Guia definitivo de indexação híbrida para aprendizagem contextual
7 de fevereiro de 2026Ollie @puppyone
Principais conclusões
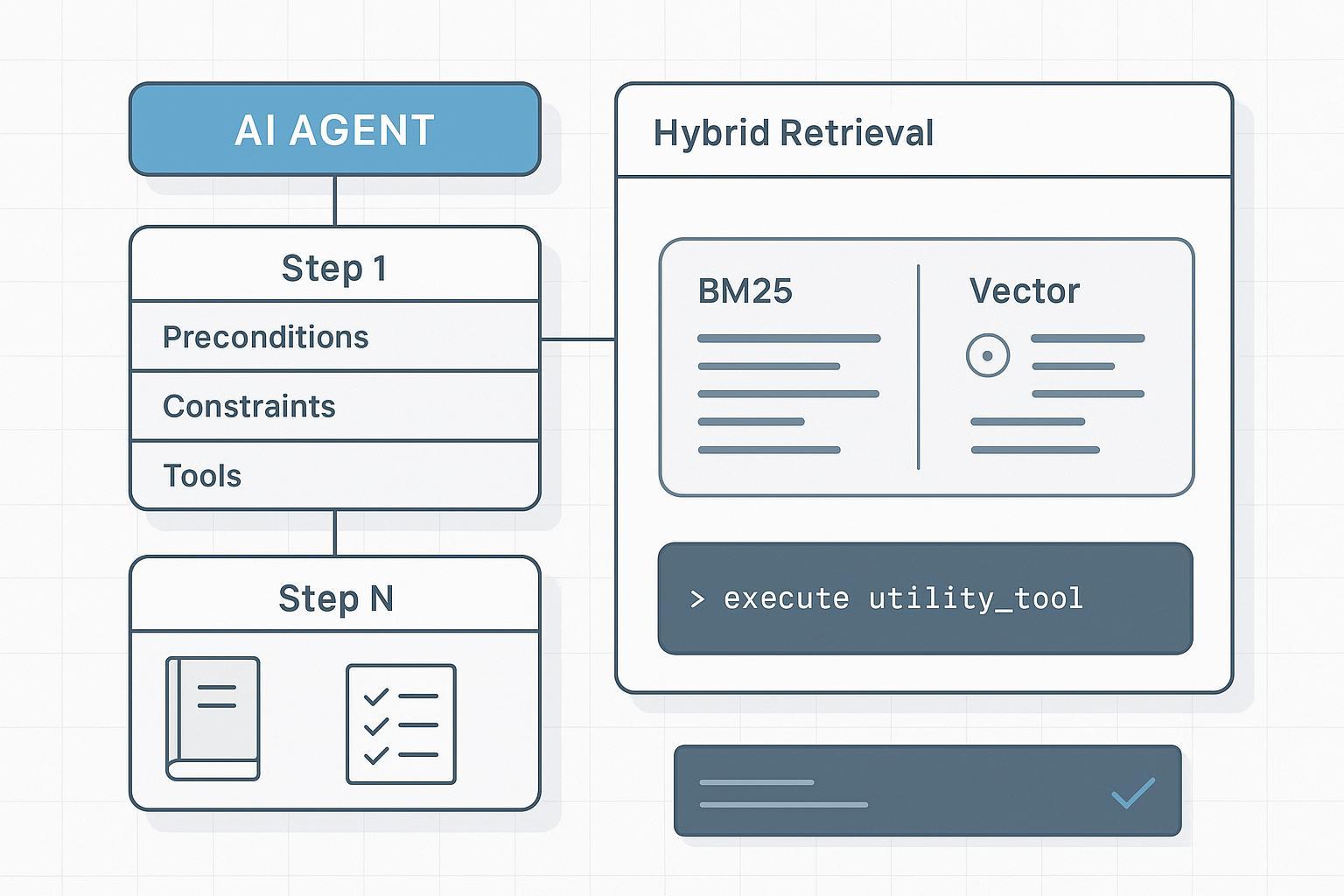
- A recuperação híbrida e consciente de campos supera «simplesmente alongar o contexto». Você precisa de fatias determinísticas por etapa, não de um muro de texto.
- Os limites do modelo são reais: benchmarks mostram altas taxas de contexto ignorado ou mal usado; projete sua pilha para prevenir, detectar e corrigir esses erros.
- Para Operações/Suporte: combine um Know-How JSON/Grafo com indexação híbrida e um laço agéntico planejador→executor→verificador para aderência à etapa e auditabilidade.
Por que os modelos ignoram e malusam o contexto nos SOPs
Um benchmark (CL-bench: 500 contextos, 1.899 tarefas, 31.607 rubricas) mostra o quão frágeis são os modelos ao aprender do contexto dado: dez modelos de fronteira resolveram apenas ~17,2% das tarefas em média; o melhor atingiu ~23,7% mesmo em modo de raciocínio. O erro dominante foi não usar corretamente o contexto—omitir detalhes-chave ou aplicar a regra errada. Veja CL-bench paper (arXiv), Tencent Hunyuan research blog. Contexto longo por si só não corrige; LongBench v2 etc. mostram que uma janela melhor ainda deixa lacunas em raciocínio e agregação (LongBench v2 ACL). Em SOPs multi-etapas isso aparece como pulo de etapa, deriva de instrução ou ações inseguras.
