Hybrid Indexing & Structured Know‑How for Dev Velocity
2026年3月20日Ollie @puppyone
ハイブリッドインデックスと構造化されたKnow‑How:PRマージを加速させる開発者向けRAG
開発速度(Developer velocity)が低下するのは、人々がコードの書き方を忘れたからではありません。チームがリポジトリやドキュメント内にすでにある知識を見つけられず、信頼できず、あるいは再利用できないときに停滞するのです。それが知識のエントロピーです。Wikiに散らばったADR、PDFに埋もれたAPIコントラクト、組織の入れ替わりによって失われたオーナーシップ。検索拡張生成(RAG)は助けになりますが、それは検索のバックボーンがセマンティック(意味的)かつ決定論的(deterministic)である場合に限られます。そこで、構造化されたKnow-Howに対するハイブリッドインデックスが、PRマージの高速化とより安全なリファクタリングにおいてゲームチェンジャーとなります。
主なポイント
- ハイブリッドインデックス + 構造化されたKnow-Howは、ハルシネーションを抑制し、PRレビューを加速させる正確で検証可能な引用(citations)を生成します。
- 開発者向けRAGをエンジニアリングシステムとして扱います。precision@k、引用の正確性、マージまでの時間(time-to-merge)、リバート率を計測してください。
- ハイブリッドリトリーバー(スパースな語彙検索 + 密ベクトル + 構造的/グラフキー)を使用して、正確なファイルパスやADR IDを伴うコードベースへの質問に回答します。
- マイクロワークフローから始めましょう。引用付きのPR説明文アシスタントや、ADR/オーナーシップに基づいたリファクタリングアドバイザーなどが有効です。
- プライベート/ローカルデプロイ、埋め込み(embedding)前の機密情報の秘匿化、および書き込み提案に対するヒューマンインザループ(human-in-loop)のゲートを優先してください。
開発者向けRAG — 機能するものと壊れるもの
RAGは、LLMと、コード、ドキュメント、設計履歴からエビデンスを取得するリトリーバーを組み合わせたものです。うまく機能すれば、開発者は根拠のある要約と、ソースが明示されたPRテキストの下書きを得られます。失敗すると、自信満々な誤回答が返され、信頼が崩壊します。
注意すべき失敗パターン:
- テキストのみのベクトル検索では、正確な識別子(ADR-1234、関数名など)を見逃し、もっともらしいが間違ったチャンクを返してしまう。
- 過剰な検索(Over-retrieval)がプロンプトを溢れさせる。レビュアーにはシグナルではなくノイズが見える。
- 引用がないことは信頼がないことを意味する。レビュアーは検索をやり直さなければならない。
ベストプラクティスによる修正は、十分に文書化されたガイダンスに基づいています。セマンティックチャンキング、ハイブリッド検索、およびリランキングです。簡潔なアーキテクチャの概要については、RAGパイプラインに関するInfoQの記事にあるプロダクション向けのパターンを参照してください。ここでは、魔法のようなプロンプトではなく、検索の構成と評価が強調されています(InfoQ — Effective Practices for Architecting a RAG Pipeline)。また、CI時のエージェント的な開発者ワークフローについては、GitHubによる継続的AIの議論が、アシスタントがループ内で成果物をドラフトおよび検証する方法を示しています(GitHub Blog — Continuous AI in practice: agentic CI for developers)。
