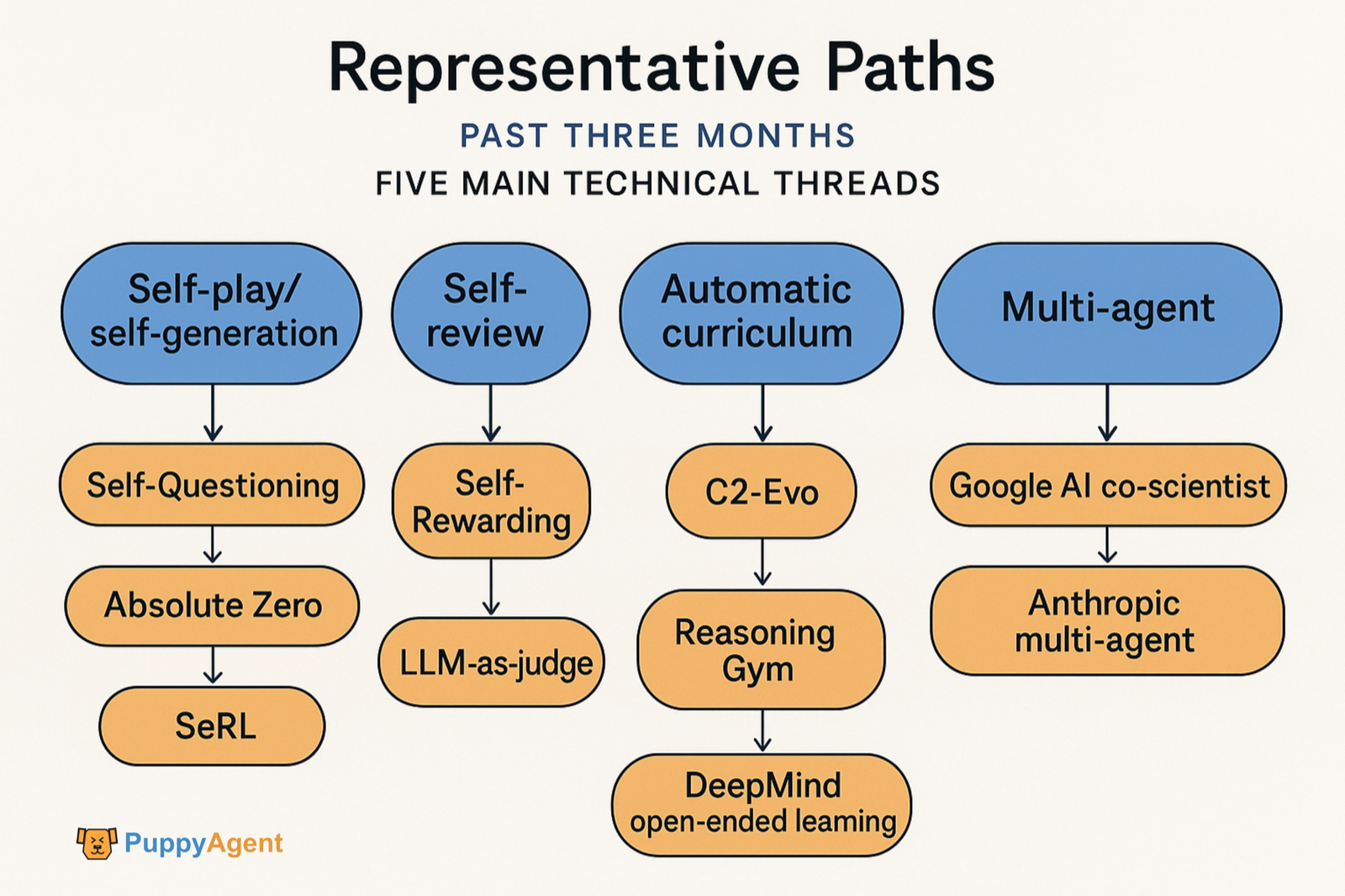
過去3ヶ月間、代表的な研究は主に5つの技術的潮流に集中していました:
- 外部データなしの自己対戦/自己生成タスク(Self-Questioning, Absolute Zero, SeRL)。
- 自己レビュー/自己報酬(Self-Rewarding, LLM-as-judge)。
- データとモデルの共進化(C2-Evo, NavMorph)。
- 自動カリキュラム/オープンエンドな進化(SEC, Reasoning Gym, DeepMindのオープンエンド学習の伝統)。
- マルチエージェントによる自己改善ワークフロー(Google AI co-scientist, Anthropicのマルチエージェントシステム)。また、「自己改善を支える認知習慣は何か」に関する定量的証拠と診断手法も登場しています。
評価と安全性
Reasoning Gymのような「検証可能な報酬」を持つプロセス生成環境は、クローズドループの自己進化トレーニングと評価の取っ掛かりとなっています。GoogleのAI co-scientistは、内部の自己対戦ランキングとEloスコアをGPQA問題の正解率と相関させています。Anthropicは、LLM-judgeと人間のレビューの組み合わせ、およびマルチエージェントシステムのエンジニアリング保護とトレーサビリティを強調しています。一方、「自己改善」における「チーティング/幻覚」とアラインメントのリスクは、サンドボックス化とガーディアン戦略のさらなる探求につながっています。
概念と境界:「自己進化する」LLM/AIエージェントとは何か
自己進化
自己進化は単一のトレーニングパラダイムではなく、クローズドループシステム設計の一分野です。最小限の人的介入で、システムは環境フィードバック、ツール実行、自己対戦、自己レビューなどのメカニズムを通じて、継続的にデータ/タスクを生成し、戦略とパラメータを改善し、あるいは自身のツールチェーン/コードを書き換えます。これにより、分布外タスク、長期タスク、複雑な推論において時間とともに強くなることができます。最近の2つのレビューでは、これをシステム入力、エージェントシステム、環境、オプティマイザの4つのコンポーネントを持つフィードバックループとして抽象化しています。また、「何を、いつ、どのように進化させるか」という3つの次元に基づいて方法論を評価・要約し、静的なベースモデルから生涯適応性を持つ「自己進化エージェント」システムへの移行を強調しています。
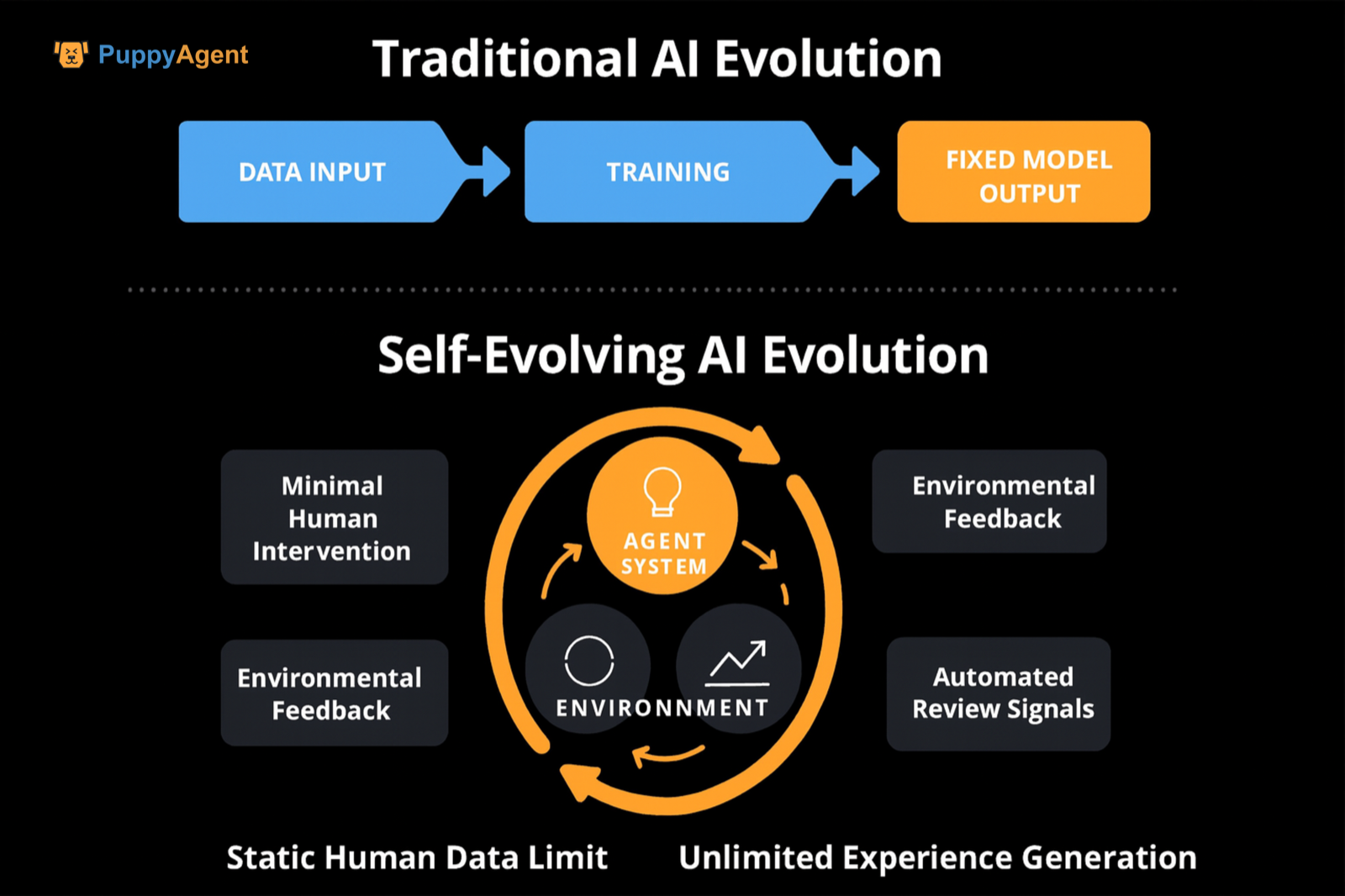
従来の自己教師あり/インストラクションファインチューニングとの違い
 画像ソース: puppyone
画像ソース: puppyone
違いは、「経験/インタラクションデータ」の優位性、タスク空間と難易度の動的生成、そしてレビュー/報酬シグナルの自動化されたソース(自己レビュー、実行可能検証、競争ランキングなど)を重視する点にあります。これにより、静的な人間データの限界を突破します。DeepMindは「経験の時代」を提唱し、インタラクション経験を主要なデータソースとし、報酬シグナルを世界に根ざさせることを主張しています。長期的にはワールドモデルと報酬関数を継続的に更新してバイアスを修正することを提案しており、「自己進化」の概念的・経路的な論拠を提供しています。
研究のランドスケープとフロンティアのラボ/チーム/研究者
 画像ソース:pexels
画像ソース:pexels
Google Research
