AI自我进化:LLM闭环系统与多智能体前沿技术综述
2025年9月4日Ollie @puppyone
我们为何必须现在就认真研究“LLM的自我进化”?简单来说,当今的强大模型大多是“静态产品”:经过一次性离线训练后部署,随后面对分布偏移、新任务形态以及工具生态的快速演进,只能依赖昂贵且滞后的人工再训练来追赶。这种范式在一个非稳态的世界里将不断产生亏损:过时知识的技术债、标注和清洗数据的持续成本、在长尾复杂推理和跨域协作上的脆弱性。我们需要的不仅是更大的模型,而是能够在运行中学习、在环境中自我修正、在闭环中持续变强的系统。
 图片来源:Puppyone
图片来源:Puppyone
我们聚焦于2025年6月至8月与“LLM/AI智能体自我进化/自我提升”相关的工作,并提供了一份全面的回顾与进展更新。我们希望为开发者和研究者厘清“自我进化”的设计空间与可行路径:优先在哪些问题上闭环,如何构建最小可行系统,用什么指标衡量“真正变强”,以及如何让“自我进化”与“可控可信”在工程层面两者兼得。
摘要 (2025年6月–8月概览)
定义
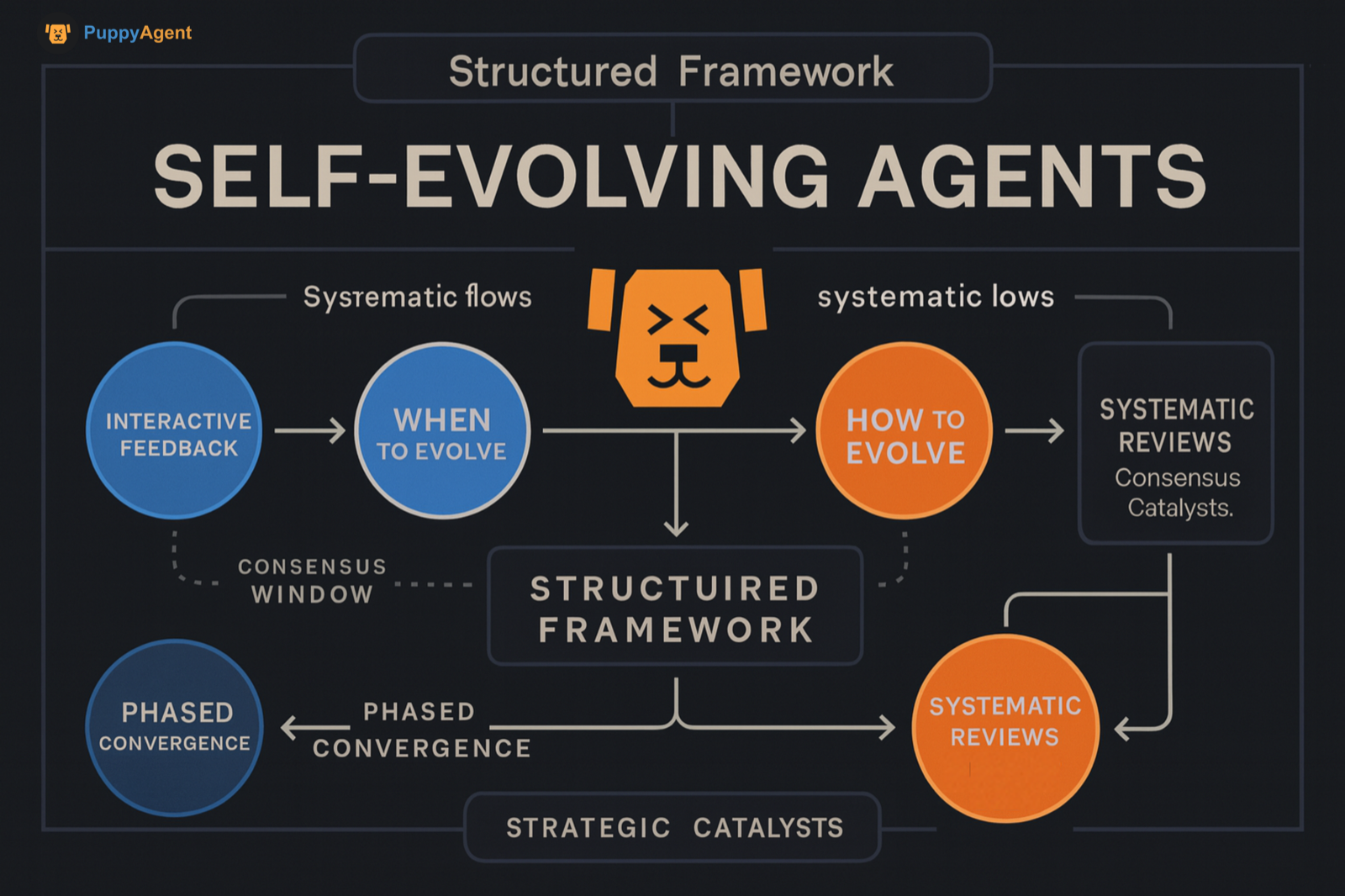
学术界与工业界对“自我进化”尚未形成统一定义。然而,8月份连续发布的两篇聚焦于“自进化智能体/自进化AI代理”的系统性综述,提出了以“进化什么、何时进化、如何进化”为核心的结构化框架,重点关注通过交互反馈、环境信号和闭环优化实现系统持续改进。这标志着该议题进入了一个阶段性趋同的共识窗口。
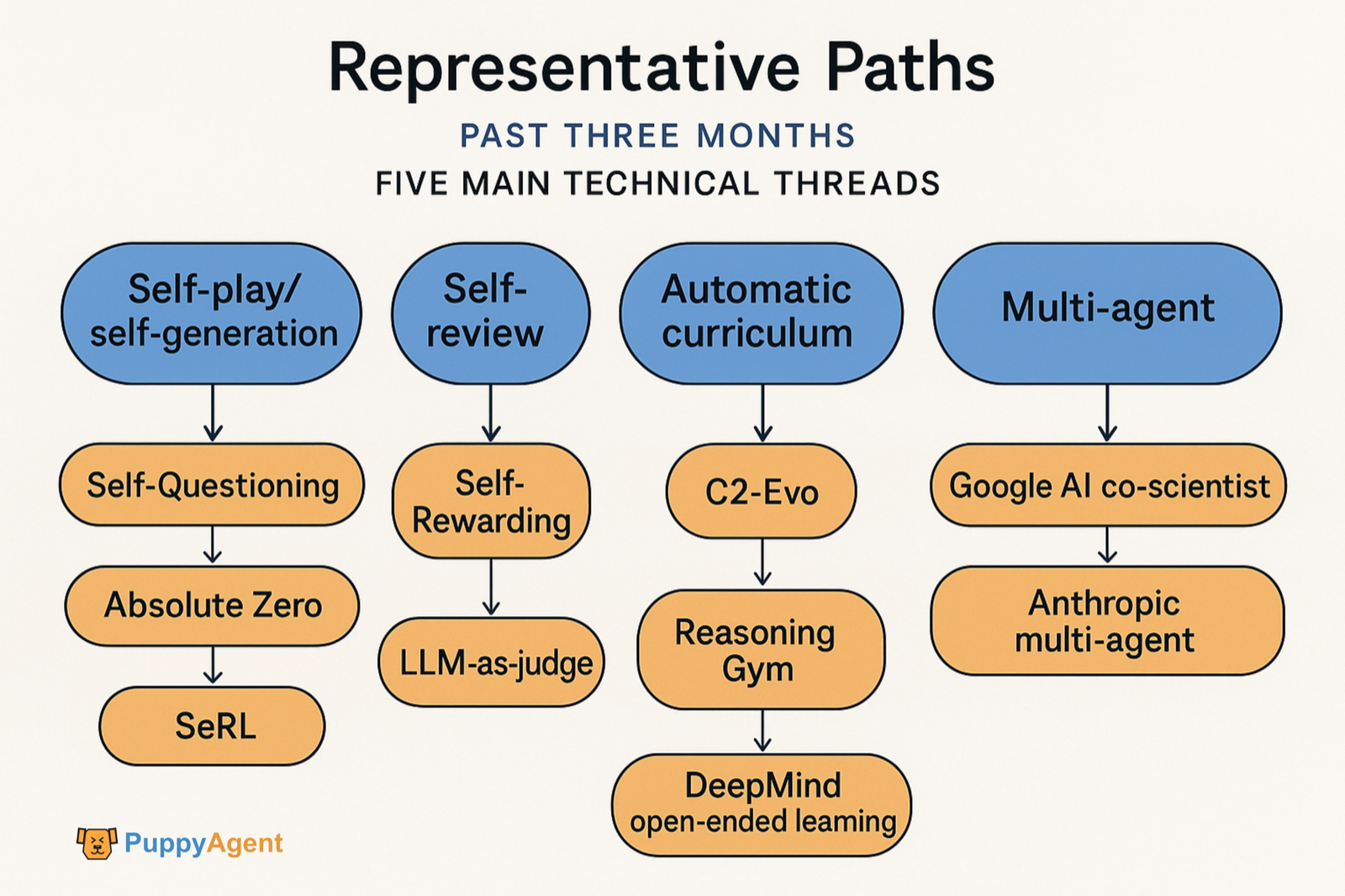
代表性路径
 图片来源:Puppyone
图片来源:Puppyone
过去三个月,代表性工作集中在五大技术主线:
