利用本地数据构建RAG:面向隐私安全的AI开发指南
2025年1月10日Alex @puppyone
 图片来源:AI生成
图片来源:AI生成
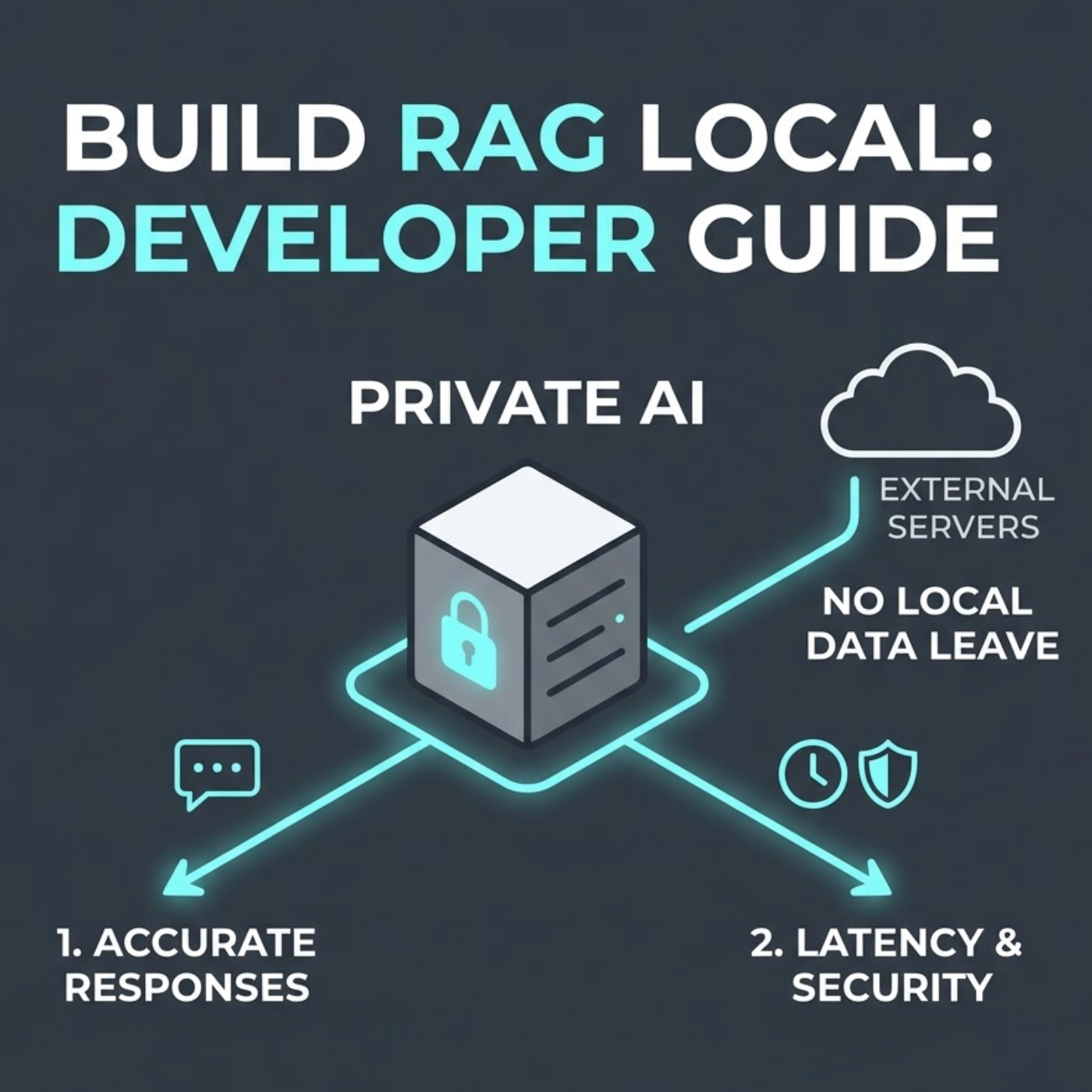
数据隐私已成为人工智能发展中的一个关键问题,尤其是在处理敏感企业数据时。组织不愿意将其机密信息发送到处理人工智能的外部服务器或云服务。这正是使用本地数据的LangChain RAG(检索增强生成)系统发挥作用的地方,为需要保留信息控制权的开发人员提供了一个安全的选择。
本地数据RAG系统通常使用LangChain实现,除了隐私之外,还提供了巨大的好处。它们减少了延迟,允许自定义架构,并且独立于第三方服务工作。在本指南中,我们将引导您完成使用LangChain构建自己的本地RAG系统的步骤,涵盖从环境设置到性能优化的所有内容。开发人员将学习如何实施私有AI解决方案,在保持对流程完全控制的同时,确保敏感数据的安全。
建立您的本地开发环境
要构建我们的LangChain RAG系统,我们需要建立一个有弹性的本地开发环境。让我们来看看成功构建和实施它所涉及的一切。
所需软件和依赖项
Python 3.11或更高版本是我们的基础。虚拟环境管理器将帮助您入门——您可以选择:
-
虚拟环境 (venv)
- 创建并激活虚拟环境
- 通过pip安装所需的包
- 生成requirements.txt进行依赖管理
-
Conda环境
- 创建conda环境
- 安装必要的包
- 导出environment.yml以实现可复现性
对于LangChain RAG开发,您需要安装特定的库,如LangChain、用于向量存储的Chroma和用于本地LLM部署的Ollama。
硬件要求与优化
本地RAG系统需要特定的硬件配置。以下是推荐的规格:
| 组件 | 最低要求 | 推荐 |
|---|---|---|
| CPU | 多核处理器 | 16+核 |
| RAM | 16GB | 32GB或更高 |
| GPU | NVIDIA (8GB VRAM) | NVIDIA RTX 4080/4090 |
| 存储 | 快速NVMe SSD | 多个NVMe驱动器 |
系统在每个GPU加速器至少有4个CPU核心的情况下表现最佳。它还需要两倍于总GPU VRAM的CPU内存。
初始配置步骤
LangChain RAG开发的环境设置需要以下关键步骤:
-
安装基础依赖项:
- 用于向量存储的ChromaDB
- 用于模型集成的LangChain工具
- 用于文档处理的Unstructured包
-
配置模型设置:
- 下载所需模型(例如,LLaMA 3.1)
- 设置环境变量
- 初始化向量数据库连接
测试基本功能有助于验证我们的安装。从事企业解决方案的团队应从一开始就设置适当的版本控制和依赖管理。
实现本地向量数据库
向量数据库是我们LangChain RAG系统的基础。选择正确的向量存储对于获得最佳性能至关重要。让我们来看看如何为我们的私有AI解决方案构建一个高效的本地向量数据库。
选择正确的向量存储
构建RAG系统需要仔细考虑使用哪个向量存储。向量数据库分为两种类型:带有向量扩展的传统数据库和专门构建的向量解决方案。
以下是需要考虑的主要事项:
- 查询性能:向量存储应使用先进算法快速找到相似项
- 可伸缩性:它需要能够平稳地处理更多数据
- 存储选项:内存中和基于磁盘的存储选项都很重要
数据索引策略
