Model Context Protocol(MCP) 완벽 가이드
2026년 4월 3일Ollie @puppyone
Key takeaways
- MCP는 데이터 모델이나 거버넌스 레이어를 대체하지 않습니다. agent host가 tools, resources, prompts를 발견하고 호출하는 방식을 표준화합니다.
- 운영 환경에서의 핵심 질문은 "MCP냐 API냐"가 아니라, discovery, determinism, policy enforcement, auditability를 어떤 인터페이스가 맡을지입니다.
- 좋은 MCP 도입은 tool 책임을 좁히고, 안정적인 response envelope를 반환하며, read path와 write path를 분리합니다.
- Docker 하드닝, request tracing, structured logs는 prompt 품질만큼 중요합니다. 사고를 멈출 수 있는지, 나중에 재구성할 수 있는지를 결정하기 때문입니다.
- 문제가 "도구 연결"이 아니라 "하나의 governed context를 MCP, API, Skills로 중복 없이 배포하는 것"일 때 puppyone이 의미를 가집니다.
MCP의 실제 역할
많은 팀이 Model Context Protocol을 "AI 에이전트에 도구를 연결하는 표준" 정도로 이해합니다. 방향은 맞지만, 설계 판단에는 아직 거칠게 들립니다.
실무적으로 더 유용한 해석은 다음과 같습니다.
- MCP는 capability discovery를 표준화한다
- MCP는 capability invocation을 표준화한다
- MCP는 knowledge modeling, policy design, stable outputs를 대신 만들어주지 않는다
공식 사양은 MCP를 JSON-RPC 기반으로 tools, resources, prompts를 agent runtime에 노출하는 프로토콜로 설명합니다. Model Context Protocol specification, lifecycle, Anthropic의 announcement를 보면 맥락이 잘 잡힙니다.
하지만 MCP만으로는 해결되지 않습니다.
- 오래되었거나 서로 충돌하는 데이터
- 지나치게 넓은 tool boundary
- 약한 authorization
- 부족한 audit trail
- 모델이 추측해야 하는 불안정한 payload
그래서 성숙한 팀은 MCP를 "delivery protocol"로 취급하고, 전체 아키텍처의 답으로 과대평가하지 않습니다.
언제 MCP를 쓰고 언제 쓰지 말아야 하나
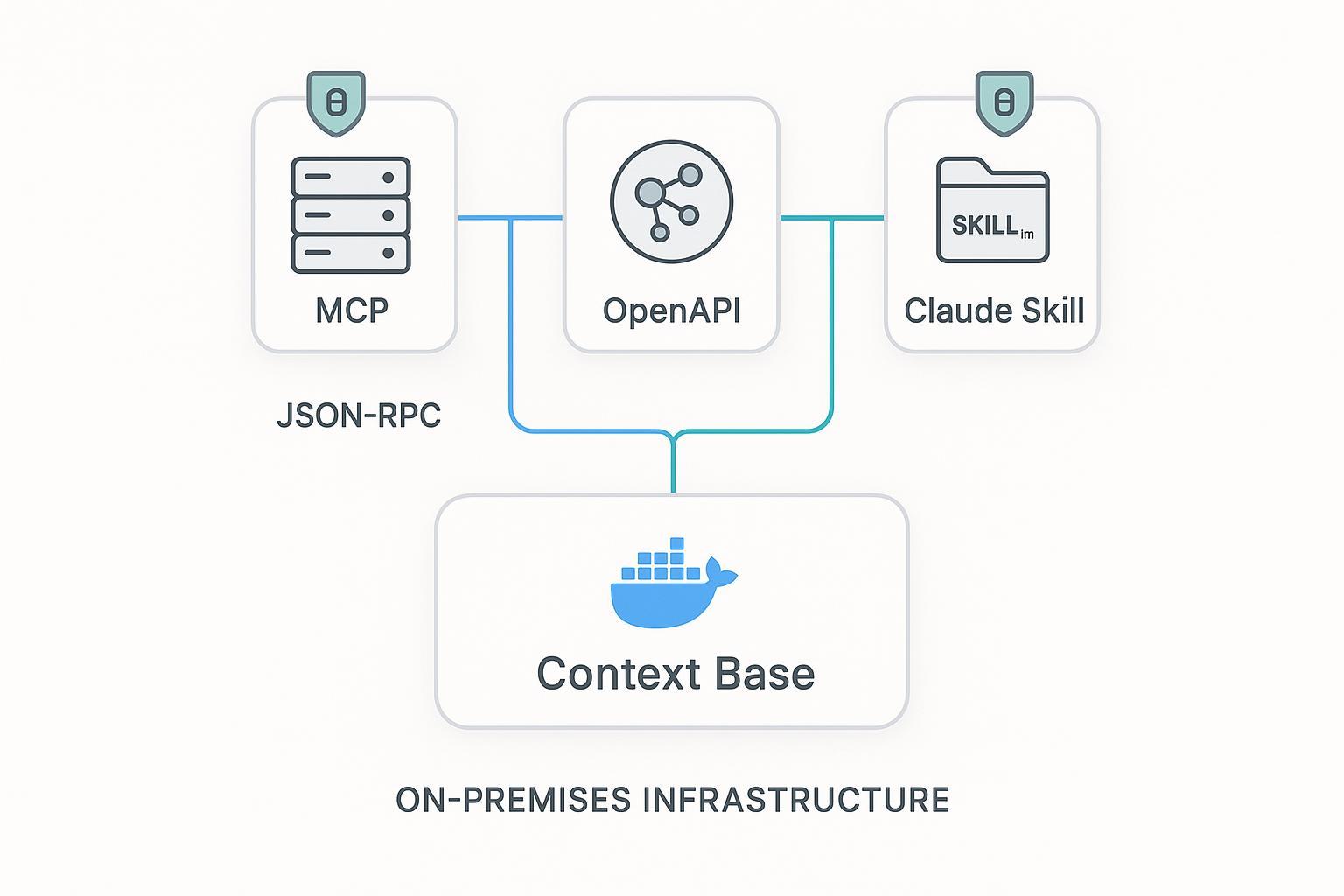
MCP가 새롭다는 이유만으로 모든 capability를 MCP로 감싸는 것은 흔한 과설계입니다. 실제로는 역할에 맞는 surface를 고르는 편이 낫습니다.
