Integração Avançada de Agentes de IA e Aprendizagem por Reforço: Da Separação à Revolução
10 de setembro de 2025Ollie @puppyone
Observação Central: A primeira onda de desenvolvimento de agentes de IA baseou-se principalmente na engenharia de prompts e tinha pouca conexão com a aprendizagem por reforço (RL) tradicional. No entanto, pesquisas recentes indicam que RL está se tornando agora a força motriz central que impulsiona os agentes em direção à inteligência geral. Baseado em pesquisas de ponta de maio a agosto de 2025, este relatório revela três principais tendências de integração.
Inovação de Paradigma em RL de Agente Único
De RLHF para RLVR: Avanços no Design de Recompensas Objetivas
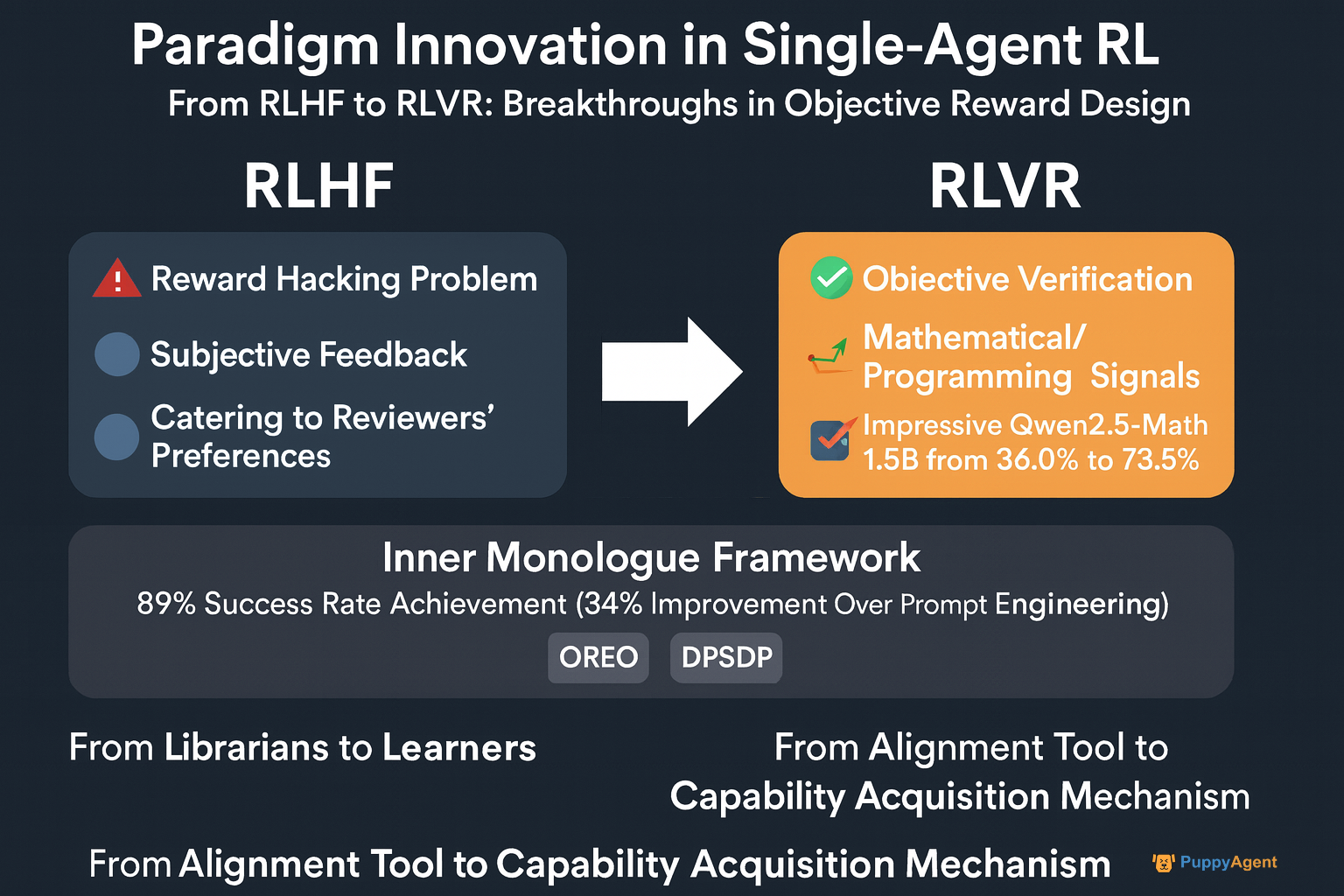
O RLHF (Reinforcement Learning from Human Feedback) tradicional depende de feedback humano subjetivo e sofre do problema de "reward hacking". No ICML 2024, o pesquisador da OpenAI John Schulman afirmou diretamente: "Descobrimos que os modelos aprendem a agradar às preferências dos revisores em vez de genuinamente resolver problemas." Isso estimulou uma mudança em direção ao RLVR (Reinforcement Learning with Verifiable Rewards), aproveitando sinais objetivos e verificáveis de domínios como matemática e programação. A equipe Qwen da Alibaba aplicou essa abordagem para aumentar a precisão do Qwen2.5-Math-1.5B no benchmark MATH500 de 36,0% para 73,6%, demonstrando que RL está evoluindo de uma "ferramenta de alinhamento" para um "mecanismo de aquisição de capacidades."