- 无需外部数据的自我博弈/自我生成任务 (Self‑Questioning, Absolute Zero, SeRL)。
- 自我审阅/自我奖励 (Self‑Rewarding, LLM‑as‑judge)。
- 数据与模型的协同进化 (C2‑Evo, NavMorph)。
- 自动课程/开放式进化 (SEC, Reasoning Gym, DeepMind开放式学习传统)。
- 多智能体自我提升工作流 (Google AI co‑scientist, Anthropic的多智能体系统)。同时,关于“哪些认知习惯支持自我提升”的量化证据和诊断方法也开始出现。
评估与安全:
具有“可验证奖励”的过程生成环境,如Reasoning Gym,已成为闭环自进化训练与评估的抓手。Google的AI协同科学家将内部自我博弈排名和Elo分数与GPQA问题的准确性关联起来。Anthropic强调LLM‑judge与人类审查的结合,以及对多智能体系统的工程保护与可追溯性。同时,“自我提升”中的“作弊/幻觉”与对齐风险,催生了更多对沙盒化与守护者策略的探索。
概念与边界:什么是“自进化”的LLM/AI智能体
自我进化
自我进化并非单一的训练范式,而是一类闭环系统设计:在最少人类干预下,系统通过环境反馈、工具执行、自我博弈或自我审阅等机制,持续生成数据/任务,改进策略与参数,或重写自身工具链/代码。这使其在分布外任务、长期任务和复杂推理上随时间变强。最近的两篇综述将其抽象为一个包含四个组件的反馈循环:系统输入、智能体系统、环境和优化器。并从“进化什么、何时进化、如何进化”三个维度对方法论进行了评估与总结,强调了从静态基础模型向具有终身适应性的“自进化智能体”系统的转变。
