RAG:高リスクシナリオにおけるAIエージェントの精度問題を解決
2025年9月22日Ruixi @puppyone
AIエージェントは企業のワークフローを自動化する大きな可能性を秘めていますが、大規模言語モデル(LLM)固有の不安定さは、金融、法律、医療などの高度に規制された業界で重大なリスクをもたらします。たった1つの不正確な出力が、深刻な法的または財務的な結果を引き起こす可能性があります。
AI主導のリスクを体系的に管理し、ビジネス価値を引き出すために、リーダーはまず、さまざまなユースケースの精度要件を評価するための明確なフレームワークを必要とします。以下の「AIユースケース精度ティア」フレームワークは、必要な精度とリスク許容度に基づいてAIアプリケーションを分類します。

| 精度ティア | 要求精度 | 代表的なユースケース | 潜在的リスク |
|---|---|---|---|
| ティア1:ゼロトレランス | 99.9%+ | 医療診断、法的コンプライアンス、金融信用承認、AML | 壊滅的な法的、財務的、または安全上のリスク |
| ティア2:ハイステークス | 90-99% | 複雑な顧客サポート、社内ナレッジマネジメント、引受リスク評価 | 重大な事業損失、顧客離反、コンプライアンス問題 |
| ティア3:文脈的信頼性 | 75-90% | 標準的な顧客サービスチャットボット、市場動向分析、Q&Aシステム | 劣悪なユーザーエクスペリエンス、業務非効率 |
| ティア4:創造的・探索的 | 0-75% | コンテンツ生成、ブレインストーミング、パーソナルアシスタント | 低品質または使用不能な出力 |
AIの不正確さがもたらすビジネスコスト:リスクの定量化
AIの不正確さはもはや単なる技術的な問題ではなく、経営陣の監督を必要とする主要なシステミックリスクです。その深刻なビジネスへの影響を理解するためには、コストを定量化する必要があります。
財務的影響
- 674億ドル - 2024年にAIの「幻覚」に起因する全世界の損失(AllAboutAI 2025年調査)
- 企業のAIユーザーの**ほぼ50%**が、不正確な可能性のあるAI生成コンテンツに基づいて重大なビジネス上の意思決定を行ったことを認めた
運用コスト
- **平均22%**のチーム効率低下 - AI出力の手動検証による(ボストン・コンサルティング・グループ 2025年)
