Hybrid Indexing & Structured Know‑How for Dev Velocity
20 de março de 2026Ollie @puppyone
Indexação Híbrida e Know-How Estruturado: RAG para Desenvolvedores que Acelera Merges de PR
A velocidade do desenvolvedor não estagna porque as pessoas esqueceram como programar. Ela estagna quando as equipes não conseguem encontrar, confiar ou reutilizar o conhecimento que já está dentro de seus repositórios e documentos. Isso é a entropia do conhecimento: ADRs espalhadas por wikis, contratos de API enterrados em PDFs, propriedade perdida devido à rotatividade organizacional. A geração aumentada por recuperação (RAG) pode ajudar, mas apenas se estiver fundamentada em uma espinha dorsal de recuperação que seja tanto semântica quanto determinística. É aí que a indexação híbrida sobre Know-How estruturado muda o jogo para merges de PR e refatorações mais seguras.
Principais conclusões
- Indexação híbrida + Know-How estruturado reduz alucinações e produz citações precisas e revisáveis que aceleram as revisões de PR.
- Trate o RAG para desenvolvedores como um sistema de engenharia: monitore precision@k, precisão de citação, tempo para merge e taxa de reversão.
- Use um recuperador híbrido (léxico esparso + vetores densos + chaves estruturais/grafo) para responder a perguntas da base de código com caminhos de arquivo exatos e IDs de ADR.
- Comece com micro-fluxos de trabalho: um assistente de descrição de PR com citações e um consultor de refatoração baseado em ADRs/propriedade.
- Prefira implantações privadas/locais, redação de segredos antes do embedding e portões com humanos no loop para quaisquer sugestões de escrita.
RAG para desenvolvedores — o que funciona e o que falha
O RAG combina um LLM com um recuperador que busca evidências de seu código, documentos e histórico de design. Quando funciona, os desenvolvedores recebem resumos fundamentados e rascunhos de texto de PR com fontes. Quando falha, você obtém respostas erradas com confiança e a confiança colapsa.
Padrões de falha a observar:
- Vetores apenas de texto perdem identificadores exatos (ADR-1234, nomes de funções), retornando trechos plausíveis, mas errados.
- A recuperação excessiva inunda os prompts; os revisores veem ruído, não sinal.
- Sem citações significa sem confiança; os revisores devem refazer a busca.
As correções de melhores práticas baseiam-se em orientações bem documentadas: fragmentação semântica, recuperação híbrida e reclassificação (reranking). Para uma visão arquitetural concisa, consulte os padrões voltados para produção no artigo da InfoQ sobre pipelines de RAG, que enfatiza a composição e avaliação da recuperação, não prompts mágicos (InfoQ — Effective Practices for Architecting a RAG Pipeline). E para fluxos de trabalho de desenvolvedores baseados em agentes no momento do CI, a discussão do GitHub sobre IA contínua mostra como assistentes podem elaborar e verificar artefatos no loop (GitHub Blog — Continuous AI in practice: agentic CI for developers).
