AI智能体与强化学习的深度集成:从各自为战到协同革命
2025年9月10日Ollie @puppyone
核心观察: 早期AI智能体的发展主要依赖于提示工程,与传统的强化学习(RL)关联甚少。然而,最近的研究表明,强化学习正成为推动智能体迈向通用智能的核心驱动力。基于2025年5月至8月的前沿研究,本报告揭示了三大集成趋势。
单智能体强化学习的范式创新
从RLHF到RLVR:客观奖励设计的突破
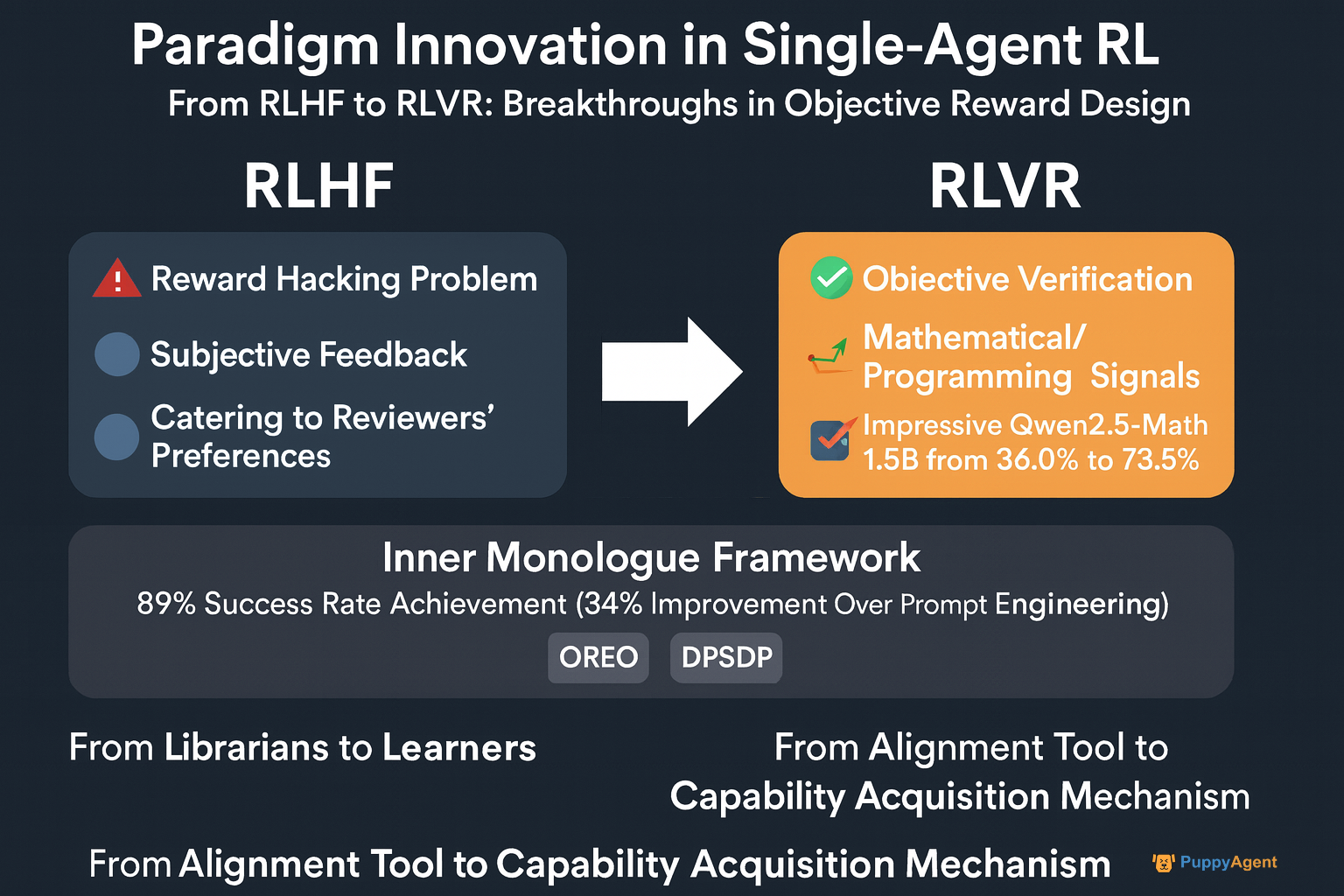
传统的RLHF(基于人类反馈的强化学习)依赖于主观的人类反馈,并存在“奖励 hacking”问题。在ICML 2024上,OpenAI研究员John Schulman直言:“我们发现模型学会了迎合审查者的偏好,而不是真正解决问题。”这促使向RLVR(基于可验证奖励的强化学习)的转变,利用数学和编程等领域的客观、可验证信号。阿里巴巴的Qwen团队应用此方法,将Qwen2.5-Math-1.5B在MATH500基准测试中的准确率从36.0%提升至73.6%,表明强化学习正从“对齐工具”演变为“能力获取机制”。
加州大学伯克利分校的Sergey Levine教授观察到:“我们正在见证一场根本性的变革。早期的智能体就像拥有海量记忆的图书管理员;现在,我们的目标是把它们变成真正的学习者。”他团队的“内心独白”框架体现了这一转变——智能体通过与环境的闭环反馈发展出“内心独白”,在机器人导航任务中实现了89%的成功率——比纯提示工程方法高出34%。与此同时,DeepMind的OREO算法通过优化贝尔曼方程增强了多步推理能力,而DPSDP为多智能体系统提供了直接的策略搜索能力。