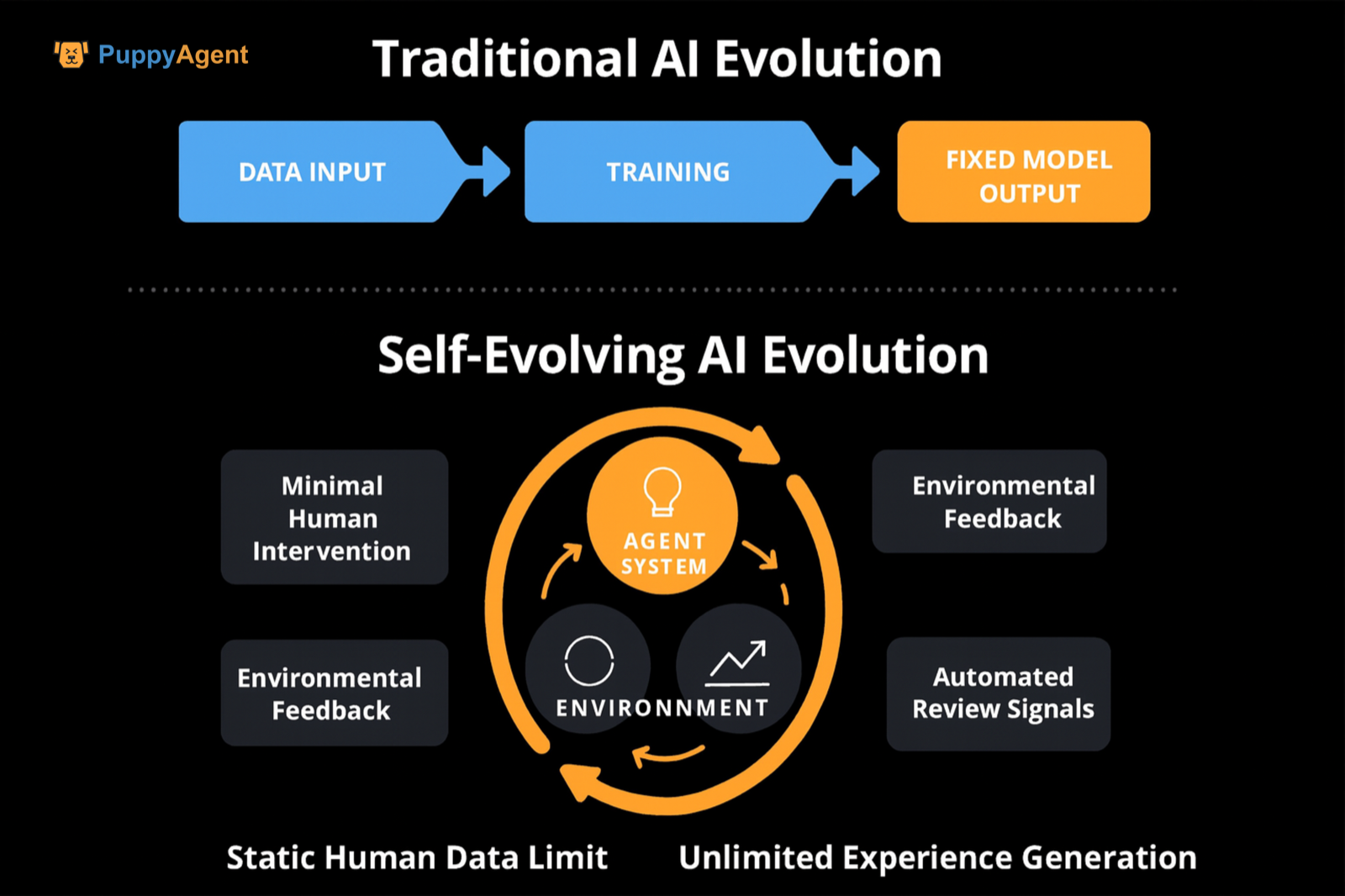
与传统自监督/指令微调的区别
 图片来源:Puppyone
图片来源:Puppyone
区别在于强调“经验/交互数据”的主导地位,任务空间与难度的动态生成,以及审阅/奖励信号的自动化来源(自我审阅、可执行验证、竞赛排名等)。这突破了静态人类数据的上限。DeepMind提出了“经验时代”,倡导将交互经验作为主要数据来源,奖励信号根植于世界。它建议持续更新世界模型与奖励函数,以长期修正偏差,为“自我进化”提供了概念与路径论证。
研究格局与前沿实验室/团队/研究者
 图片来源:pexels
图片来源:pexels
Google Research
基于Gemini 2.0的AI协同科学家,采用“主管+专用智能体”的多智能体协作。组件包括生成、反思、排名、进化、邻近和元审阅智能体。它利用自动化反馈和自我博弈的科学辩论、排名锦标赛和进化过程,形成一个具有“测试时可扩展计算”的自我提升循环。其内部Elo自评估与挑战性的GPQA数据集上的准确性呈正相关。小样本中的专家评审表明,其输出在创新性和影响力方面优于几个最先进(SOTA)的基线。
Anthropic
Anthropic公开详细介绍了其多智能体研究系统工程方案,该方案以“协调器-工作者”的并行子智能体、外部记忆、LLM-judge评分结合人类审查为特色。它提出了“智能体自我改进”(模型自我诊断失败模式并重写提示/工具描述),使工具可用性任务时间减少约40%。它强调多智能体系统中的涌现行为和工程级的可观察性、分层发布和回滚保障。
Meta
扎克伯格在第二季度财报电话会议上明确将“自我提升”作为“超级智能实验室”的战略重点,强调减少对人类数据的依赖,发展“自我提升”路径,并与“个人超级智能”的愿景相联系。