正确的索引策略可以大大加快相似性搜索的速度。HNSW(分层可导航小世界)索引效果非常好。它可以在不损失太多准确性的情况下提供快速查询。还有其他索引选项:
| 索引类型 | 最适用于 | 权衡 |
|---|---|---|
| 平面索引 | 小数据集 | 简单,但对于大型数据集较慢 |
| HNSW索引 | 大规模数据 | 更复杂,扩展性更好 |
| 动态索引 | 增长中的数据集 | 自动切换能力 |
性能优化技术
我们的本地向量存储需要进行特定的调整才能发挥最佳性能。系统的成功取决于我们管理和配置资源的好坏。
我们的测试表明,向量存储需要以下优化:
-
内存管理:
- 向量应适应可用RAM以获得最佳搜索速度
- 内存不足会导致导入速度变慢
-
查询优化:
- 批量处理多个查询
- 将常用数据保存在缓存中
-
索引配置:
- 调整HNSW设置以提高搜索质量
- 在准确性和速度之间找到最佳平衡点
当我们跟踪负载延迟和每秒查询数(QPS)等重要数据时,系统表现最佳。这些策略有助于我们的本地RAG系统快速找到相似的向量,同时保持数据私有并在我们的控制之下。
部署和管理本地LLM
使用LangChain正确部署本地语言模型(LLM)需要仔细研究几个关键因素。本节将引导您了解使用LangChain建立可靠的本地RAG系统所需的一切。
模型选择标准
您的硬件能力在选择用于LangChain集成的LLM时起着重要作用。一个简单的计算可以提供帮助:将模型的参数数量(以十亿为单位)乘以2,再加上20%的开销,就可以得出您需要多少GPU内存。举个例子,一个拥有110亿参数的模型大约需要26.4GB的GPU内存。
| 模型大小 | 最低GPU内存 | 推荐GPU |
|---|---|---|
| 3-7B参数 | 16GB VRAM | RTX 4080 |
| 7-13B参数 | 32GB VRAM | A40 |
| 13B+参数 | 40GB+ VRAM | A100 |
部署最佳实践
我们的本地RAG系统与LangChain结合使用时,以下三种部署方法效果最佳:
- 容器化:
- 使用Docker实现一致的环境
- 启用GPU加速支持
- 实施适当的资源分配
量化技术可以显著减小模型大小并保持性能。研究表明,剪枝可以将模型大小减小多达90%,同时保持95%的原始准确性。
资源管理策略
良好的资源管理和合适的硬件对于LangChain本地LLM部署的峰值性能至关重要。小型语言模型(SLM)为边缘部署提供了几个优势:
- 通过量化减少计算负载
- 降低内存要求
- 提高能源效率
- 提高推理速度
vLLM或NVIDIA Triton推理服务器等工具有助于多用户部署。这些解决方案允许您使用张量并行将大型模型拆分到多个GPU上。一些模型,如需要216GB GPU内存的90B参数版本,使用分布式推理策略效果更好。
以下是如何在LangChain RAG系统中充分利用您的资源:
- 实施适当的GPU内存管理
- 使用批处理处理多个查询
- 在可用时启用Flash Attention
- 监控系统性能指标
一种结构化的部署和管理方法将帮助您使用LangChain构建一个快速的本地RAG系统,同时保持性能和隐私。这种方法确保您在明智使用资源的同时,为企业应用程序获得可靠的结果。
数据处理与嵌入管道
使用LangChain构建一个精心设计的RAG系统,需要仔细关注数据处理和嵌入生成。让我们看看如何创建一个既能保证安全性又能保证性能的弹性管道。