具身智能与多智能体集成
具身智能的实践突破
麻省理工学院的Daniela Rus教授在一次采访中表示:“我们终于见证了机器人智能的质的飞跃。”她指的是LLaRP框架的突破性表现——一个将大型语言模型与强化学习相结合的系统——在1000个前所未见的具身任务中取得了42%的成功率,比传统基线高出1.7倍。更值得注意的是,它仅需训练少量感知和行动解码器,就能将一个冻结的LLM转变为通用策略。
NVIDIA的研究科学家Linxi Fan评论道:“Eureka项目彻底重塑了我们对奖励设计的理解。”在该项目中,GPT-4自动为强化学习生成奖励函数代码;在复杂的机械臂操作任务中,AI生成的奖励函数实际上优于人类专家精心设计的奖励函数。同样,Google DeepMind的机器人团队也在这条路径上取得了突破——他们的RT-2系统基于视觉-语言-行动模型,使机器人能够理解复杂的自然语言指令并执行相应的动作。
多智能体协作的演进
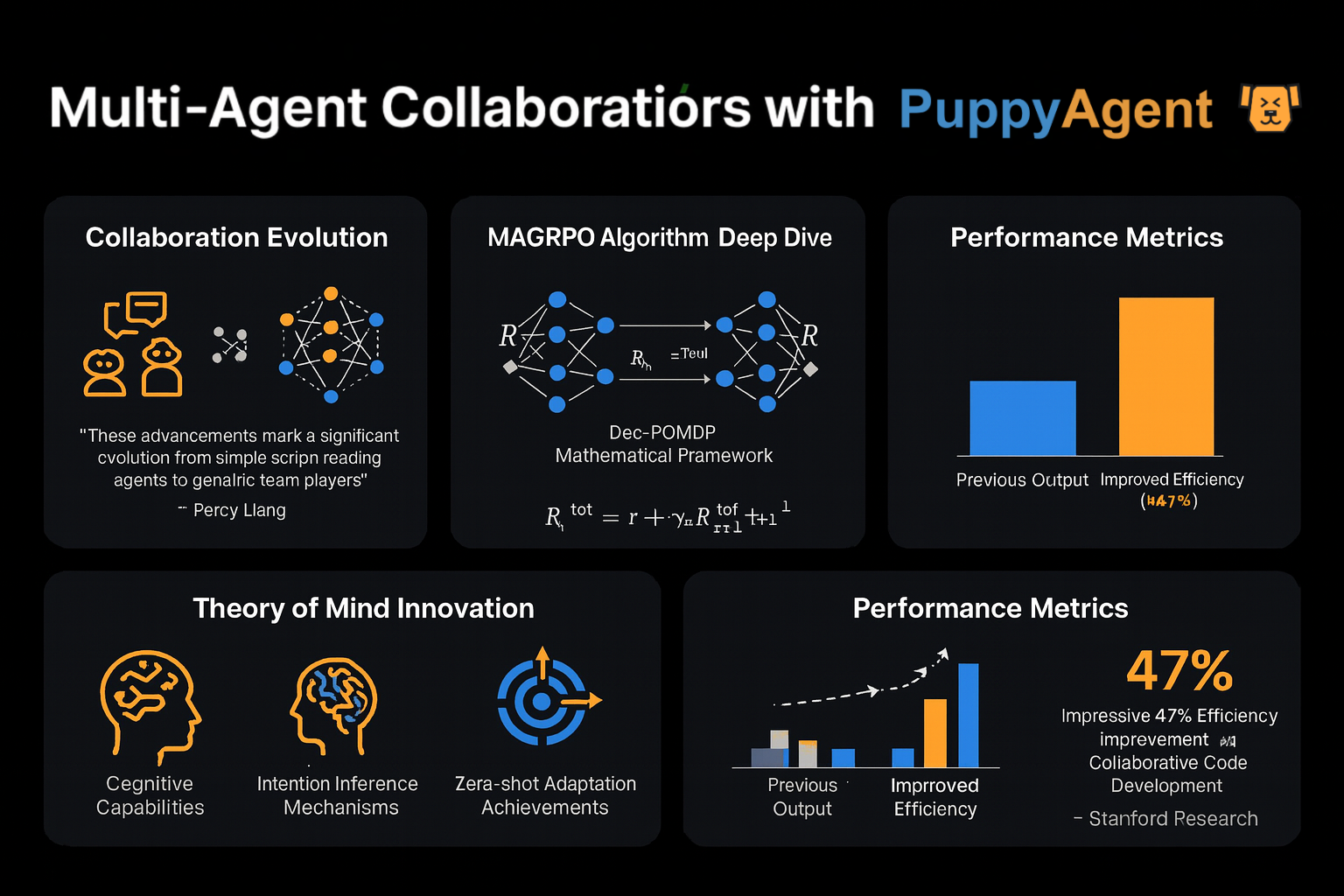
斯坦福大学的Percy Liang教授观察到:“早期的多智能体辩论就像几个人独立地念稿子——现在我们看到了真正的团队合作。”最新的MAGRPO算法将LLM协作建模为Dec-POMDP(分散式部分可观察马尔可夫决策过程),并通过联合奖励优化实现真正的合作。在协作代码开发测试中,这种方法比传统的多轮对话方法提高了47%的效率。更有趣的是,另一个斯坦福团队为智能体配备了“心智理论”模块,使其能够推断其他参与者的意图和策略——在零样本博弈环境中表现出卓越的适应能力。
学术趋势的转变
顶级会议的焦点