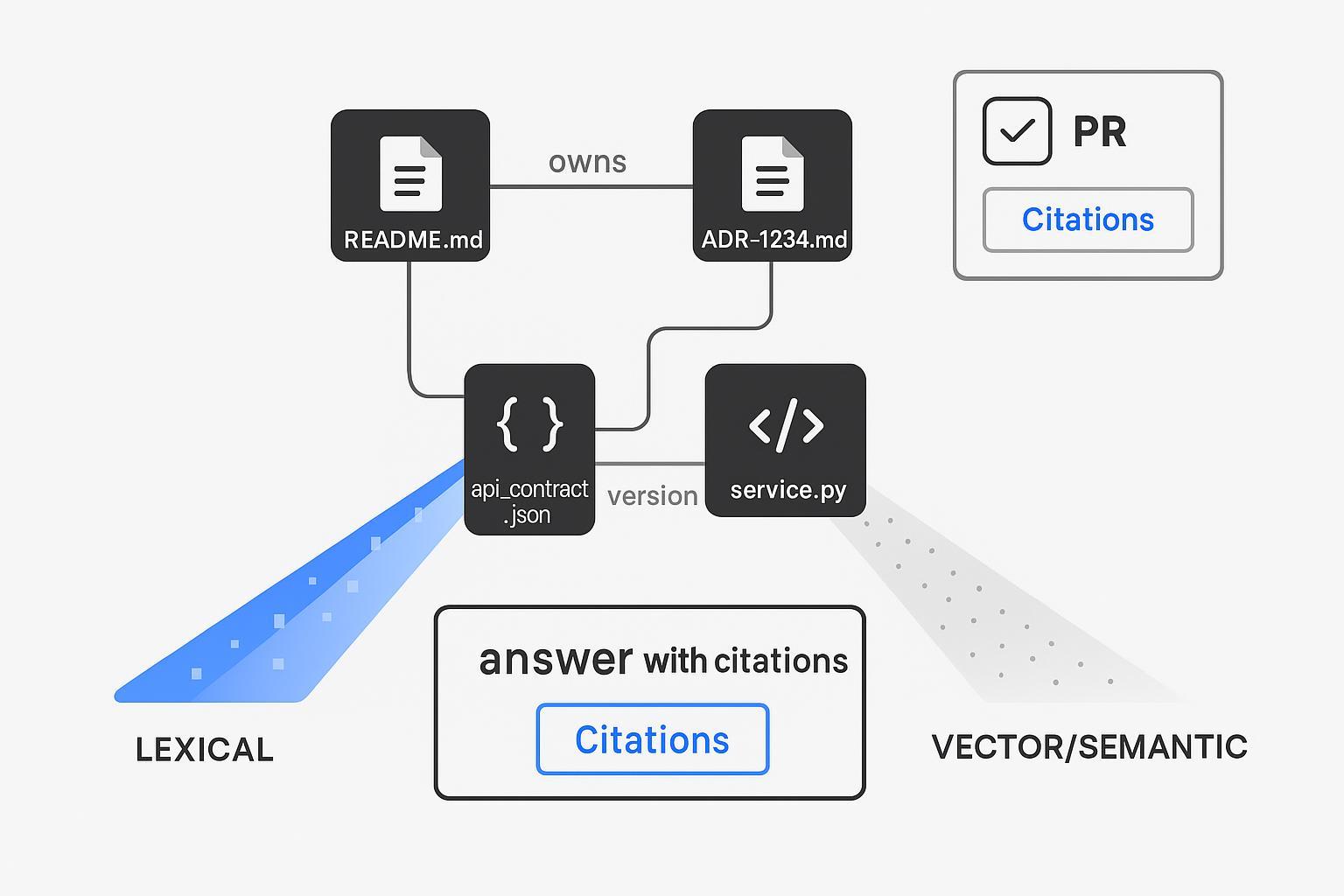
Know-How Estruturado + indexação híbrida como espinha dorsal de recuperação
O texto sozinho não pode sustentar seus fluxos de trabalho de desenvolvedor. Modele o Know-How empresarial explicitamente e recupere através de texto e estrutura.
Um esquema de Know-How mínimo (ilustrativo):
{
"type": "adr",
"adr_id": "ADR-1234",
"title": "Deprecate legacy payment gateway",
"status": "accepted",
"decision": "Move to PayFast v3",
"owners": ["@payments-core"],
"links": {"repo_paths": ["/services/payments"], "docs": ["/docs/payments/adr-1234.md"]},
"supersedes": ["ADR-0899"],
"date": "2025-11-06",
"version": "1.2"
}
Design de recuperador híbrido (visão rápida):
- Léxico: filtros exatos (repo_path:/services/payments, file:*.md), BM25 para identificadores.
- Denso: embeddings de código/doc para paráfrases e intenção.
- Estrutural: joins determinísticos por chaves (adr_id, owner, module) para extrair os arquivos/proprietários corretos.
- Opcional: reclassificação com um cross-encoder para fidelidade.