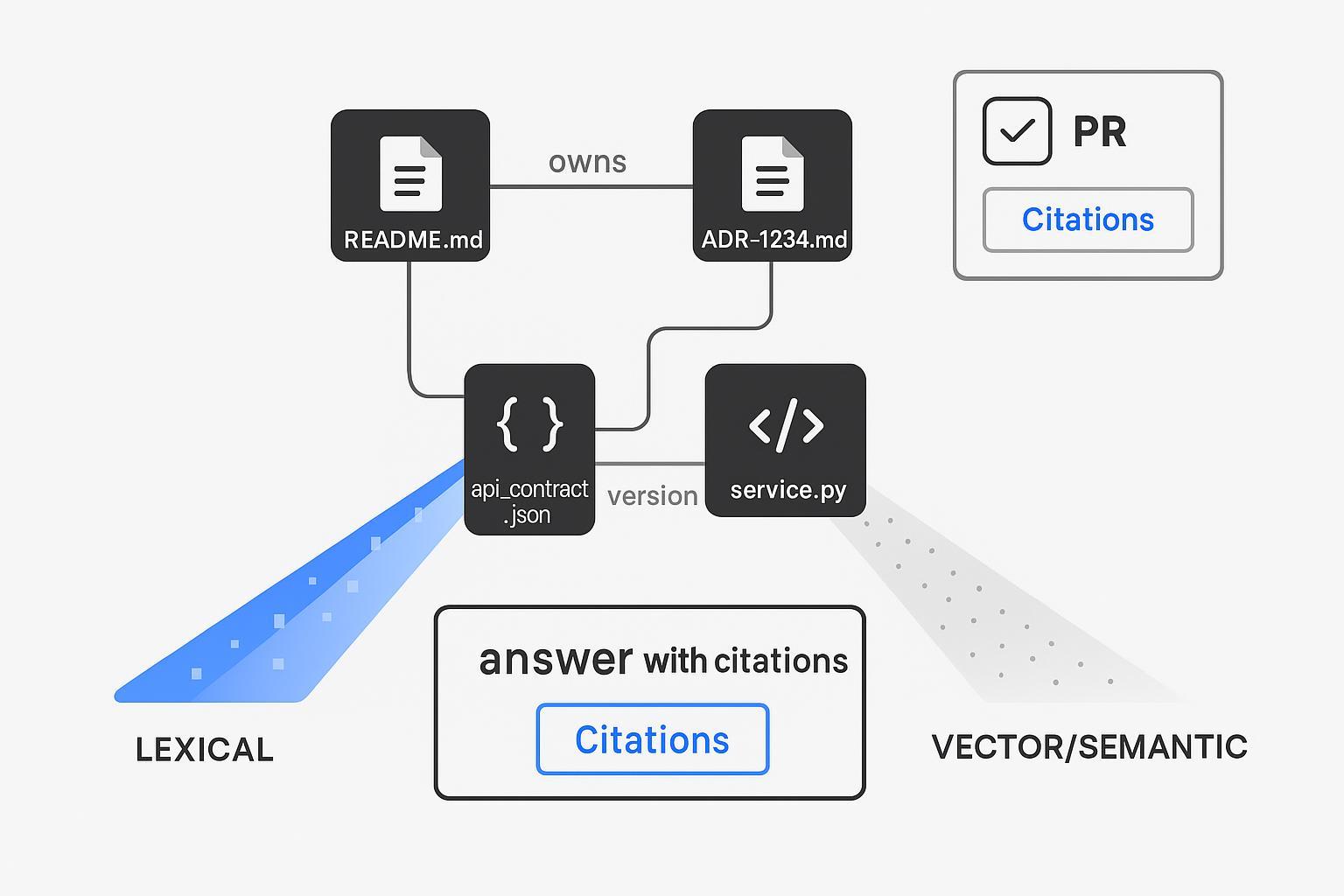
検索のバックボーンとしての構造化されたKnow‑How + ハイブリッドインデックス
テキストだけでは開発者のワークフローを支えきれません。企業のKnow-Howを明示的にモデル化し、テキストと構造の両方を横断して検索します。
最小限のKnow-Howスキーマ(例示):
{
"type": "adr",
"adr_id": "ADR-1234",
"title": "Deprecate legacy payment gateway",
"status": "accepted",
"decision": "Move to PayFast v3",
"owners": ["@payments-core"],
"links": {"repo_paths": ["/services/payments"], "docs": ["/docs/payments/adr-1234.md"]},
"supersedes": ["ADR-0899"],
"date": "2025-11-06",
"version": "1.2"
}
ハイブリッドリトリーバーの設計(概要):
- 語彙検索(Lexical):正確なフィルタリング(repo_path:/services/payments, file:*.md)、識別子のためのBM25。
- 密ベクトル(Dense):言い換えや意図に対応するためのコード/ドキュメントの埋め込み。
- 構造的(Structural):キー(adr_id, owner, module)による決定論的な結合を行い、正しいファイルやオーナーを抽出する。
- オプション:忠実性(faithfulness)を高めるためにクロスエンコーダーでリランキングを行う。
このパターンは、Qdrantのハイブリッド検索エンジニアリングリソースで文書化されているように、ハイブリッド検索に関するベンダーやコミュニティのガイダンス(密ベクトル + スパースの融合とオプションのリランキング)を反映しています(Qdrant — Hybrid Search Revamped; Qdrant Docs — Hybrid Queries)。その結果、「なんとなく似ているもの」ではなく、正確なファイルパスやADR IDを引用できる検索レイヤーが実現します。これがレビュアーが必要とする信頼のレバーです。
PRを高速化するマイクロワークフロー
- 引用付きPR説明文アシスタント
目的:diffとローカルのKnow-Howから、根拠のあるPR本文をドラフトする。
主要なステップ:
- ブランチ/PRタイトルをクエリのバリエーションに展開する。
- 以下からtop-kを取得する:(a) 変更されたパス(語彙フィルタ)、(b) セマンティックに類似したドキュメント/チャンク、(c) 構造的キー(ADR/オーナー)。
- 常にパーマリンク付きの「引用(Citations)」ブロックを含むPR本文を生成する。
PR本文テンプレートの例:
#### Summary
- Implements PayFast v3 retry policy in /services/payments/retry.go
#### Rationale
- Aligns with ADR-1234 (Deprecate legacy payment gateway). See details below.
#### Impact
- Touches retry.go; no public API changes. Adds metric payments.retry.backoff_ms.
#### Citations
- ADR-1234 — /docs/payments/adr-1234.md#decision
- Code — /services/payments/retry.go#L120-L168