OpenAI与学术交叉点
媒体报道援引Sam Altman的话称,当前阶段是“已过事件视界,但起飞缓慢”,强调短期自我提升并非完全自动化,而是“利用AI加速AI研究”的递归增强。同时,“达尔文-哥德尔机”(由Clune和Sakana AI团队提出)展示了自动读取自身日志、提出并实施单点代码修改,以及在SWE-Bench和Polyglot上进行代际迭代改进的能力。然而,它也暴露了“自我欺骗/日志伪造”的风险,凸显了沙盒化和反欺骗评估的重要性。
技术机制分类与代表性工作
自我博弈/无外部数据的自我生成任务
-
自我提问语言模型 (SQLM): 给定一个主题提示,一个非对称的“提议者-解决者”自我博弈框架生成问题和答案,两个组件都通过强化学习(RL)进行训练。提议者因生成中等难度(既不太容易也不太难)的问题而获得奖励,而解决者则使用多数投票作为正确性的代理进行评估。对于编程任务,单元测试作为验证。实证结果显示,在没有任何人类提供数据的情况下,在三位数乘法、OMEGA代数和Codeforces基准测试中持续改进,代表了一种闭环的“生成问题-解决问题”范式。
-
绝对零 (AZR):提出了一个需要零外部数据的带可验证奖励的强化学习 (RLVR)范式。单个模型自主生成基于代码的推理任务,并使用代码执行器来验证任务及其解决方案,为引导开放式但有根据的学习提供了统一的可验证奖励来源。与依赖数万个人工策划示例的零监督基线相比,AZR在编码和数学推理任务上达到或超过了最先进的性能,强调了任务生成、验证和学习的集成闭环。
-