Este padrão reflete as orientações de fornecedores e da comunidade sobre busca híbrida — fusão densa + esparsa com reclassificação opcional, conforme documentado pelos recursos de engenharia de busca híbrida da Qdrant (Qdrant — Hybrid Search Revamped; Qdrant Docs — Hybrid Queries). O resultado é uma camada de recuperação que pode citar caminhos de arquivo exatos e IDs de ADR, não apenas "algo parecido com isso". Essa é a alavanca de confiança que os revisores precisam.
Micro-fluxos de trabalho que aceleram os PRs
- Assistente de descrição de PR com citações
Objetivo: Elaborar um corpo de PR fundamentado a partir do diff e do Know-How local.
Etapas principais:
- Expandir o título da branch/PR em variantes de consulta.
- Recuperar top-k de: (a) caminhos alterados (filtros léxicos), (b) documentos/trechos semânticamente semelhantes, (c) chaves estruturais (ADRs/proprietários).
- Gerar um corpo de PR que sempre inclua um bloco de Citações com permalinks.
Exemplo de template de corpo de PR:
#### Summary
- Implements PayFast v3 retry policy in /services/payments/retry.go
#### Rationale
- Aligns with ADR-1234 (Deprecate legacy payment gateway). See details below.
#### Impact
- Touches retry.go; no public API changes. Adds metric payments.retry.backoff_ms.
#### Citations
- ADR-1234 — /docs/payments/adr-1234.md#decision
- Code — /services/payments/retry.go#L120-L168
- Runbook — /ops/runbooks/payments-retries.md#rollback
- Consultor de refatoração alimentado por ADRs e propriedade
Objetivo: Tornar grandes refatorações mais seguras, expondo a intenção do design e os proprietários automaticamente.
Etapas principais:
- Dado um plano de refatoração proposto, recuperar ADRs substituídas e proprietários de módulos afetados.
- Gerar um checklist: "notificar @payments-core", "atualizar testes de contrato", "confirmar janela de depreciação conforme ADR-0899".
- Emitir citações para cada fonte para que os revisores possam verificar rapidamente.
Meça a velocidade do desenvolvedor e a qualidade da recuperação
Trate o RAG como um sistema de engenharia com resultados auditáveis.
Métricas para acompanhar:
- Velocidade: tempo médio para merge (TTM), taxa de merge (merged/abertos), iterações de revisão/PR.
- Qualidade: taxa de reversão, taxa de falha de CI, defeitos pós-merge para refatorações.
- Recuperação: precision@k, precisão de citação (a fonte citada sustenta a afirmação?), taxa de alucinação.
Plano A/B (8–12 semanas):
- Controle: fluxo de trabalho padrão.
- Tratamento: habilitar o assistente de descrição de PR + consultor de refatoração (sugestões de apenas leitura) com citações.
- Instrumentar eventos em recuperar → sugerir → aceitação/sobrescrita do revisor → merge.
Para um contexto mais amplo da indústria sobre medição e melhoria da fidelidade do RAG e comportamento de citação, consulte trabalhos recentes de pesquisa e avaliação que formalizam métricas de relevância/fidelidade e auditoria com LLM-como-juiz (arXiv — Evaluation of Retrieval‑Augmented Generation: A Survey; arXiv — Comprehensive and Practical Evaluation of RAG).
Do demo para a produção
Você não precisa de um monólito; você precisa de um loop confiável.
- Ingestão: fragmentação sensível à linguagem para código (funções/classes) e documentos (cabeçalhos/semântica). Anexe metadados (repo_path, module, owner, version). Alvo de 500–1500 tokens para código; 400–1000 para documentos.
- Cadência de indexação: re-embed ao alterar; lote noturno para repositórios ativos; semanal para os inativos. Versione seu índice para rollbacks.
- Governança: prefira implantações privadas/locais; alinhe as ACLs de recuperação às permissões do repositório; redija segredos antes do embedding.
- Atendimento: limite o k para controlar os tokens; armazene em cache consultas frequentes; considere a reclassificação com cross-encoder para namespaces complexos.