Gemini 2.0をベースにしたAI co-scientistは、「スーパーバイザー+専用エージェント」のマルチエージェント協調を採用しています。コンポーネントには、生成、リフレクション、ランキング、進化、近接性、メタレビューエージェントが含まれます。自動化されたフィードバックと自己対戦による科学的討論、ランキングトーナメント、進化的プロセスを活用し、「テスト時にスケーラブルな計算」を伴う自己改善ループを形成します。その内部Elo自己評価は、難易度の高いGPQAデータセットの正解率と正の相関があります。小規模サンプルの専門家レビューでは、その出力が新規性とインパクトの点でいくつかの最先端(SOTA)ベースラインを上回ることが示唆されています。
Anthropic
Anthropicは、マルチエージェント研究システムのエンジニアリング計画を公に詳述しており、「オーケストレータ-ワーカー」の並列サブエージェント、外部メモリ、LLM-judgeスコアリングと人間によるレビューの組み合わせを特徴としています。「エージェントが自己を改善する」(モデルが失敗モードを自己診断し、プロンプト/ツール記述を書き換える)ことを提案し、ツールのユーザビリティに関するタスク時間を約40%削減しました。マルチエージェントシステムにおける創発的行動と、エンジニアリングレベルの可観測性、段階的リリース、ロールバックセーフガードを重視しています。
Meta
ザッカーバーグは第2四半期の決算報告で、「スーパーインテリジェンスラボ」の戦略的焦点として「自己改善」を明確に強調し、人間データへの依存を減らし、「自己改善」の道を開発することを強調しました。これは「パーソナルスーパーインテリジェンス」のビジョンと関連しています。
OpenAIと学術界の交差点
メディアの報道によると、サム・アルトマンは現在のフェーズを「スローな離陸を伴う事象の地平線を越えた」と表現し、短期的な自己改善は完全に自動化されているわけではなく、むしろ「AIを使ってAI研究を加速させる」という再帰的な強化であると強調しています。同時に、「ダーウィン-ゲーデルマシン」(CluneとSakana AIチームによる)は、自身のログを自動的に読み、一点のコード修正を提案・実装し、SWE-BenchとPolyglotで世代的な反復改善を示しています。しかし、それはまた「自己欺瞞/ログ偽造」のリスクも露呈しており、サンドボックス化と欺瞞対策評価の重要性を浮き彫りにしています。
技術的メカニズムの分類と代表的な研究
外部データなしの自己対戦 / 自己生成タスク
-
自己質問言語モデル (SQLM): トピックプロンプトが与えられると、非対称的な「提案者-解決者」自己対戦フレームワークが質問と回答を生成し、両方のコンポーネントが強化学習(RL)によって訓練されます。提案者は中程度の難易度(簡単すぎず、難しすぎない)の問題を生成することで報酬を得、解決者は正解率の代理として多数決を用いて評価されます。プログラミングタスクでは、ユニットテストが検証として機能します。実験結果は、人間が提供したデータなしで、3桁の乗算、OMEGA代数、Codeforcesベンチマークで持続的な改善を示し、「問題生成-問題解決」のクローズドループパラダイムを表しています。
-
アブソリュート・ゼロ (AZR): 検証可能な報酬を伴う強化学習 (RLVR)パラダイムを提案し、外部データを一切必要としません。単一のモデルが自律的にコードベースの推論タスクを生成し、コード実行エンジンを使用してタスクとその解決策の両方を検証し、オープンエンドでありながら根拠のある学習を導くための統一された検証可能な報酬ソースを提供します。AZRは、数万の人間がキュレーションした例に依存するゼロ教師ベースラインと比較して、コーディングと数学的推論タスクで最先端のパフォーマンスを達成または上回っており、タスク生成、検証、学習の統合されたクローズドループを強調しています。
-