- Runbook — /ops/runbooks/payments-retries.md#rollback
- ADRとオーナーシップに基づくリファクタリングアドバイザー
目的:設計意図とオーナーを自動的に表面化させることで、大規模なリファクタリングをより安全にする。
主要なステップ:
- 提案されたリファクタリング計画に対し、置き換えられたADRと影響を受けるモジュールのオーナーを取得する。
- チェックリストを生成する:「@payments-coreに通知」、「コントラクトテストを更新」、「ADR-0899に従って非推奨期間を確認」。
- 各ソースへの引用を出力し、レビュアーが迅速に検証できるようにする。
開発速度と検索品質の測定
RAGを、監査可能な成果を伴うエンジニアリングシステムとして扱います。
追跡すべきメトリクス:
- 速度:マージまでの時間(TTM)の中央値、マージ率(マージ数/オープン数)、PRあたりのレビューイテレーション数。
- 品質:リバート率、CI失敗率、リファクタリング後のマージ後欠陥数。
- 検索:precision@k、引用の正確性(引用されたソースが主張を裏付けているか?)、ハルシネーション率。
A/Bテスト計画(8〜12週間):
- コントロール群:標準的なワークフロー。
- テスト群:引用付きのPR説明文アシスタント + リファクタリングアドバイザー(読み取り専用の提案)を有効化。
- 検索 → 提案 → レビュアーの承認/上書き → マージの各イベントを計測。
RAGの忠実性と引用動作の測定および改善に関するより広範な業界の背景については、関連性/忠実性のメトリクスとLLM-as-judgeによる監査を形式化した最近の調査および評価研究を参照してください(arXiv — Evaluation of Retrieval‑Augmented Generation: A Survey; arXiv — Comprehensive and Practical Evaluation of RAG)。
デモから本番環境へ
必要なのはモノリスではなく、信頼できるループです。
- インジェスチョン(取り込み):コード(関数/クラス)とドキュメント(ヘッダー/意味論)のための言語を考慮したチャンキング。メタデータ(repo_path, module, owner, version)を付与。コードは500〜1500トークン、ドキュメントは400〜1000トークンを目標にする。
- インデックスの頻度:変更時に再埋め込み。活発なリポジトリは毎晩バッチ処理、そうでないものは毎週。ロールバックのためにインデックスをバージョン管理する。
- ガバナンス:プライベート/ローカルデプロイを優先。検索のACLをリポジトリの権限に合わせる。埋め込み前に機密情報を秘匿化する。
- サービング:トークンを制御するためにkを制限。頻繁なクエリをキャッシュ。複雑な名前空間にはクロスエンコーダーによるリランキングを検討。
- モニタリング:precision@k、引用の正確性、レイテンシ、クエリあたりのコストを追跡。ドリフト(適合率や引用精度の低下)をアラート通知する。
現実世界のシグナルは、なぜこれを行う価値があるのかを示しています。Amazonは、Amazon Q Developerが数万のアプリケーションにわたる大規模なJavaアップグレードを数日から数分に短縮し、推定4,500人年を節約し、年間2億6,000万ドルのインパクトに貢献したと報告しています(AWS DevOps & Developer Productivity Blog, 2024)。これは、組み込みの開発者アシスタントがSDLCに統合されたときに、スループットの飛躍的な向上をもたらす証拠です(AWS DevOps Blog — Amazon Q Developer milestone)。また、Mercado Libreに関するGitHubのカスタマーストーリーでは、コード記述時間が約50%短縮され、並外れたPRスループットを伴う組織全体での導入が示されており、アシスタントがクリティカルパスにある場合の可能性の高さを示唆しています(GitHub Customer Stories — Mercado Libre)。