学术趋势的转变是明确无误的。ICML 2025的“生成式AI与强化学习的碰撞”教程吸引了超过2000名与会者;其主讲人Chelsea Finn教授开场白说:“如果你还在纯粹依赖提示工程,你可能已经落后了。”ACL 2025举办了首届“REALM”研讨会,将基于强化学习的智能体训练置于其议程的核心——收到的论文提交数量是预期的三倍。ICLR 2025展示了多项突破,包括开源的Agent S框架,它能像人一样操作计算机,并在复杂任务中实现了前所未有的自动化水平。
最值得注意的是,NeurIPS 2024的“开放世界智能体”研讨会由Yann LeCun发表主旨演讲,他强调:“静态知识检索已不再足够——我们需要的是能够在开放式环境中持续学习和适应的智能体。”这一观点在与会者中引起了广泛共鸣;在一次圆桌讨论中,多位图灵奖得主一致认为,强化学习为解决通用人工智能的核心挑战提供了最有希望的途径。
挑战与机遇
现实世界的挑战与产业机遇
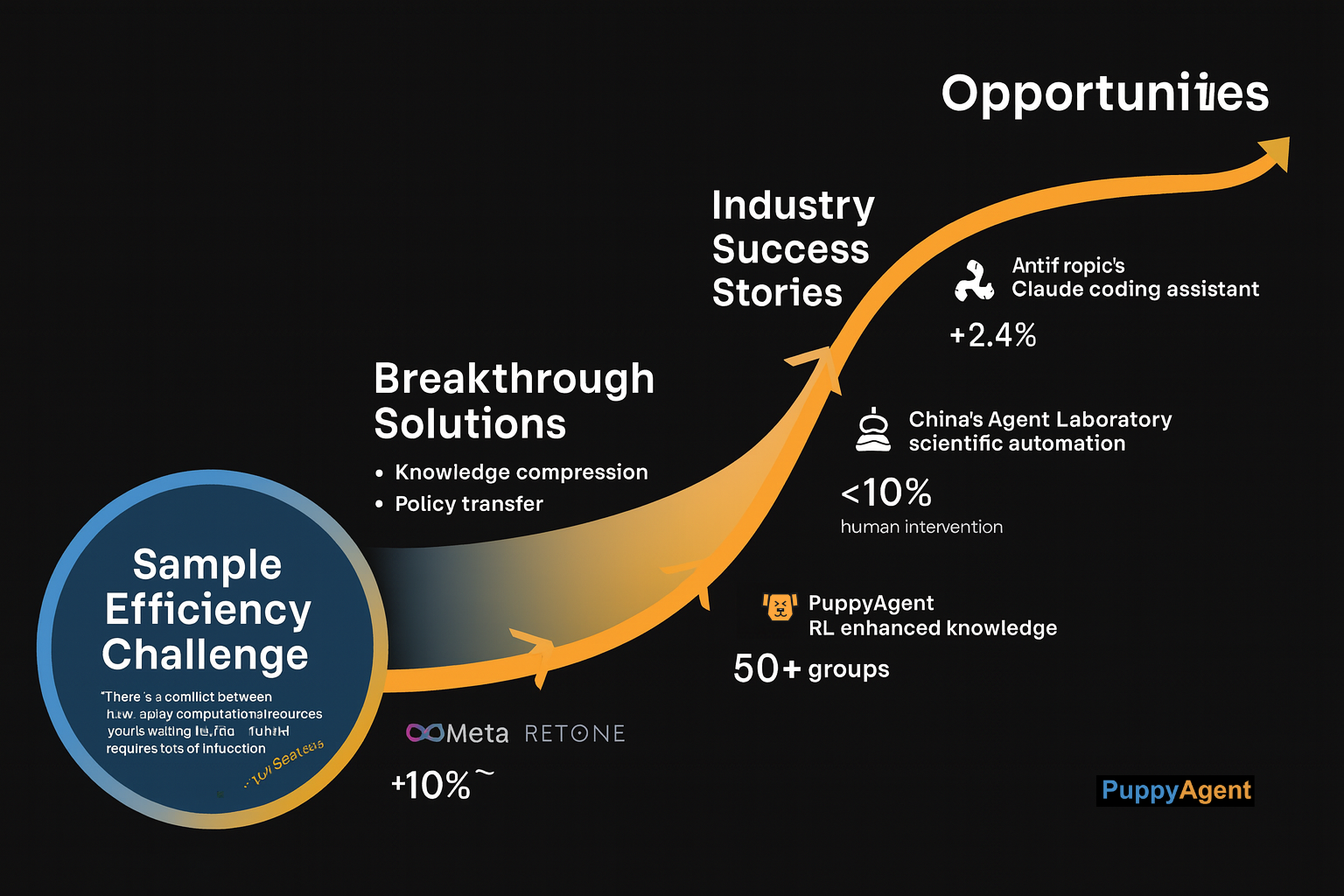
当然,重大挑战依然存在。在离开OpenAI前的最后一次公开演讲中,Ilya Sutskever坦率地承认:“我们最大的困难在于样本效率。每次LLM推理消耗大量计算资源,而传统的强化学习需要数百万次交互。”这一矛盾正在催生新颖的解决方案——例如,Meta的研究团队开发了一种“基于蒸馏的学习”方法,将大模型的知识压缩到小模型中进行强化学习训练,然后将学到的策略传回大模型。