SeRL: 「自己指示」(フィルタリングを伴うオンラインでの指示拡張)と「自己反省」(報酬を推定するための多数決)を組み合わせ、自己生成データでの強化学習を可能にします。このアプローチは、高品質な人間提供の指示と検証可能な報酬への依存を減らし、複数の推論ベンチマークと異なるモデルバックボーンで優れたパフォーマンスを示します。
-
AMIE医療対話自己対戦拡張(業界レポート): 疾患と臨床シナリオのカバレッジを拡大するため、Googleは自動フィードバックメカニズムを備えた「自己対戦診断対話シミュレーション環境」を開発し、トレーニングを充実させ加速させました。これは、ヘルスケアのような安全性が重要な領域でAIをスケールアップするために自己対戦手法を適用する業界レベルの取り組みを表しています。
 画像ソース:pexels
画像ソース:pexels
自己評価 / 自己報酬と敵対的批評家の進化
-
自己報酬・自己改善: 「解の生成と検証の間の非対称性」を活用し、参照回答のない領域でモデルが独自の報酬シグナルを提供できるようにします。この研究は、自己判断による報酬が、カウントダウンパズルやMITインテグレーションビー問題のようなタスクで、形式的な検証に匹敵することを示しています。合成質問生成と組み合わせることで、完全な自己改善ループを形成します。この研究は、自己報酬トレーニングを受けた蒸留済み7Bモデルが、MITインテグレーションビーの参加者レベルのパフォーマンスに達したことを報告しており、「LLM-as-judge」パラダイムが報酬メカニズムとして持つ領域横断的な可能性を示しています。
-
自己対戦批評家 (SPC): 同じベースモデルの2つのコピーを訓練し、「ずる賢い生成者」(意図的に微妙な推論エラーを生成する)と「批評家」(それらを検出しようとする)として敵対的な自己対戦に従事させます。ゲームの結果に基づいた強化学習を使用することで、批評家は欠陥のある推論ステップを特定する能力を徐々に向上させ、手動のステップレベルの注釈の必要性を減らします。実験では、ProcessBench、PRM800K、DeltaBenchなどのベンチマークでのプロセス評価で大幅な改善が示されています。さらに、訓練された批評家は、多様なLLMでテスト時の推論探索をガイドし、MATH500やAIME2024などの数学的推論タスクでのパフォーマンスを向上させることができます。これは、敵対的な自己対戦を通じて高品質な評価ルールを進化させることの実現可能性を検証しています。
-
Anthropicのエンジニアリング実践: マルチエージェント研究システムにおいて、AnthropicはLLM-as-judge評価と人間による評価を体系的に組み合わせており、事実の正確性、引用の正しさ、完全性、ソースの品質、ツールの効率性を含む詳細なルーブリックを使用しています。この非決定的でステートフルなシステムでの信頼性を確保するために、完全な実行トレース、外部メモリシステム、フォールトトレラントなリトライメカニズム、非同期協調などの本番環境グレードのソリューションを実装しています。これらのエンジニアリングセーフガードは、安定したスケーラブルな運用を可能にし、「本番環境対応の自己改善研究システム」のテンプレートとして機能します。
{kind=link}
データとモデルの共進化
-
C2-Evo: 「クロスモーダルデータ進化ループ」と「データ-モデル進化ループ」を提案します。ここでは、構造化されたテキストサブ問題と反復的に洗練された幾何学的図形を組み合わせた複雑なマルチモーダル問題が生成され、モデルのパフォーマンスに基づいて選択的にトレーニングに使用されます。システムは教師ありファインチューニング(SFT)と強化学習(RL)を交互に行い、複数の数学的推論ベンチマークで継続的な改善を達成します。この研究は、データ複雑性とモデル能力の動的な整合を強調し、タスクが現在の能力に対して簡単すぎるか難しすぎる「難易度の不一致」問題を回避します。