| Surface | 강점 | 약점 | 적합한 경우 |
|---|---|---|---|
| MCP server | discovery, agent-native execution, host interoperability | stable payload와 policy를 직접 설계해야 함 | caller가 agent host이고 tools/resources semantics를 활용할 수 있을 때 |
| REST API | deterministic contract, 성숙한 auth / cache / gateway | agent가 endpoint semantics를 이미 이해해야 함 | agent, app, internal service가 함께 재사용할 장기 계약이 필요할 때 |
| Skills | workflow instructions와 guardrails 배포 | live data plane에는 약함 | 절차와 운영 습관을 공유하고 runtime data는 MCP / API로 가져오고 싶을 때 |
실무에서 유용한 규칙은 다음과 같습니다.
- discovery-heavy capability는 MCP
- contract-heavy capability는 REST
- workflow-heavy knowledge는 Skills
즉 운영 환경에서는 MCP, REST, Skills를 함께 쓰는 구성이 자연스럽습니다.
puppyone으로 통제된 MCP 배포 보기Get started운영 환경에서 버티는 최소 MCP 설계
약한 MCP tool은 대개 "무엇이든 하는 큰 함수"가 됩니다. 강한 MCP tool은 책임이 좁고, 입력이 엄격하고, 출력이 안정적입니다.
기본 원칙은 다음과 같습니다.
- 1 tool = 1 job
- strict input schema
- stable output envelope
- data를 반환하기 전에 policy check
- trace 가능한 identifier 포함
import { McpServer } from "@modelcontextprotocol/sdk/server";
const server = new McpServer({ name: "org-context" });
server.tool(
"get_knowhow_item",
{
description: "Read one governed Know-How item by id",
inputSchema: {
type: "object",
properties: { id: { type: "string" } },
required: ["id"],
additionalProperties: false
}
},
async ({ id }, ctx) => {
const item = await ctx.store.read(id);
if (!ctx.policy.canRead(ctx.user, item.policyTag)) {
return {
ok: false,
error: { code: "forbidden", message: "Access not permitted" }
};
}
return {
ok: true,
data: {
id: item.id,
title: item.title,
version: item.version,
summary: ctx.redactor(item.summary)
},
trace: {
requestId: ctx.requestId,
policyTag: item.policyTag
}
};
}
);
핵심은 화려함이 아니라, 내부 시스템의 넓은 권한을 그대로 노출하지 않는 데 있습니다.
Docker 하드닝도 MCP 설계의 일부다
많은 MCP 튜토리얼은 "server가 실행됐다"에서 끝납니다. 하지만 그 server가 민감한 context를 읽고, internal tools를 호출하고, 경우에 따라 write action까지 한다면 그건 절반도 끝난 것이 아닙니다.
최소 하드닝 기준은 다음과 같습니다.
- non-root user로 실행
- 가능하면 read-only filesystem 사용
- secret은 image에 bake하지 말고 file mount
- health check 추가
- network egress 제한
- request마다 correlation ID 부여
Docker 문서의 HEALTHCHECK, Compose healthchecks, rootless tips, bind mounts는 그대로 적용 가능한 참고 자료입니다.
FROM node:22-slim AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci --ignore-scripts
COPY . .
RUN npm run build && npm prune --omit=dev
FROM gcr.io/distroless/nodejs22-debian12:nonroot
WORKDIR /app
COPY --from=build /app/dist ./dist
USER 65532:65532
ENV NODE_ENV=production
CMD ["/nodejs/bin/node", "dist/server.js"]
로컬 실행이든 온프레미스든, runtime boundary가 분명하지 않으면 trustworthy한 시스템이 되지 못합니다.
왜 versioned REST API가 여전히 필요한가
MCP는 agent-native execution에 강하지만, REST API도 여전히 분명한 역할이 있습니다.