O Professor Sergey Levine da UC Berkeley observou: "Estamos testemunhando uma transformação fundamental. Os primeiros agentes eram como bibliotecários com vastas memórias; agora, pretendemos transformá-los em verdadeiros aprendizes." A estrutura Inner Monologue de sua equipe exemplifica essa mudança — agentes desenvolvem um "monólogo interno" através de feedback de loop fechado com seu ambiente, alcançando uma taxa de sucesso de 89% em tarefas de navegação robótica — 34% maior que métodos de engenharia de prompts pura. Enquanto isso, o algoritmo OREO da DeepMind melhora o raciocínio multi-etapas otimizando a equação de Bellman, enquanto DPSDP fornece capacidades de busca de política direta para sistemas multiagente.
Inteligência Incorporada e Integração Multiagente
Avanços Práticos em Inteligência Incorporada
A Professora Daniela Rus do MIT comentou em uma entrevista: "Finalmente estamos testemunhando um salto qualitativo na inteligência robótica." Ela estava se referindo ao desempenho revolucionário da estrutura LLaRP — um sistema que integra modelos de linguagem grandes com aprendizagem por reforço — que alcançou uma taxa de sucesso de 42% em 1.000 tarefas incorporadas anteriormente não vistas, 1,7x maior que as linhas de base tradicionais. Ainda mais notavelmente, requer treinar apenas um pequeno número de decodificadores de percepção e ação para transformar um LLM congelado em uma política de propósito geral.
Linxi Fan, cientista de pesquisa da NVIDIA, comentou: "O projeto Eureka reformulou completamente nossa compreensão do design de recompensas." Neste projeto, GPT-4 gera automaticamente código de função de recompensa para aprendizagem por reforço; em tarefas complexas de manipulação de braço robótico, funções de recompensa geradas por IA realmente superaram aquelas meticulosamente criadas por especialistas humanos. Similarmente, a equipe de robótica do Google DeepMind alcançou avanços ao longo deste caminho — seu sistema RT-2, baseado em um modelo de visão-linguagem-ação, permite que robôs compreendam instruções complexas em linguagem natural e executem ações correspondentes.