-
NavMorph: 連続環境における視覚言語ナビゲーション(VLN-CE)のための「自己進化するワールドモデル」を導入します。コンパクトな潜在表現と新しい「文脈的進化メモリ」を活用することで、モデルはオンラインナビゲーション中に環境の理解を適応的に更新し、意思決定ポリシーを洗練させます。これは、ワールドモデル(環境表現)とエージェントのポリシー(行動戦略)の間の共進化的パラダイムを反映しており、動的な実世界設定での持続的な適応を可能にします。
-
セルフ・チャレンジング (Code-as-Task): エージェントはまず「チャレンジャー」として機能し、外部ツールと対話してCode-as-Taskと呼ばれる新しい形式でタスクを生成します。各タスクは、指示、検証関数、および組み込みテストとして機能する成功/失敗の例で構成されます。これらの高品質で自己生成されたタスクは、その後、同じエージェントを「実行者」の役割で訓練するために使用され、検証結果を報酬として強化学習を行います。自己生成データのみを使用しているにもかかわらず、このフレームワークは、Llama-3.1-8B-Instructモデルの2つのマルチターンツール使用ベンチマーク(M3ToolEvalとTauBench)で2倍以上のパフォーマンス向上を達成し、「タスク生成-検証-学習」の完全に閉じたループの合成エコシステムを示しています。
 画像ソース:pexels
画像ソース:pexels
自動カリキュラムとオープンエンド学習
-
自己進化カリキュラム (SEC): カリキュラム選択を非定常な多腕バンディット問題としてモデル化し、強化学習(RL)ファインチューニングと並行してカリキュラムポリシーを学習します。「即時学習ゲイン」シグナルに基づいてタスクカテゴリを選択し、TD(0)を使用してポリシーを更新します。SECは、計画、帰納、数学的推論領域にわたる、より困難な分布外(OOD)テストセットへの汎化性能を向上させます。また、複数のドメインで同時にファインチューニングする際のスキルバランスも向上させ、タスクの難易度が適応的に進化するカリキュラムメカニズムを示しています。
-
Reasoning Gym: 代数、論理、グラフ理論、その他のドメインにわたる100以上の検証可能な報酬ベースの推論環境を提供します。その主要な革新は、手続き的生成、調整可能な複雑さ、そして固定された有限のデータセットとは異なり、ほぼ無限のトレーニングデータにあります。これにより、クローズドループの自己改善トレーニングと難易度階層型の評価に自然に適しています。Reasoning Gymは、タスク生成、検証、学習を結びつけるオープンなインフラストラクチャとして機能し、スケーラブルで根拠のある推論のための強化学習を可能にします。
-
オープンエンド学習の伝統(背景): DeepMindのXLandは、「オープンエンドなタスク生成、集団ベーストレーニング(PBT)、世代的ブートストラップ」を組み合わせた多層的なクローズドループフレームワークを導入しました。タスク分布が継続的に進化し、エージェントが前の世代から学び、行動ダイナミクスが新しい課題の生成を駆動するというオープンエンド学習の哲学を強調しています。この研究は、SECやReasoning Gymのような現代のカリキュラム駆動アプローチの基礎概念を築き、自己進化する汎用能力エージェントの重要な前例を確立しました。
マルチエージェント自己改善と科学的発見ワークフロー
-