- explicit versioning
- stable pagination과 filter semantics
- gateway-native auth, rate limit, cache
- agent 외 소비자와의 재사용성
그래서 많은 팀이 같은 governed context를 MCP와 REST 양쪽으로 노출합니다. Azure Architecture Center의 API design guidance는 여전히 유효하고, RFC 6585와 RFC 9110는 throttling 처리에 적합합니다.
핵심은 중복이 아니라 역할 분담입니다.
- MCP는 discovery와 tool semantics
- REST는 deterministic contract
둘 다 필요하다면 그건 이상한 구조가 아닙니다.
Skills는 packaging layer이지 data plane이 아니다
Skills의 장점은 절차와 guardrails를 배포할 수 있다는 점입니다. 다음과 같은 용도에 특히 좋습니다.
- repeatable workflow instructions
- troubleshooting steps
- shared review habits
- role-specific guidance
하지만 Skills만으로는 freshness, authorization, structured retrieval을 해결할 수 없습니다. Anthropic의 skills docs와 anthropics/skills repository는 포맷 참고용으로 충분합니다.
실무적으로는 다음 분리가 좋습니다.
- Skill이 flow와 constraints를 정의한다
- Skill이 MCP tool 또는 REST endpoint를 호출한다
- runtime이 request, result, policy decision을 기록한다
이렇게 하면 instruction과 data delivery를 분리할 수 있습니다.
Observability가 있어야 MCP를 감사할 수 있다
agent가 tool을 잘못 사용했을 때 최소한 다음은 알 수 있어야 합니다.
- 누가 호출했는지
- 어떤 tool / resource가 노출되었는지
- 어떤 입력이 들어갔는지
- 어떤 policy decision이 적용됐는지
- 어떤 result hash / record id가 반환됐는지
- 얼마나 시간이 걸렸는지
그래서 OpenTelemetry와 structured logs는 선택사항이 아닙니다. context propagation과 traces 문서가 좋은 출발점이고, NIST SP 800-92 draft revision와 SP 800-53 Rev.5는 retention과 audit planning 정리에 도움이 됩니다.
{
"ts": "2026-04-03T09:15:00Z",
"event": "tool.execute",
"requestId": "req_7ad2",
"tool": "get_knowhow_item",
"actor": "agent_ops_reader",
"decision": "allow",
"resultHash": "sha256:ab12...",
"latencyMs": 42
}
이 정도 수준의 재구성이 안 된다면, 지금 가장 큰 문제는 protocol choice가 아닙니다.
puppyone이 들어가는 지점
많은 MCP 프로젝트가 실패하는 이유는 protocol이 아니라 protocol 뒤의 context가 엉켜 있기 때문입니다.
- knowledge가 여러 시스템에 흩어져 있다
- tool마다 보는 내용이 다르다
- permission을 세밀하게 자르기 어렵다
- versioning과 audit lineage가 약하다
puppyone 같은 governed context base는 이 지점을 메웁니다. enterprise Know-How를 구조화하고, hybrid indexing을 적용하고, 동일한 governed knowledge를 MCP, API, workflow packaging으로 배포할 수 있기 때문입니다. 그러면 MCP server는 매번 ad hoc으로 context를 조립하는 대신 curated artifact를 반환하게 됩니다.
특히 다음 조건에서 효과가 큽니다.
- 여러 agent가 같은 source of truth를 써야 할 때
- 같은 knowledge를 MCP와 API 양쪽에 노출해야 할 때
- approval 과정에서 stable identifier와 provenance가 필요할 때
- local-first / self-hosted가 중요할 때
관련 읽을거리:
- Context Engineering: When RAG Isn't Enough
- Vector Database vs. Context Base: What AI Agents Actually Need in Production
- Puppyone + OpenClaw Integration Playbook for Engineers
다음 단계
초기라면 대규모 protocol migration부터 시작하지 않는 편이 좋습니다. 먼저 하나의 read-heavy workflow를 골라 다음을 분명히 하세요.
- narrow MCP tool 하나 정의
- stable response envelope 반환
- policy enforcement를 model 밖에 두기
- trace ID와 structured logs 넣기
- 실제로 다른 consumer가 생길 때만 REST endpoint 추가
기초가 안정된 뒤에 tools, Skills, orchestration을 넓혀도 늦지 않습니다.
puppyone으로 통제된 MCP 도입 설계Get startedFAQs
Q1. MCP가 REST API를 대체하나요?
아닙니다. MCP는 agent-facing execution에 강하고, REST는 host-agnostic contract, gateway control, service reuse에 강합니다.
Q2. 모든 내부 capability를 MCP tool로 만들어야 하나요?
아닙니다. 너무 넓은 tool은 거버넌스와 디버깅이 모두 어려워집니다. 먼저 좁고 typed이며 예측 가능한 capability부터 시작하는 편이 좋습니다.
Q3. Skills만 있으면 충분한가요?
대부분의 경우 충분하지 않습니다. Skills는 workflow intent를 잘 포장하지만, freshness, authorization, auditability가 중요하다면 runtime data는 MCP tool이나 API에서 가져와야 합니다.