- 従業員1人あたり年間14,200ドル - 幻覚緩和策のコスト(フォレスター・リサーチ)
戦略的テクノロジーの選択:RAG vs. ファインチューニング
ティア1およびティア2のユースケースを実現するためには、AIエージェントは間違いなく信頼できる知識源を持つ必要があります。Retrieval-Augmented Generation(RAG)とファインチューニングは、これを達成するための2つの主要な方法です。
| 決定要因 | Retrieval-Augmented Generation (RAG) | ファインチューニング |
|---|---|---|
| カスタマイズ方法 | 取得した外部ドキュメントをプロンプトに注入 | モデルの重みを更新して知識を内在化 |
| データの鮮度 | リアルタイム;新しい情報に即座に適応 | 静的;知識はトレーニング時に凍結 |
| 展開速度 | 非常に速い(数時間から数日) | 遅い(数週間から数ヶ月) |
| 説明可能性/監査可能性 | 高い;出典を引用し、証拠の追跡を提供可能 | 低い;「ブラックボックス」として動作 |
| データセキュリティ | 高い;機密データは隔離されたまま | 低い;潜在的なデータ漏洩ベクトル |
| ビジネスインパクト | 迅速な価値実現時間、迅速なパイロットに最適 | 高い初期投資、長い展開サイクル |
RAGのコアメカニズム
RAGシステムは、情報検索と生成を強力に組み合わせます。そのワークフローは通常、以下の手順に従います:
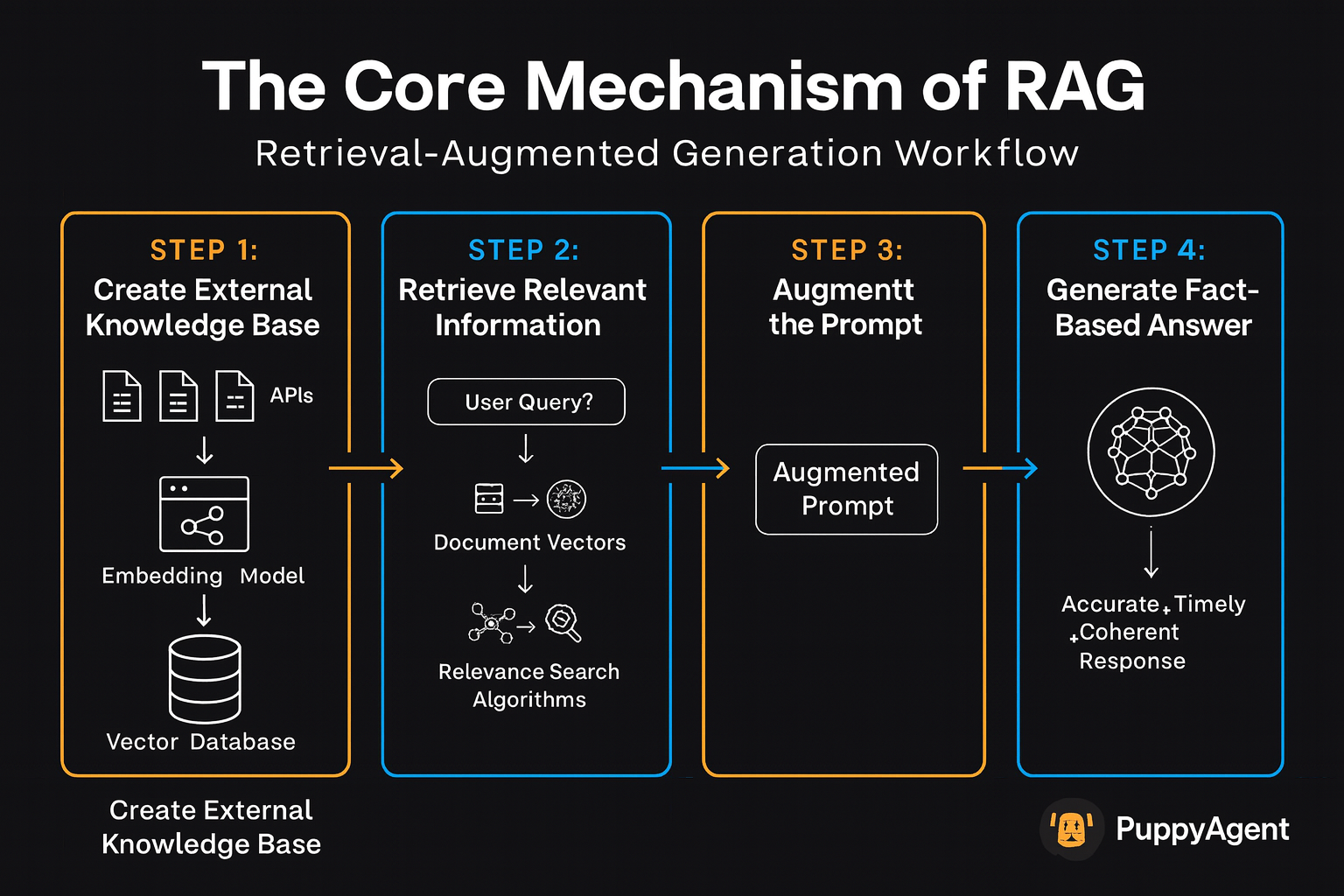
RAGワークフローの手順:
- 外部ナレッジベースの作成 - 独自のデータを検索可能なベクトルに変換
- 関連情報の取得 - ユーザーのクエリをナレッジベースと照合
- プロンプトの拡張 - 取得した情報を元のクエリと統合
- 事実に基づいた回答の生成 - LLMが正確でタイムリーな応答を生成
エンタープライズグレードのRAGアーキテクチャの構築
エンタープライズの文脈では、成功はデータと検索パイプラインの厳密なエンジニアリングによって決まります。
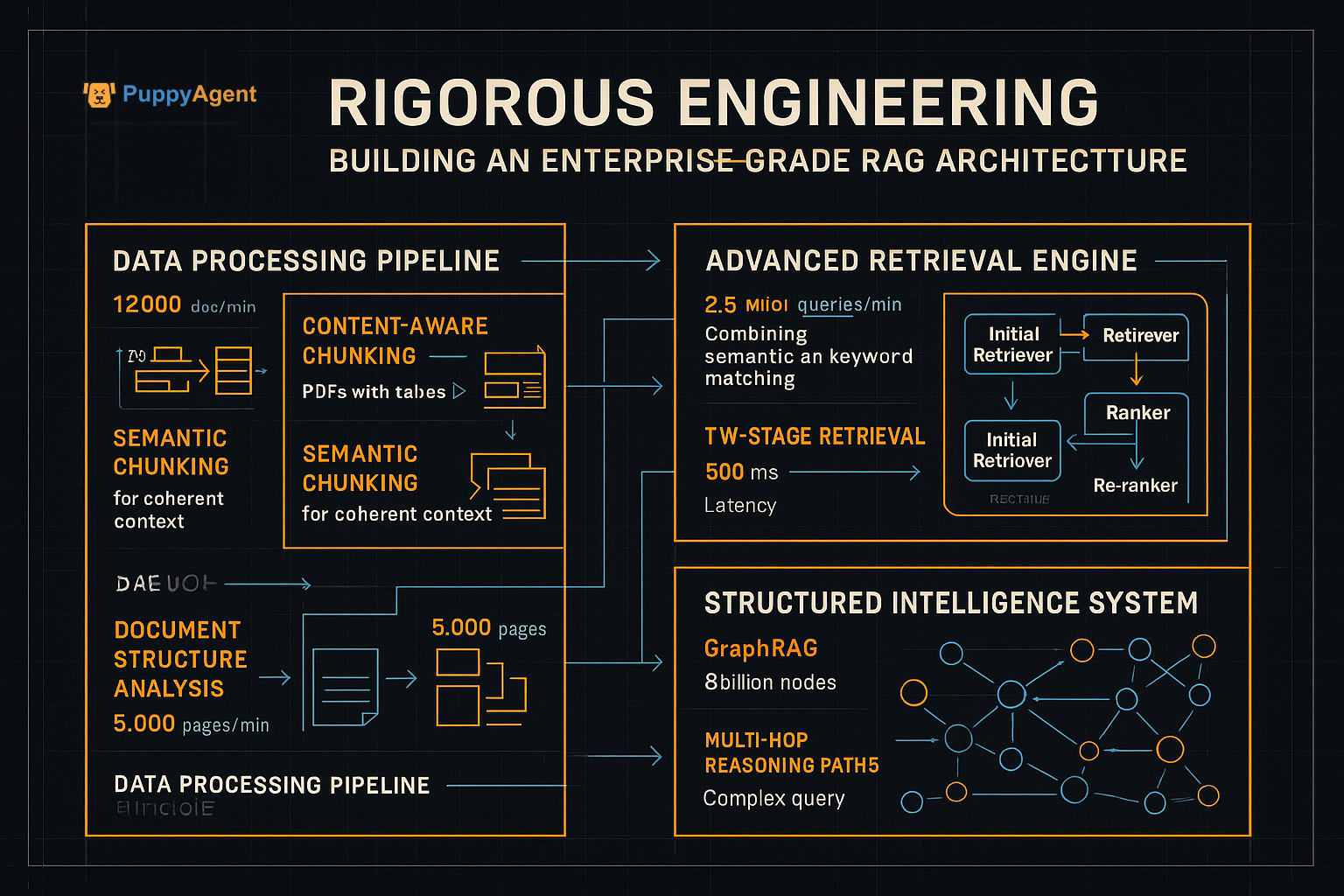
主要なエンジニアリング上の考慮事項:
データ中心の基盤
- RAGの成功の80%はデータ品質に依存
- 複雑なドキュメントのためのコンテンツ認識チャンキング