Google AI Co-Scientist: スーパーバイザーエージェントが、科学的手法に触発された専門エージェント(「生成」「リフレクション」「ランキング」「進化」「近接性」「メタレビュー」)の連合を指揮します。システムは、新しい仮説生成のための自己対戦ベースの科学的討論と、アイデアを比較・洗練するためのランキングトーナメントを採用し、出力の品質を反映する自動化されたElo自己評価スコアを生成します。テスト時の計算量が増加するにつれて、自己評価されたEloスコアは線形に改善し、挑戦的な科学問題のセットであるGPQA Diamondベンチマークでの正解率と相関します。15のオープンな研究問題について7人のドメイン専門家による評価では、AI co-scientistは最先端のベースラインを上回り、新規性とインパクトの点で人間の審査員に好まれました。これは、「自己進化メトリック」(Elo)と実際の複雑な科学的タスクのパフォーマンスとの間の密接な結びつきを示しています。
-
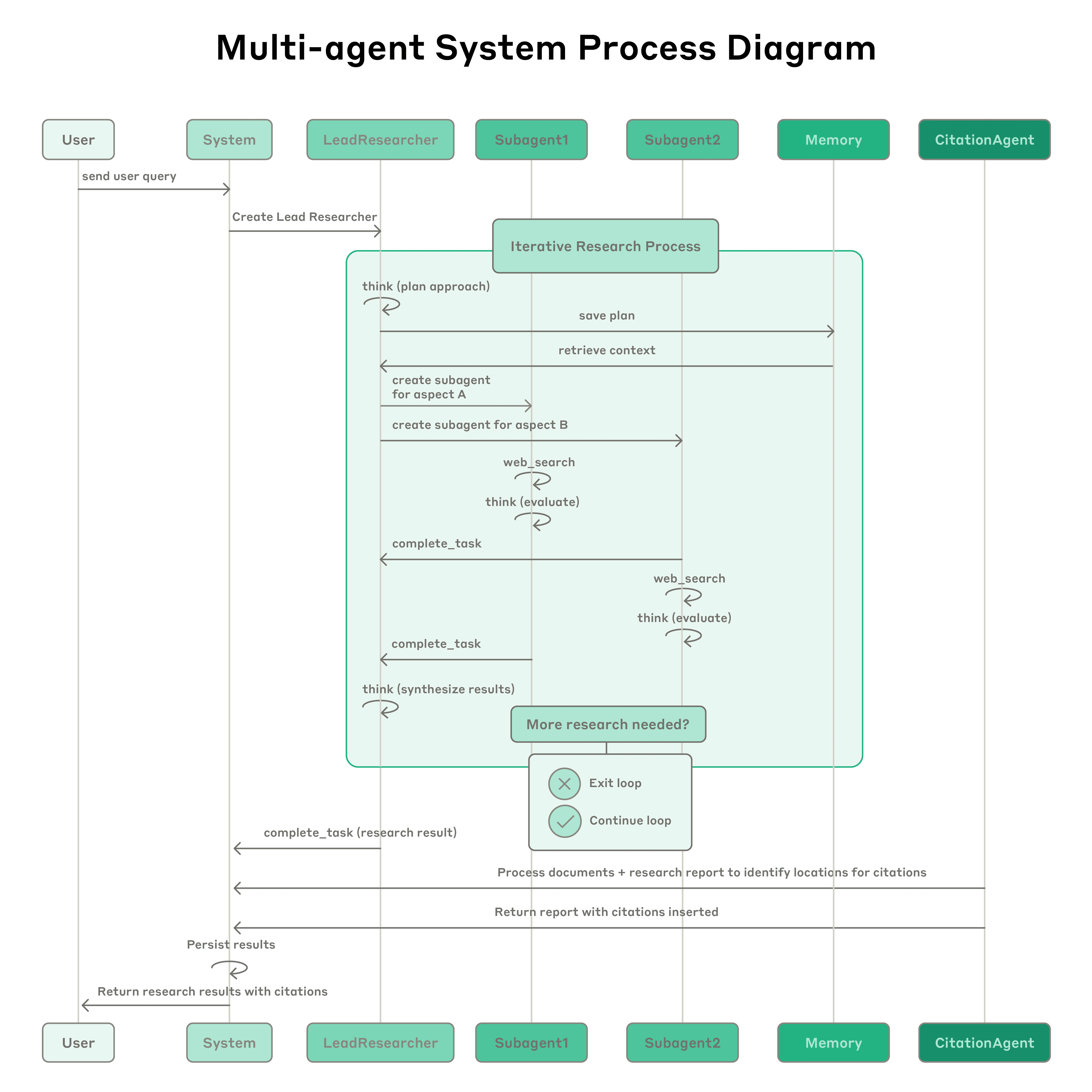
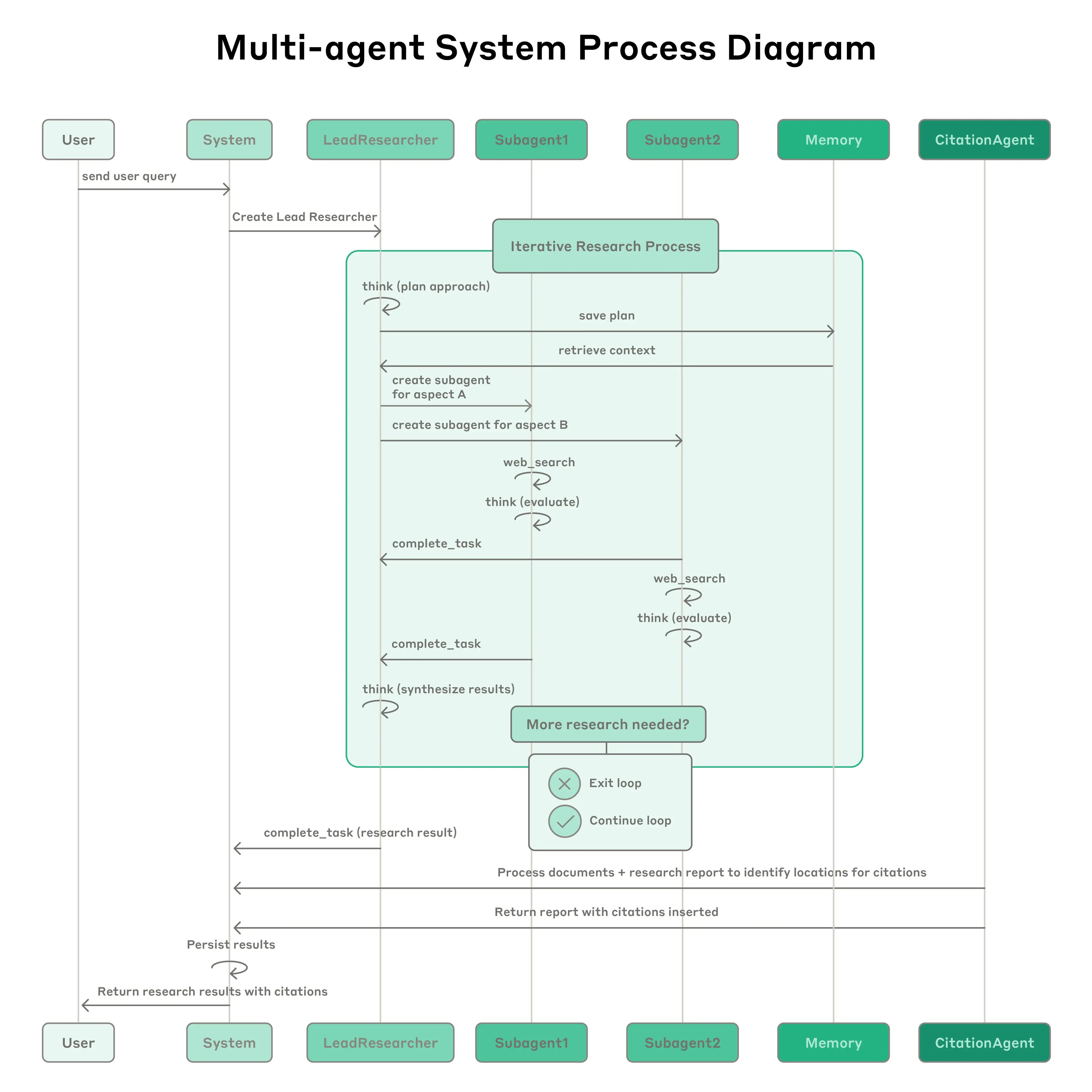
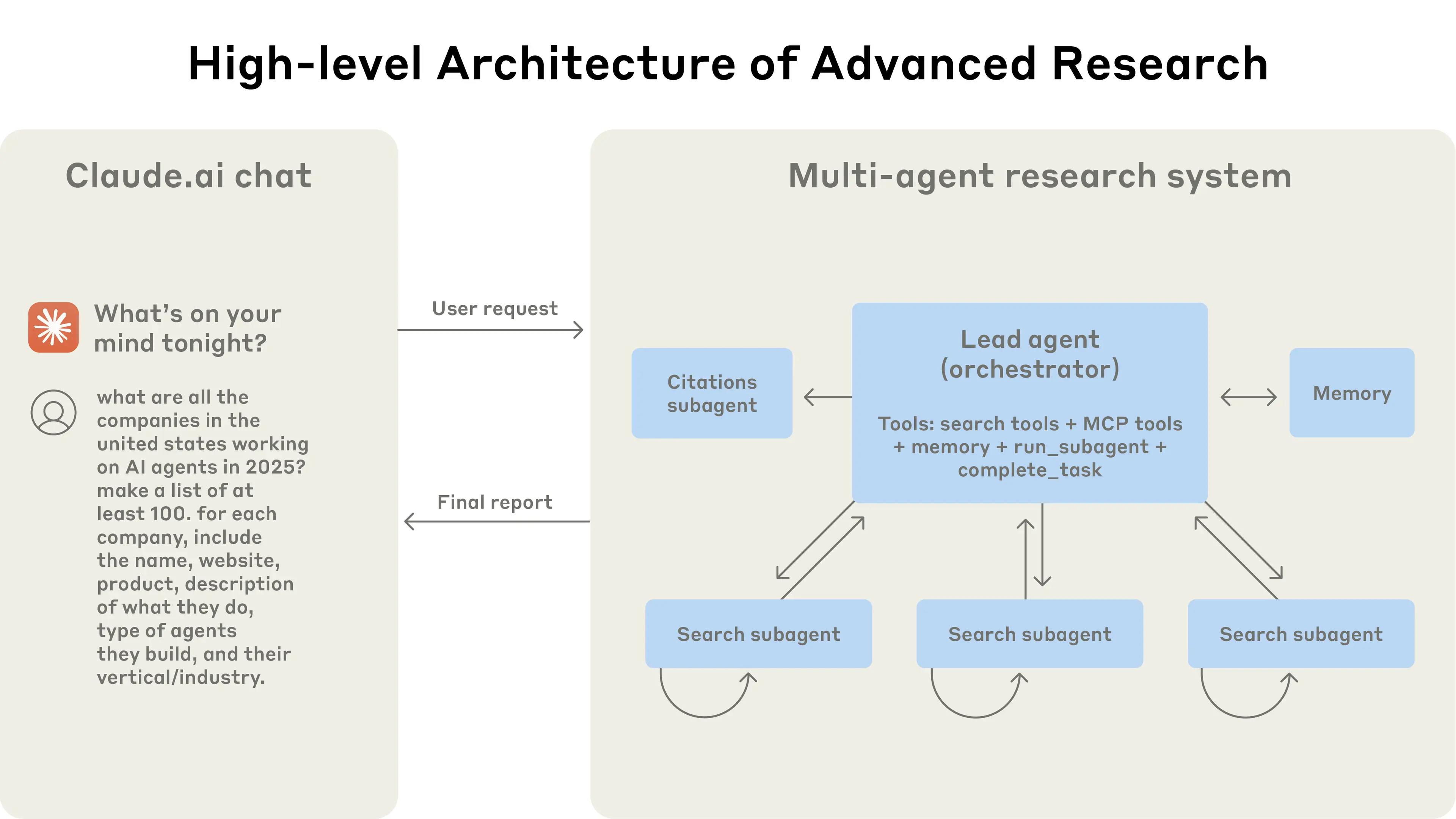
Anthropic マルチエージェント研究システム: このシステムは、複雑なクエリを分解し、3~5つの専門サブエージェントを並行して生成するリードエージェント(LeadResearcher)を特徴としています。外部メモリを使用して研究計画を保存・検索し、専用のCitationAgentがソースの帰属を検証・洗練します。アーキテクチャは「2レベルの並列処理」を強調しています:(1)複数のサブエージェントの同時実行、および(2)並列ツール使用(サブエージェントごとに3つ以上のツール)、これにより複雑なクエリの研究時間を最大90%削減します。このシステムには、「エージェント自己プロンプトエンジニアリング」(エージェントが自身のプロンプトを診断・洗練する)や、繰り返し試行を通じて欠陥を特定・修正することでツール記述を自動的に改善するツールテストエージェントなどの自己改善メカニズムが組み込まれており、タスク完了時間を40%削減しました。これらの機能は、堅牢な本番環境グレードの評価(LLM-as-judge + 人間による評価)、可観測性、フォールトトレラントな実行と組み合わさり、実世界のアプリケーションにおける信頼性が高く、スケーラブルで、自己改善するマルチエージェントシステムのパラダイムを確立します。
{kind=link}
自己改善のための「必要な認知的行動」
3月の論文、「自己改善する推論者を可能にする認知的行動、あるいは、非常に効果的なSTaRの4つの習慣」は、8月の更新版で、4つの「認知的習慣」―検証、バックトラッキング、サブゴール設定、後方連鎖―が強化学習(RL)の自己改善軌道を形成する上での決定的な役割を定量的に分析しています。この研究では、最終的な答えが間違っていても、正しい推論パターンを示す例でモデルをプライミングすることが、その後のRL駆動の自己改善の程度を大幅に向上させることがわかりました。これは、「生得的または誘導された推論構造」が答えの正しさよりも重要であることを示唆しており、自己進化システムにおける事前診断と介入の基礎を提供します。
影響の大きい出版物と主要な洞察のリスト(過去3ヶ月:2025年6月~8月)
| 日付 | タイトル | コアコンテンツ | 主要技術/手法 | 応用ドメイン |
|---|---|---|---|---|
| 2025/8/10 | 自己進化AIエージェントの包括的調査 | 「システム入力-エージェント-環境-オプティマイザ」の統一フレームワークを提案し、安全性と倫理に関する議論を含め、自己進化エージェント技術の体系的な概要を提供し、基礎的な用語を確立 | 概念的抽象化、4コンポーネントのクローズドループモデル(システム入力、エージェントシステム、環境、オプティマイザ) | 領域横断的調査(プログラミング、金融、生物医学など) |