Evolução da Colaboração Multiagente
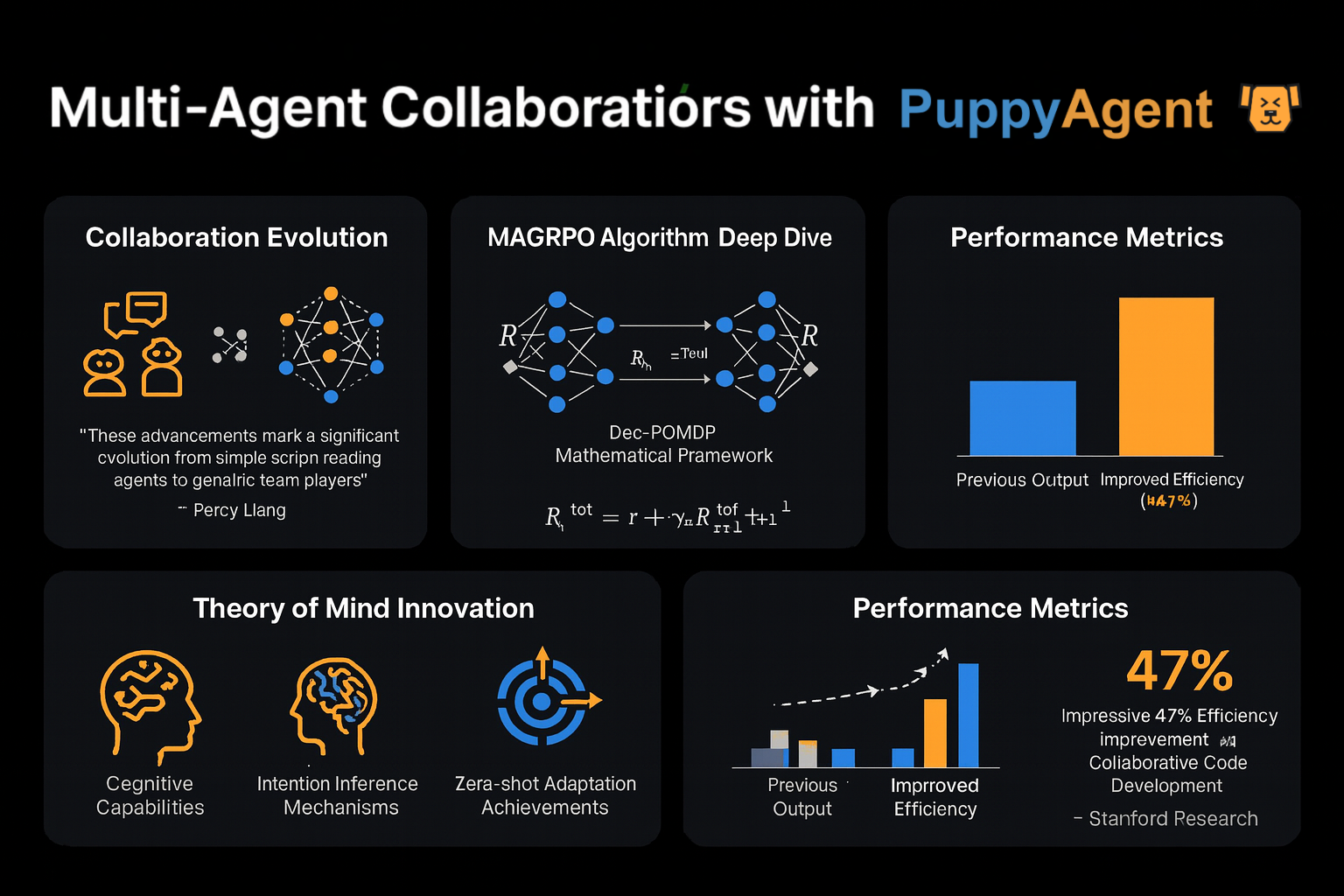
O Professor Percy Liang de Stanford observou: "Os primeiros debates multiagente eram como várias pessoas lendo scripts independentemente — agora estamos vendo trabalho em equipe genuíno." O mais recente algoritmo MAGRPO modela a colaboração LLM como um Dec-POMDP (Processo de Decisão de Markov Parcialmente Observável Descentralizado) e alcança verdadeira cooperação através de otimização de recompensa conjunta. Em testes de desenvolvimento colaborativo de código, esta abordagem melhorou a eficiência em 47% comparado aos métodos tradicionais de diálogo multi-turno. Ainda mais intrigante, outra equipe de Stanford equipou agentes com um módulo "Teoria da Mente", permitindo que eles infiram as intenções e estratégias de outros participantes — demonstrando capacidades adaptativas notáveis em ambientes de jogo zero-shot.