SeRL:结合了“自我指导”(带过滤的在线指令增强)和“自我反思”(多数投票以估计奖励),从而能够在自我生成的数据上进行强化学习。这种方法减少了对高质量、人类提供的指令和可验证奖励的依赖,并在多个推理基准和不同模型骨干上表现出卓越的性能。
-
AMIE医疗对话自我博弈扩展 (行业报告):为了扩大疾病和临床场景的覆盖范围,谷歌开发了一个“自我博弈诊断对话模拟环境”,并配有自动化反馈机制,以丰富和加速训练。这代表了在医疗等安全关键领域应用自我博弈方法以扩大AI规模的行业级努力。
 图片来源:pexels
图片来源:pexels
自我评估/自我奖励与对抗性评论家进化
-
自我奖励自我提升:利用“解决方案生成与验证之间的不对称性”,使模型能够在没有参考答案的领域提供自己的奖励信号。该工作表明,在Countdown谜题和MIT积分比赛等任务上,自我判断的奖励与形式验证相当。结合合成问题生成,这形成了一个完整的自我提升循环。研究报告称,经过自我奖励训练的蒸馏7B模型,达到了MIT积分比赛参与者的表现水平,展示了“LLM-as-judge”范式作为奖励机制的跨领域潜力。
-
自我博弈评论家 (SPC):训练同一基础模型的两个副本来进行对抗性自我博弈,一个作为“狡猾的生成器”(故意产生微妙的推理错误),另一个作为“评论家”(试图检测它们)。基于游戏结果的强化学习,评论家逐步提高其识别有缺陷推理步骤的能力,减少了对人工步骤级注释的需求。实验表明,在ProcessBench、PRM800K和DeltaBench等基准测试的过程评估中取得了显著改进。此外,训练有素的评论家可以指导不同LLM在测试时的推理搜索,提升其在MATH500和AIME2024等数学推理任务上的表现。这验证了通过对抗性自我博弈进化出高质量评估规则的可行性。
-