文档处理工作流
文档处理管道从适当的数据准备开始。向量嵌入已成为数据窃取的主要目标。最近的研究表明,攻击者在92%的情况下可以恢复确切的输入。这促使我们实施一个精心设计的工作流:
-
数据准备:
- 文本提取与规范化
- 删除不相关内容
- 格式标准化
-
分块策略:
- 最佳块大小:1200个字符
- 块重叠:300个字符
对于文档加载,您可以使用LangChain的WebBaseLoader或其他专门的加载器,具体取决于您的数据源。
嵌入生成方法
有效的嵌入生成是我们LangChain RAG系统的核心。这些嵌入支持多种高级应用:
| 应用类型 | 目的 |
|---|---|
| 语义搜索 | 基于意义的查询 |
| 面部识别 | 图像处理 |
| 语音识别 | 音频分析 |
| 推荐 | 内容匹配 |
模型的质量直接影响嵌入的保真度。嵌入是任意数据的机器表示。我们通过实施属性保留加密来优化嵌入生成,这允许:
- 有意义的查询匹配
- 受保护的向量操作
- 安全的相似性搜索
对于本地嵌入,LangChain提供了Ollama Embeddings,可与Ollama库结合使用以实现高效的嵌入生成。
质量控制措施
我们的RAG管道中的高标准需要全面的质量控制措施。研究表明,嵌入质量显著影响检索精度。我们的质量保证流程包括:
-
数据验证:
- 输入清理
- 格式验证
- 一致性检查
-
性能监控:
- 检索精度跟踪
- 召回率测量
- F1分数评估
应用层加密(ALE)为嵌入提供了最佳的安全性。即使有人获得了数据库凭据,这也能保护数据。这些措施帮助我们在保持敏感数据受控的同时,维持安全性和性能。
性能优化与监控
要从我们的本地LangChain RAG系统中获得最佳性能,需要密切关注指标、优化和监控。让我们看看如何使我们的系统发挥最佳性能,同时保持数据私有。
系统性能指标
我们需要跟踪几个关键性能指标来监控系统健康状况。我们的重点是三个主要指标类别:
| 指标类型 | 描述 | 目标范围 |
|---|---|---|
| 延迟 | 每个查询的响应时间 | 100-500毫秒 |
| 吞吐量 | 每秒处理的请求数 | 基于核心数 |
| 资源使用 | CPU、内存、GPU利用率 | 80%阈值 |
这些指标帮助我们发现瓶颈和可以改进的领域。我们跟踪向量搜索性能和模型推理速度,以保持系统平稳运行。
优化技术
我们使用几种经过测试的优化策略来提升我们的LangChain RAG系统的性能。我们的重点领域是:
-
向量搜索优化:
- 减少向量维度(最多4096)以加快处理速度
- 使用预过滤来缩小搜索范围
- 设置专用搜索节点以获得更好的性能
-
资源管理:
- 设置单独的搜索节点以隔离工作负载
- 为向量数据和索引添加足够的RAM
- 使用二进制数据向量以节省3倍的存储空间
我们的测试表明,良好的向量量化可以在保持高搜索准确性的同时,减少存储需求。我们建议对大多数嵌入模型使用标量量化,因为它能保持强大的召回能力。
监控与警报设置
我们的监控设置可以及早发现并响应性能问题。我们建立了强大的监控系统,具有:
-
警报配置:
- 针对特定事件的自定义周期性警报
- 针对关键问题的即时匹配警报
- 基于计划查询的通知
-
性能跟踪:
- 系统稳定性指标
- 负载监控以捕捉异常模式
- 每次模型交互的成本跟踪
我们使用自动化指标来简化评估过程。这些指标回答了关于系统性能的复杂问题,例如重排器的效果如何以及我们的分块技术的效率如何。