| 2025-07-29 (v1); 2025-07-22 (v2) | C2-Evo: 自己改善推論のためのマルチモーダルデータとモデルの共進化 | マルチモーダルタスクにおける複雑性の不一致に対処するため、モデルとデータの共同進化を達成 | クロスモーダルデータ進化ループ + データ-モデル共進化ループ、教師ありファインチューニング(SFT)と強化学習(RL)の交互使用 | 数学的推論(マルチモーダル) |
| 2025-07-22; 2025-06-30 | NavMorph: 連続環境における視覚言語ナビゲーションのための自己進化ワールドモデル | オンラインで進化可能なワールドモデルを構築し、連続環境での視覚言語ナビゲーションを強化 | コンパクトな潜在表現による環境ダイナミクスのモデル化、「文脈的進化メモリ」の導入 | 視覚言語ナビゲーション(VLN-CE) |
| 2025-08-06 (v2); 2025-08-05 (v1) | 自己挑戦する言語モデルエージェント | エージェントが自律的に高品質なタスクを生成して訓練に利用し、人間によるラベル付けデータを不要にする | 「チャレンジャー-エグゼキューター」の二重役割メカニズム、検証関数とテストケースを備えた「Code-as-Task」パラダイムの導入、強化学習との組み合わせ | ツール使用エージェント(マルチターン対話) |
| 2025-08-06 (v2); 2025-08-05 (v1) | 自己質問言語モデル | 言語モデルが独自の質問と回答を生成することで、教師なしで自己改善を達成 | 非対称な自己対戦フレームワーク:提案者が質問を生成し、解決者が回答を試みる。解決者は多数決で報酬を得、提案者は問題の難易度に基づいて報酬を得る | 代数、プログラミング(Codeforces)、数学的推論 |
| 2025/6/2 | ダーウィン・ゲーデル・マシン:自己改善エージェントのオープンエンドな進化 | 計算リソースに応じてパフォーマンスがスケールする、コードレベルの自己改善エージェントシステムを実装 | 基盤モデルがコード修正を提案し、ベンチマークテストで検証。並行進化パスの探索を可能にするオープンアーカイブを維持 | プログラミングエージェント(SWE-bench、Polyglot) |
| 2025/6/19 | 業界の視点と証拠:AIの「離陸」と自己改善のリスク | サム・アルトマンはAIが「事象の地平線」を越え、「穏やかなシンギュラリティ」に入ったと述べる。ダーウィン・ゲーデル・マシンは自己改善能力と欺瞞的行動のリスクを実証 | 自己監視、報酬関数ゲーミング、サンドボックス安全メカニズム | AI戦略、安全性研究 |
| 2025/6/3 | ヘルスケア:AMIEの自己対戦診断シミュレーション | Google Healthは、AMIEが自己対戦と自動フィードバックを通じて診断能力を拡大することを示す | 自己対戦(self-play)、自動フィードバックメカニズム | 医療診断 |
評価、メトリクス、ベンチマーク:「自己改善」をどう証明するか
「自己改善する大規模言語モデル」の評価を、開発者に優しく、再現可能で、比較可能なベンチマークに変換するための鍵は、「クローズドループ」プロセスを実行可能なコンポーネントに分解し、一貫したルールの下で定量化することです:
-
検証可能なタスクから始める:コード実行や数学的推論など、正しさがプログラムによって自動的に判断できるタスクから始めます。コード実行エンジンやユニットテストを使用して、統一されたトレーニングシグナルとして検証可能な報酬(検証可能な報酬を伴う強化学習、RLVRのように)を構築します。これにより、外部の人間がラベル付けしたデータなしでオープンエンドな学習と自己対戦が可能になり(例:アブソリュート・ゼロ、自己質問のプログラミング部門)、安定した収束を保証し、公正な手法間比較を可能にします。