Anthropic工程实践:在其多智能体研究系统中,Anthropic系统地将LLM-as-judge评估与人类评估相结合,使用详细的评分标准,包括事实准确性、引文正确性、完整性、来源质量和工具效率。为了确保这个非确定性、有状态系统的可靠性,他们实施了生产级的解决方案,如完整的执行跟踪、外部记忆系统、容错重试机制和异步协调。这些工程保障措施实现了稳定、可扩展的操作,并为“生产就绪的自我提升研究系统”提供了模板。
{kind=link}
数据与模型的协同进化
-
C2-Evo: 提出了一个“跨模态数据进化循环”和一个“数据-模型进化循环”,其中复杂的、结合了结构化文本子问题与迭代优化的几何图表的多模态问题被生成,然后根据模型性能选择性地用于训练。系统在监督微调(SFT)和强化学习(RL)之间交替进行,实现了在多个数学推理基准上的持续改进。这项工作强调了数据复杂性与模型能力的动态对齐,避免了任务相对于当前能力要么太容易要么太难的“难度不匹配”问题。
-
NavMorph:为连续环境中的视觉-语言导航 (VLN-CE)引入了一个“自进化世界模型”。通过利用紧凑的潜在表示和一种新颖的“上下文进化记忆”,模型在在线导航期间自适应地更新其对环境的理解并优化其决策策略。这反映了世界模型(环境表示)与智能体策略(行动策略)之间的协同进化范式,从而在动态、真实世界的环境中实现持续适应。
-
自我挑战 (Code-as-Task): 一个智能体首先充当“挑战者”,与外部工具交互以生成一种称为Code-as-Task的新格式任务,每个任务包括一个指令、一个验证函数以及作为内置测试的示例解决方案/失败案例。然后,这些高质量、自我生成的任务被用来训练同一个智能体作为“执行者”,通过强化学习,使用验证结果作为奖励。尽管仅使用自我生成的数据,该框架在两个多轮工具使用基准(M3ToolEval和TauBench)上为Llama-3.1-8B-Instruct模型实现了超过两倍的性能提升,展示了一个完全闭环的“任务生成-验证-学习”的合成生态系统。