- Monitoramento: acompanhe precision@k, precisão de citação, latência e custo/consulta. Alerte sobre desvios (quedas na precisão/precisão de citação).
Sinais do mundo real mostram por que vale a pena fazer isso. A Amazon relatou que o Amazon Q Developer reduziu atualizações de Java em larga escala de dias para minutos em dezenas de milhares de aplicações, economizando estimados 4.500 anos-desenvolvedor e contribuindo para um impacto anual de US$ 260 milhões (AWS DevOps & Developer Productivity Blog, 2024) — evidência de que assistentes de desenvolvedor integrados podem desbloquear mudanças de patamar na produtividade quando integrados ao SDLC (AWS DevOps Blog — Amazon Q Developer milestone). E a história de cliente do GitHub sobre o Mercado Livre aponta para uma adoção em toda a organização com ~50% menos tempo gasto escrevendo código e uma taxa de transferência de PR extraordinária, sugerindo que o teto é alto quando os assistentes estão no caminho crítico (GitHub Customer Stories — Mercado Libre).
Notas sobre ferramentas — stacks que funcionam bem
- Vetor + esparso: Qdrant, Pinecone, Weaviate, todos suportam padrões híbridos; escolha com base no controle sobre a fusão de pontuação, maturidade de operações e custo.
- Orquestração: LangChain/LlamaIndex para composição rápida; Dagster/Airflow para operações de ingestão.
- Embeddings: escolha modelos ajustados para código para repositórios; monitore desvios e re-embed seletivamente.
- Grafo/estrutura: Neo4j/TigerGraph para grafos de Know-How explícitos ou JSON/kv leve para equipes menores.
- CI de Agente: integre assistentes em hooks de PR e comentários de CI conforme a orientação de CI baseada em agentes do GitHub.
Exemplo prático: usando o Know-How estruturado e a indexação híbrida da puppyone
A indexação híbrida só brilha quando seu conhecimento é modelado para máquinas. Uma maneira neutra de implementar isso é armazenar o conhecimento empresarial como Know-How estruturado (JSON/grafo) e fundir buscas léxicas, vetoriais e estruturais em um único recuperador.
Exemplo de fluxo de trabalho (ilustrativo, neutro):
- Modele ADRs, propriedade e contratos de API como nós de Know-How de primeira classe (ex: adr_id, status, decisão, proprietários, caminhos_repo, versão).
- Ingestão de trechos de código/doc com metadados (caminho_repo, símbolos, proprietários). Construa um índice híbrido onde filtros léxicos (ex: caminho do repositório), vetores (similaridade semântica) e joins estruturais (adr_id → arquivos/proprietários relacionados) são combinados.
- No assistente de PR, exija um bloco de Citações com permalinks para ADRs e intervalos de linhas de arquivos para que os revisores possam verificar rapidamente.
Este padrão é suportado por materiais conceituais públicos da puppyone, que se posiciona em torno de Know-How estruturado e indexação híbrida para recuperação determinística e citações precisas. Para uma visão geral dessa abordagem, consulte o artigo da empresa sobre indexação híbrida, que resume como texto e estrutura podem ser combinados para uma fundamentação confiável em fluxos de trabalho de agentes (veja a visão geral no "Ultimate Guide to Agent Context Base: Hybrid Indexing") (puppyone’s hybrid indexing guide). Use isso como uma referência conceitual ao projetar seu próprio esquema e recuperador; adapte à sua stack e restrições de governança.
Conclusão e próximos passos
Se o seu objetivo são PRs mais rápidos e seguros, invista primeiro em Know-How estruturado e em um recuperador híbrido que possa provar cada afirmação com uma citação. Pilote um assistente de descrição de PR e um consultor de refatoração, meça o TTM e a precisão das citações, e então dimensione o que funciona. Se você estiver explorando Know-How estruturado e indexação híbrida, pode avaliar a puppyone em um pequeno piloto privado e compará-la com sua stack existente.