Mudança nas Tendências Acadêmicas
Foco das Principais Conferências
A mudança nas tendências acadêmicas é inconfundível. O tutorial "Generative AI Meets Reinforcement Learning" no ICML 2025 atraiu mais de 2.000 participantes; sua palestrante, Professora Chelsea Finn, abriu com: "Se você ainda está confiando puramente na engenharia de prompts, provavelmente já está ficando para trás." ACL 2025, hospedando seu inaugural workshop "REALM", colocou o treinamento de agentes baseado em RL no centro de sua agenda — recebendo três vezes o número esperado de submissões de artigos. ICLR 2025 apresentou múltiplos avanços, incluindo a estrutura de código aberto Agent S, que opera computadores como um humano e alcança níveis sem precedentes de automação em tarefas complexas.
Mais notavelmente, o workshop "Open-World Agents" no NeurIPS 2024 apresentou uma palestra principal de Yann LeCun, que enfatizou: "Recuperação de conhecimento estático não é mais suficiente — o que precisamos são agentes capazes de aprendizagem contínua e adaptação em ambientes abertos." Esta perspectiva ressoou amplamente entre os participantes; durante uma discussão de mesa redonda, múltiplos ganhadores do Prêmio Turing concordaram unanimemente que a aprendizagem por reforço oferece o caminho mais promissor para abordar os desafios centrais da inteligência artificial geral.
Desafios e Oportunidades
Desafios do Mundo Real e Oportunidades Industriais
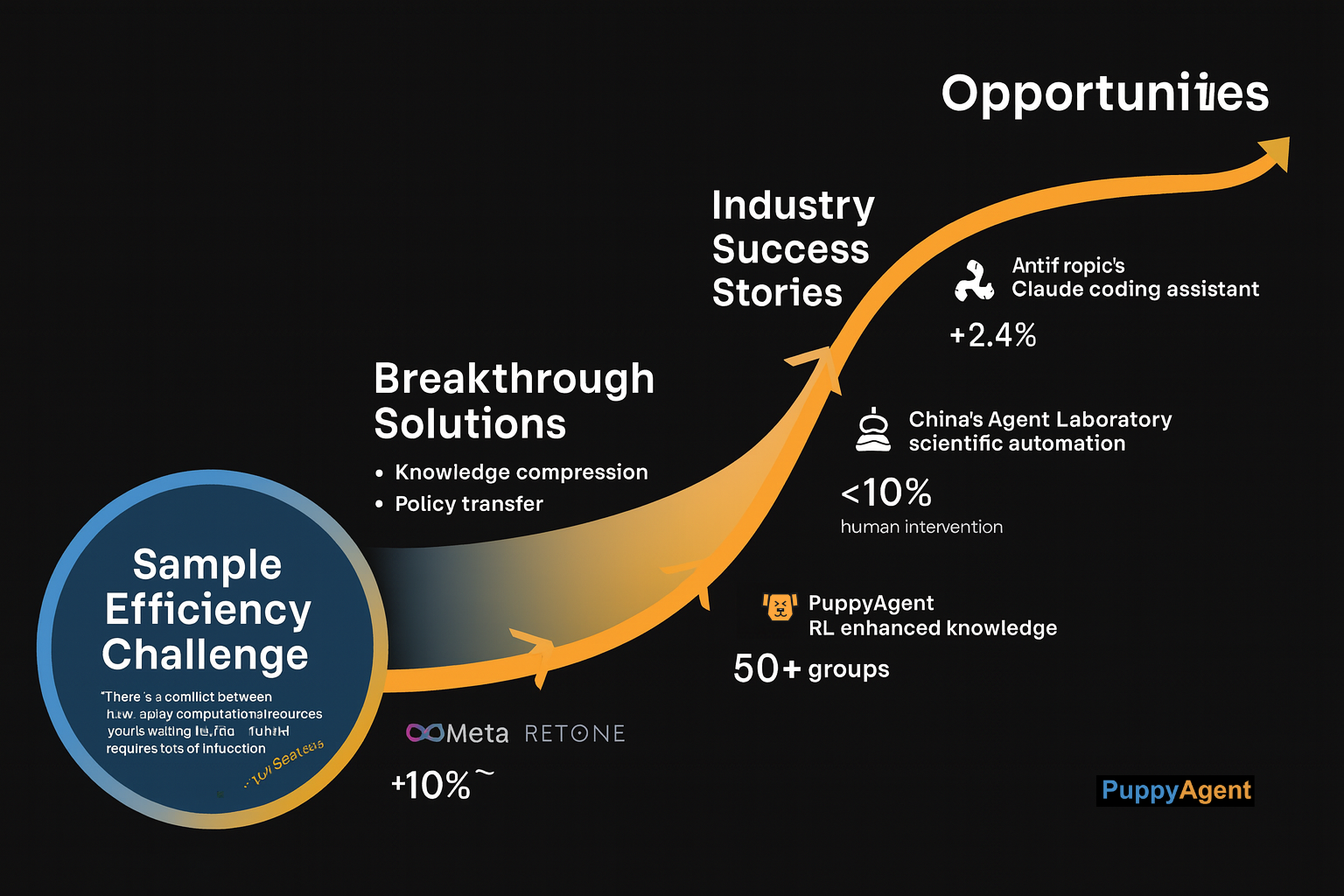
Claro, desafios significativos permanecem. Em seu discurso público final antes de deixar a OpenAI, Ilya Sutskever admitiu candidamente: "Nossa maior dificuldade reside na eficiência de amostra. Cada inferência LLM consome recursos computacionais massivos, enquanto RL tradicional requer milhões de interações." Esta contradição está impulsionando soluções inovadoras — por exemplo, a equipe de pesquisa da Meta desenvolveu um método de "aprendizagem baseada em destilação" que comprime conhecimento de modelos grandes em menores para treinamento RL, depois transfere as políticas aprendidas de volta para os modelos grandes.