- 一貫したコンテキストを保持するためのセマンティックチャンキング
高度な検索戦略
- キーワードとベクトルアプローチを組み合わせたハイブリッド検索
- 再ランク付け最適化を伴う2段階検索
- GraphRAG for structured data and multi-hop reasoning
定量化可能なビジネス価値:実際のケーススタディ
業務効率と生産性
- フォーチュン500の製造業者:顧客サービスの応答時間を5分以上から10〜30秒に短縮
- サービス担当者からの90%が5つ星評価
- ティア1の自動車メーカー:技術者の初回修理率が25%向上
規制業界での成功
- Precina Health:糖尿病患者のA1cレベルが**月あたり1%**低下(標準治療の12倍速)
- HIPAA準拠の医療AI展開
ナレッジマネジメント
- Bell電気通信:従業員が最新のポリシーにアクセスできることを保証
- LinkedIn:平均問題解決時間が28.6%削減
Puppyone:AIエージェント向けエンタープライズナレッジプラットフォーム
puppyoneは、エンタープライズグレードのRAGパイプラインを構築するために特別に設計されており、複雑なエンジニアリングの課題を抽象化します。
コアバリュープロポジション:
迅速なプロトタイピング
- データ準備のための直感的なインターフェース
- 「自作」の複雑さを解決
柔軟な展開
- チャットボット、API、ウェブサイトウィジェットをサポート
- シームレスなITアーキテクチャ統合
高度なテクノロジー
- 最先端のRAG技術を内蔵
- 高度なユースケースの課題に対応
セキュリティとコンプライアンス
- エンタープライズグレードのセキュリティ
- 監査のための透明な証拠の追跡
結論:確率と確実性のギャップを埋める
汎用LLMの確率的な性質と、ハイステークスな業界の決定論的なニーズとの間には、大きな隔たりが存在します。RAGは、検証可能で外部の真実のソースをLLMに提供することで、この隔たりを埋めます。
AIエージェントの将来の価値は、単なるモデルの能力だけでなく、信頼性、検証可能性、セキュリティによって決まります。puppyoneは、企業が重要なリスクを管理しながら、真のビジネス価値を提供する安全でインテリジェントなAIシステムを構築するための信頼できるプラットフォームを提供します。