产业界的反应同样迅速。Anthropic的Claude团队目前正在测试一款由强化学习驱动的编码助手;内部人士透露,其在复杂编程任务上的表现“令人惊叹”。与此同时,中国的Agent Laboratory项目已经实现了科研工作流的端到端自动化——从文献综述、实验设计到论文撰写——所需的人工干预不到10%。这种自动化趋势正迅速渗透到更多垂直领域。例如,在知识管理领域,像puppyone这样的智能知识库系统正开始应用强化学习机制于文档理解、知识提取和自动问答。通过不断从用户的查询模式和反馈中学习,这类系统可以迭代优化其知识组织和检索策略——从被动的信息库转变为主动的智能助手。深圳AIRS发布的AIRSTONE开源平台为具身智能研究提供了前所未有的计算支持,并已被超过50个国际研究小组使用。
结论

智能体与强化学习的分离确实存在过——但正如麻省理工学院的Tommi Jaakkola教授恰如其分地指出的,“这就像早期的互联网只有静态网页;动态交互才是真正的未来。”我们正在见证一场根本性的转变:从基于预训练知识的静态推理到通过从经验中持续学习的动态优化。RLVR使智能体能够获得硬技能,如数学推理;LLaRP展示了跨场景的泛化能力;而基于MARL的多智能体系统则揭示了真正协作智能的涌现。
正如DeepMind创始人戴密斯·哈萨比斯最近所说:“强化学习不仅仅是一种训练方法——它是智能本身的核心机制。”这个曾经“被忽视的学科”,凭借其对试错学习、策略优化和环境适应的深刻见解,正成为智能体迈向通用人工智能之路上最坚实的理论基础。这种融合不是技术的简单堆砌——它是一场由基础科学驱动的认知革命。
主要参考文献: ICML 2025教程,ACL 2025 REALM研讨会,Qwen2.5-数学技术报告,LLaRP论文,MAGRPO算法,内心独白及其他最新研究