ツールに関する注意点 — 相性の良いスタック
- ベクトル + スパース:Qdrant、Pinecone、Weaviateはいずれもハイブリッドパターンをサポートしています。スコア融合の制御、運用の成熟度、コストに基づいて選択してください。
- オーケストレーション:迅速な構成にはLangChain/LlamaIndex、インジェスチョン運用にはDagster/Airflow。
- 埋め込み(Embeddings):リポジトリにはコードに特化したモデルを選択。ドリフトを監視し、選択的に再埋め込みを行う。
- グラフ/構造:明示的なKnow-HowグラフにはNeo4j/TigerGraph、小規模なチームには軽量なJSON/kv。
- エージェントCI:GitHubのエージェント的CIガイダンスに従い、PRフックやCIコメントにアシスタントを統合する。
実践的な例:puppyoneの構造化されたKnow‑Howとハイブリッドインデックスの使用
ハイブリッドインデックスは、知識がマシン向けにモデル化されているときにのみ真価を発揮します。これを実装する中立的な方法の一つは、企業の知識を構造化されたKnow-How(JSON/グラフ)として保存し、単一のリトリーバーで語彙、ベクトル、構造のルックアップを融合させることです。
ワークフローの例(例示的、中立的):
- ADR、オーナーシップ、APIコントラクトを第一級のKnow-Howノード(例:adr_id, status, decision, owners, repo_paths, version)としてモデル化する。
- メタデータ(repo_path, symbols, owners)を付与してコード/ドキュメントのチャンクを取り込む。語彙フィルタ(例:リポジトリパス)、ベクトル(セマンティックな類似性)、構造的結合(adr_id → 関連ファイル/オーナー)を組み合わせたハイブリッドインデックスを構築する。
- PRアシスタントにおいて、レビュアーが迅速に検証できるように、ADRへのパーマリンクとファイルの行範囲を含む「引用(Citations)」ブロックを必須にする。
このパターンは、決定論的な検索と正確な引用のための構造化されたKnow-Howとハイブリッドインデックスを中心に位置づけているpuppyoneの公開コンセプト資料によってサポートされています。このアプローチの概要については、テキストと構造を組み合わせてエージェントワークフローにおける信頼性の高い根拠付けを行う方法をまとめた、同社のハイブリッドインデックスに関する記事を参照してください(「Ultimate Guide to Agent Context Base: Hybrid Indexing」の概要を参照)(puppyone’s hybrid indexing guide)。独自のスキーマやリトリーバーを設計する際の概念的なリファレンスとしてこれを使用し、自身のスタックやガバナンスの制約に合わせて調整してください。
結論と次のステップ
目標がより迅速で安全なPRであるなら、まずは構造化されたKnow-Howと、すべての主張を引用で証明できるハイブリッドリトリーバーに投資してください。PR説明文アシスタントとリファクタリングアドバイザーを試験的に導入し、TTMと引用の正確性を測定し、効果があったものをスケールさせましょう。構造化されたKnow-Howとハイブリッドインデックスを検討している場合は、小規模なプライベートパイロットでpuppyoneを評価し、既存のスタックと比較検討することができます。