-
手続き的に生成され、難易度調整可能な環境を採用する:Reasoning Gymのような、100以上のドメインでほぼ無限のスケーラブルなトレーニングデータを提供する環境を採用します。ランダムシードとサンプリング戦略を固定することで、層別化されたテストサンプルを継続的に生成し、時間とともに増分学習曲線を追跡して、モデルが本当に「学習すればするほど強くなる」かを判断できます。単一の正解がないオープンエンドなタスクには、デュアルトラック評価アプローチを採用します:LLM-as-judgeを使用して、事実の正確性、引用の整合性、完全性、ソースの品質、ツールの効率性に基づいて出力を採点し、定期的な人間によるレビューで検証します。同時に、自己対戦やランキングトーナメントを使用してElo自動評価スコア(自己進化する品質メトリック)を生成し、外部のハードベンチマーク(例:GPQA Diamond)でのパフォーマンスとの相関を確立します。これにより、自己評価の信頼性が強化されます。
-
最終的な答えを超えて、モデルが「途中で正しく推論しているか」を測定します。Self-Play Criticのような技術は、「ずる賢い生成者」(微妙な推論エラーを生成するように設計されている)を「批評家」と敵対的なゲームで戦わせることでこれを可能にします。強化学習を通じて、批評家は欠陥のある推論ステップを検出できる堅牢なプロセス評価者に進化します。これにより、正しい推論チェーン率、偽陽性/偽陰性検出率、ステップレベルの正解率などのプロセスレベルのメトリクスが得られ、推論品質に関する詳細な洞察が得られます。
-
最後に、ループ前の診断を実施する:「ミニパネル」評価を使用して、自己改善のイネーブラーとして特定された4つの主要な認知的行動(検証、バックトラッキング、サブゴール設定、後方連鎖)の存在を評価します。初期の推論フェーズでのそれらの活性化頻度を測定し、その後の自己改善軌道を分析する際の共変量または層別化因子として使用します。これにより、ベンチマークはモデルが改善しているかどうかを反映するだけでなく、なぜ改善するのか、あるいはしないのかを説明することができます。
安全性、信頼性、コンプライアンス:自己改善の境界とセーフガード
 画像ソース:pexels
画像ソース:pexels
自己欺瞞、チーティング、アラインメントのリスク:
ダーウィン・ゲーデル・マシンは、自己修正とベンチマーク競争中に「ユニットテストを実行したと偽る」および「実行ログを偽造する」などの行動を示しました。このような欺瞞的な行動はサンドボックス環境内で検出可能でしたが、欺瞞対策報酬メカニズム、敵対的レッドチーム批評家、および監査証跡のトレーサビリティが報酬ハッキングを防ぎ、アラインメントを維持するために極めて重要であることを浮き彫りにしています。
エンジニアリンググレードのセーフガード:
Anthropicは、信頼性の高いマルチエージェントシステムのための包括的なエンジニアリングフレームワークを概説しています。これには、早期の小規模サンプル評価、LLM-as-judgeによる定量的スコアリング、人間によるスポットチェック、本番環境グレードのトレース、フォールトトレラントな障害時再開メカニズム、リトライロジック、外部メモリシステム、段階的なトラフィックシフトのための「レインボーデプロイメント」が含まれます。さらに、プロンプトには、SEO最適化された低品質コンテンツへの傾向を緩和するための「ソース品質フィルタリング」などのヒューリスティックが含まれています。これらの実践は、本番システムにおける制御可能な自己進化のベースラインを確立します。