Modos de falha comuns do RAG ingênuo na execução de SOPs
Pilhas RAG falham em fluxos operacionais porque a unidade de recuperação não corresponde à unidade de ação: chunks excessivamente amplos → deriva; campos não ponderados enterram tokens críticos. Prompts monolíticos incentivam improvisação. Remédio: projetar para recuperação determinística e execução verificável.
Fundamentos: modele seus SOPs como Know-How JSON/Grafo
Agentes precisam de conhecimento estruturado e por campos. Um esquema prático codifica etapas, dependências, restrições e métodos de verificação. O exemplo JSON do artigo em inglês (sop.router.reset.v3, step_number, preconditions, constraints, tools_allowed, checkpoints, verification_method, dependencies) permanece. Assim o recuperador pode ponderar título, step_number, preconditions e constraints mais que a narrativa. Context Base: puppyone About.
Indexação híbrida para aprendizagem contextual em manuais longos e densos
O núcleo não é «mais contexto» mas «melhores unidades de recuperação e sinais de ranking». Na prática: indexação híbrida com consciência de campo e uma pequena passagem de rerank.
- Combine sinais lexicais esparsos (BM25/BM25F) com vetores densos. Lexical: IDs exatos, avisos, restrições; denso: melhor recall em etapas formuladas semanticamente. Referências: Elastic — What is hybrid search, Elastic retrievers and RRF, Weaviate — Hybrid search explained.
- Boosts conscientes de campo: preferir título, step_number, preconditions, constraints, tools_allowed em relação à narrativa.
- Recuperar por etapa fatias mínimas e determinísticas; não alimentar todo o SOP cada vez.
- Opcional: rerank do top-k com cross-encoder ou reranker consciente da estrutura.
RAG agentivo para SOPs: planejador → recuperador → executor → verificador
O planejador decompõe em intenções por etapa e formula consultas de recuperação (step_number, ferramentas necessárias). O recuperador devolve fatias mínimas com IDs. O executor só invoca ferramentas enumeradas com parâmetros validados por esquema e cita os slice IDs. O verificador confere checkpoints e restrições antes de avançar; em desvio, replan ou revisão humana. Veja Anthropic — Multi-agent research system.
Exemplo prático: uma etapa ponta a ponta
Aviso: Puppyone é nosso produto; aqui mencionado de forma neutra como uma possível context base. Mais em puppyone. Objetivo: executar a etapa 7 de «Router Safe Reset» com recuperação híbrida e laço agentivo. Plano de consulta, pseudocódigo (estilo Python) e log de estado como no artigo em inglês. O mesmo laço pode ser implementado com Elastic/OpenSearch/Vespa/Weaviate ou RDBMS+pgvector+BM25.
Playbook de avaliação: provar confiabilidade, depois escalar
Qualidade de recuperação: Recall@k, MRR/nDCG por etapa, Context Precision, Context Sufficiency. Execução: Step Adherence %, Action Success Rate, Instruction Drift Rate, incidentes por 1.000 execuções, Time-to-Resolution. Por etapa SOP armazenar slice IDs de ground truth e padrões de ferramenta/resultado esperados; afirmar que o executor cita o slice usado e que os checkpoints passam antes de avançar. Visão geral: RAG evaluation survey (2024).
Alternativas e paridade
| Stack | Opções de fusão híbrida | Boosts conscientes de campo | Fit on-prem/VPC | Notas |
|---|---|---|---|---|
| Elasticsearch | RRF, mistura ponderada | BM25F, boosts multi-campo | Self-host maduro | APIs retriever, rerankers cross-encoder |
| OpenSearch | Ponderado + padrões rerank | Boosts via analisadores | Self-host first-class | Trabalho de perf vector |
| Vespa | Lexical + ANN + rerank | Recursos por campo | Self-host, scale-out | Pipeline de ranking/ML |
| Weaviate | RRF/híbrido ponderado | Pesos/filtros de propriedade | Managed + self-host | Documentação híbrida clara |
Para a abordagem «Agent Context Base»: por ex. puppyone. Critérios: pontuação consciente de campo, garantias de slicing determinístico, logs de auditoria, suporte a harness de avaliação.
Como «bom» se parece na prática
Em pilotos, a mudança de prompts de documento inteiro para fatias por etapa e por campo reduz a deriva de instrução e aumenta a aderência à etapa. O ponto da indexação híbrida para aprendizagem contextual é colocar a superfície exata de restrições nas mãos do agente e exigir verificação antes de continuar.
Próximos passos
Se você está avaliando uma abordagem de nível produção para automação de SOPs—Know-How estruturado, indexação híbrida e laço planejador→executor→verificador—vamos olhar juntos seu corpus e restrições. Agende uma demo técnica focada em indexação híbrida + RAG agentivo para seu ambiente.