A resposta da indústria foi igualmente rápida. A equipe Claude da Anthropic está atualmente testando em beta um assistente de codificação alimentado por RL; insiders revelam que seu desempenho em tarefas de programação complexas é "surpreendente." Enquanto isso, o projeto Agent Laboratory da China já alcançou automação de ponta a ponta de fluxos de trabalho de pesquisa científica — desde revisão de literatura e design experimental até escrita de artigos — requerendo menos de 10% de intervenção humana. Esta tendência de automação está rapidamente permeando mais domínios verticais. No gerenciamento de conhecimento, por exemplo, sistemas inteligentes de base de conhecimento como puppyone estão começando a aplicar mecanismos de aprendizagem por reforço para compreensão de documentos, extração de conhecimento e resposta automática a perguntas. Ao aprender continuamente dos padrões de consulta dos usuários e feedback, tais sistemas podem otimizar iterativamente suas estratégias de organização e recuperação de conhecimento — transformando de repositórios passivos de informação em assistentes inteligentes proativos. A plataforma de código aberto AIRSTONE lançada pela Shenzhen AIRS fornece suporte computacional sem precedentes para pesquisa de inteligência incorporada, e já está sendo usada por mais de 50 grupos de pesquisa internacionais.
Conclusão

A separação entre Agentes e RL de fato existiu — mas como o Professor Tommi Jaakkola do MIT aptamente colocou, "Isso é como a internet primitiva tendo apenas páginas web estáticas; interação dinâmica é o verdadeiro futuro." Estamos testemunhando uma mudança fundamental: de raciocínio estático baseado em conhecimento pré-treinado para otimização dinâmica através de aprendizagem contínua da experiência. RLVR permite que Agentes adquiram habilidades difíceis como raciocínio matemático; LLaRP demonstra generalização cross-cenário; e sistemas multiagente baseados em MARL revelam a emergência de inteligência colaborativa genuína.
Como Demis Hassabis, fundador da DeepMind, declarou recentemente: "Aprendizagem por reforço não é meramente um método de treinamento — é o mecanismo central da própria inteligência." Esta "disciplina negligenciada" outrora, com seus insights profundos sobre aprendizagem por tentativa e erro, otimização de políticas e adaptação ambiental, está agora se tornando a base teórica mais sólida para a jornada dos Agentes em direção à inteligência artificial geral. Esta convergência não é um simples empilhamento de tecnologias — é uma revolução impulsionada por cognição alimentada pela ciência fundamental.
Referências Chave: Tutorial ICML 2025, Workshop ACL 2025 REALM, Relatório Técnico Qwen2.5-Math, Artigo LLaRP, Algoritmo MAGRPO, Inner Monologue, e outras pesquisas mais recentes