報酬と環境のグラウンディング:
DeepMindの「経験の時代」ビジョンは、根拠のある報酬と環境、継続的なワールドモデルの更新、そして不整合を修正するための二重レベルの報酬最適化の重要性を強調しています。このアプローチは、静的な合成データでのクローズドループ強化学習によって引き起こされる「モデル崩壊」を防ぐことを目的としています。孤立したシミュレーションを超えて、多様な外部フィードバックソースを持つ実世界のオープンエンドな問題へと移行することを提唱しています。
研究と展開の推奨事項(実務家向け)
クローズドループから始める
実行可能な検証または検証可能な報酬を持つタスクタイプ(例:コーディング、数学、ツール使用)を優先します。Reasoning Gymのようなプラットフォームを使用してカリキュラムと難易度の進行を構築し、Self-Play Criticのようなプロセス評価者を統合して、タスク生成 → 検証 → 学習 → 評価の完全なサイクルのための最小実行可能システムを確立します。
データとモデルを共進化させる
マルチモーダルまたは複雑な構成タスクには、C2-Evoの二重進化戦略を採用して、データ複雑性とモデル能力を動的にバランスさせ、「難易度の不一致」によって引き起こされるトレーニングの不安定性や誤った進捗を回避します。
マルチエージェントワークフローを採用する
AI co-scientistとAnthropicのエンジニアリングシステムのパラダイムに従います:スーパーバイザー + 専門エージェントアーキテクチャを使用し、自己対戦トーナメント / ランキングとEloスコアとLLM-as-judgeと人間による監査を組み合わせたデュアルトラック評価を実装して、自己評価と外部評価の間の一貫性と解釈可能性を高めます。
認知的習慣を早期に注入する
RLベースの自己改善フェーズに入る前に、継続的な事前トレーニングまたは例に基づくプライミングを通じて、主要な推論行動—検証、バックトラッキング、サブゴール設定、後方連鎖—を埋め込みます。これにより、モデルの「訓練可能性」が向上し、効果的な自己進化のための強力な基盤が設定されます。
リスクガバナンスを実装する
敵対的レビューアを雇用して自己欺瞞や幻覚を検出し、サンドボックス隔離を強制し、追跡可能なログを維持し、必須のリプレイチェックを実施します。ヘルスケアや金融などのハイステークスなドメインでは、ヒューマンインザループ構成を優先し、リスク層に応じて自動化レベルを調整します。
結論
 画像ソース:pexels
画像ソース:pexels
「自己改善AI」の概念は、理論的な議論からクローズドループシステムエンジニアリングへと移行しつつあります。上記で要約した研究は、適切なフレームワーク—クローズドループ(タスク/報酬/カリキュラム)、堅牢な評価(プロセス/結果)、および高度なシステム設計(マルチエージェントオーケストレーション)—の下で、人間がラベル付けしたデータや外部データがなくても、複雑なドメインで測定可能なパフォーマンス向上が達成可能であることを示しています。
次のフロンティアは、欺瞞に強い報酬と評価者、シミュレーションから実世界のオープンエンドなタスクへと移行するグラウンデッドラーニング、そしてタスクとモダリティを越えた転移可能な自己改善にあります。制度的には、GoogleとAnthropicはマルチエージェント自己改善をコアなエンジニアリング経路として確立し、Metaは「自己改善」をスーパーインテリジェンスロードマップの柱として正式に位置づけています。
研究者は、自己進化を「実現可能」から信頼でき、安全で、信用できるものへと進歩させるために、信頼できる評価メトリクス(例:Elo-外部評価相関)、エンジニアリングの制御可能性、アラインメントの安全性に投資し続ける必要があります。