系统需要定期检查其组件才能发挥最佳性能。我们运行自动化的压力测试,以了解系统在峰值负载下的表现。我们的监控还跟踪性能随时间的变化,这向我们展示了数据源和用户行为的变化如何影响系统的运行情况。
这些全面的监控和优化策略帮助我们维护一个性能良好并满足我们需求的RAG系统,同时保持数据的私密和安全。
结论
使用LangChain的本地RAG系统只需要您仔细考虑多个技术方面。这些好处使所有这些工作都值得。私有AI解决方案帮助组织完全控制敏感数据。它们通过本地语言模型和基于LangChain的RAG实现提供强大的功能。
几个因素决定了您的成功。良好的硬件规格是基础。快速准确的信息检索来自高效的向量存储。本地LLM部署策略与安全的数据处理管道协同工作。它们将共同为您提供卓越的性能和隐私保护。
系统的资源管理在实施中起着至关重要的作用。良好的监控工具有助于维持峰值性能。随着数据的增长,定期的优化和改进可以保持一切顺利运行。
组织应以小步骤开始他们的私有AI之旅。他们需要进行充分的测试,并根据人们的实际使用情况进行发展。这条路径有助于及早发现问题,并能实现稳定的系统增长。
隐私要求不是限制——它们是构建更可靠AI系统的机会。使用LangChain的本地RAG实现表明,组织可以在不冒数据安全风险或失去运营独立性的情况下使用先进的AI。
常见问题解答
Q1. 使用LangChain以本地数据构建RAG系统的主要优势是什么?
使用LangChain以本地数据构建RAG系统可提供增强的数据隐私、减少的延迟、可定制的架构以及独立于第三方服务。它使组织能够完全控制敏感信息,同时利用先进的AI功能和LangChain强大的RAG开发工具。
Q2. 使用LangChain设置本地RAG系统需要哪些关键组件?
本地RAG系统的基本组件包括一个带有Python 3.11或更高版本的强大开发环境、一个用于高效数据存储和检索的向量存储、一个本地语言模型(LLM)如LLaMA 3.1,以及一个用于文档处理和嵌入生成的数据处理管道。LangChain提供了像ChatOllama用于本地LLM集成和OllamaEmbeddings用于本地嵌入生成的工具。
Q3. 如何在使用LangChain的本地RAG系统中优化性能?
基于LangChain的本地RAG系统的性能优化涉及实施高效的向量搜索技术、适当的资源管理以及对延迟、吞吐量和资源使用等关键指标的定期监控。向量量化、预过滤和任务分解等技术可以显著提高系统效率。LangChain的RunnablePassthrough和StrOutputParser等工具可用于优化RAG管道。
Q4. 在企业环境中实施本地RAG系统可能会出现哪些挑战?
常见的挑战包括处理过时或不一致的文档、主题专家内容清理能力有限,以及在组织网络边界内安全处理数据的需求。此外,在部署本地LLM和集成LangChain组件时,可能需要解决硬件和软件兼容性问题。
Q5. 如何提高数据质量以使用LangChain获得更好的RAG系统性能?
为了提高LangChain RAG系统中的数据质量,组织可以实施内容清理冲刺、进行主题专家访谈、使用自动化内容质量评分并丰富元数据。建立一个使用LangChain的RecursiveCharacterTextSplitter等工具进行文本分割的结构化文档处理工作流,并在整个数据管道中实施质量控制措施也是有益的。LangChain的文档加载器和文本分割器可以优化以获得更好的分块和上下文检索。