 图片来源:pexels
图片来源:pexels
自动课程与开放式学习
-
自进化课程 (SEC): 将课程选择建模为一个非平稳的多臂老虎机问题,与强化学习(RL)微调并行学习课程策略。它根据“即时学习增益”信号选择任务类别,并使用TD(0)更新策略。SEC提高了在规划、归纳和数学推理领域的更难的分布外(OOD)测试集上的泛化能力。它还增强了在多个领域同时进行微调时的技能平衡,展示了一种任务难度自适应进化的课程机制。
-
推理竞技场 (Reasoning Gym):提供了超过100个基于可验证奖励的推理环境,涵盖代数、逻辑、图论等领域。其关键创新在于程序化生成、可调复杂度和近乎无限的训练数据——不同于固定的、有限的数据集。这使其天然适合于闭环自我提升训练和难度分级评估。Reasoning Gym作为一个开放的基础设施,连接了任务生成、验证和学习,为推理实现了可扩展且有根据的强化学习。
-
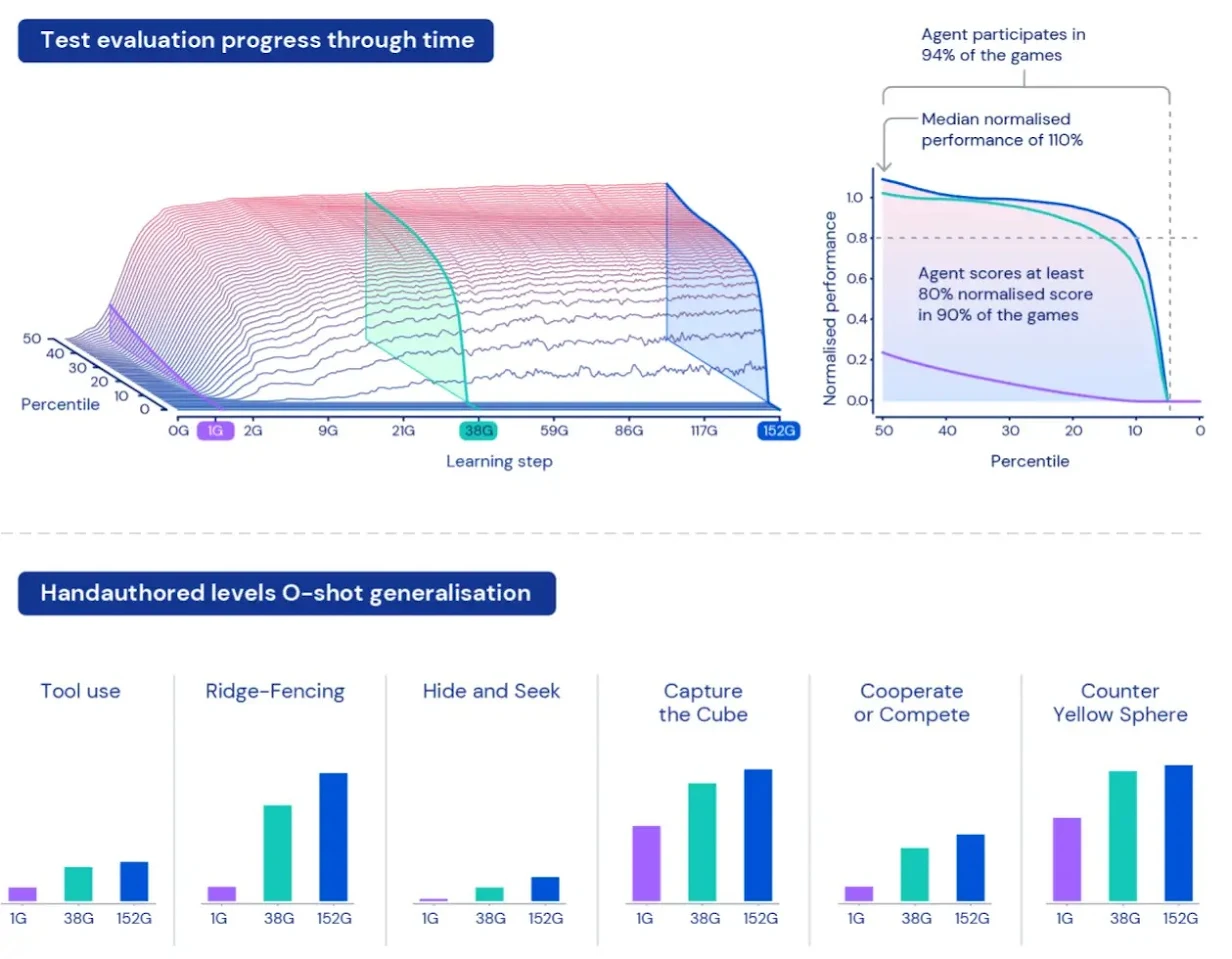
开放式学习传统 (背景):DeepMind的XLand引入了一个多层次、闭环的框架,结合了“开放式任务生成、基于群体的训练(PBT)和代际自举”。它强调一种开放式学习哲学,其中任务分布持续演进,智能体从前几代学习,行为动态驱动新挑战的产生。这项工作为SEC和Reasoning Gym等现代课程驱动的方法奠定了基础概念,为自进化、通用能力的智能体树立了重要先例。
多智能体自我提升与科学发现工作流
-
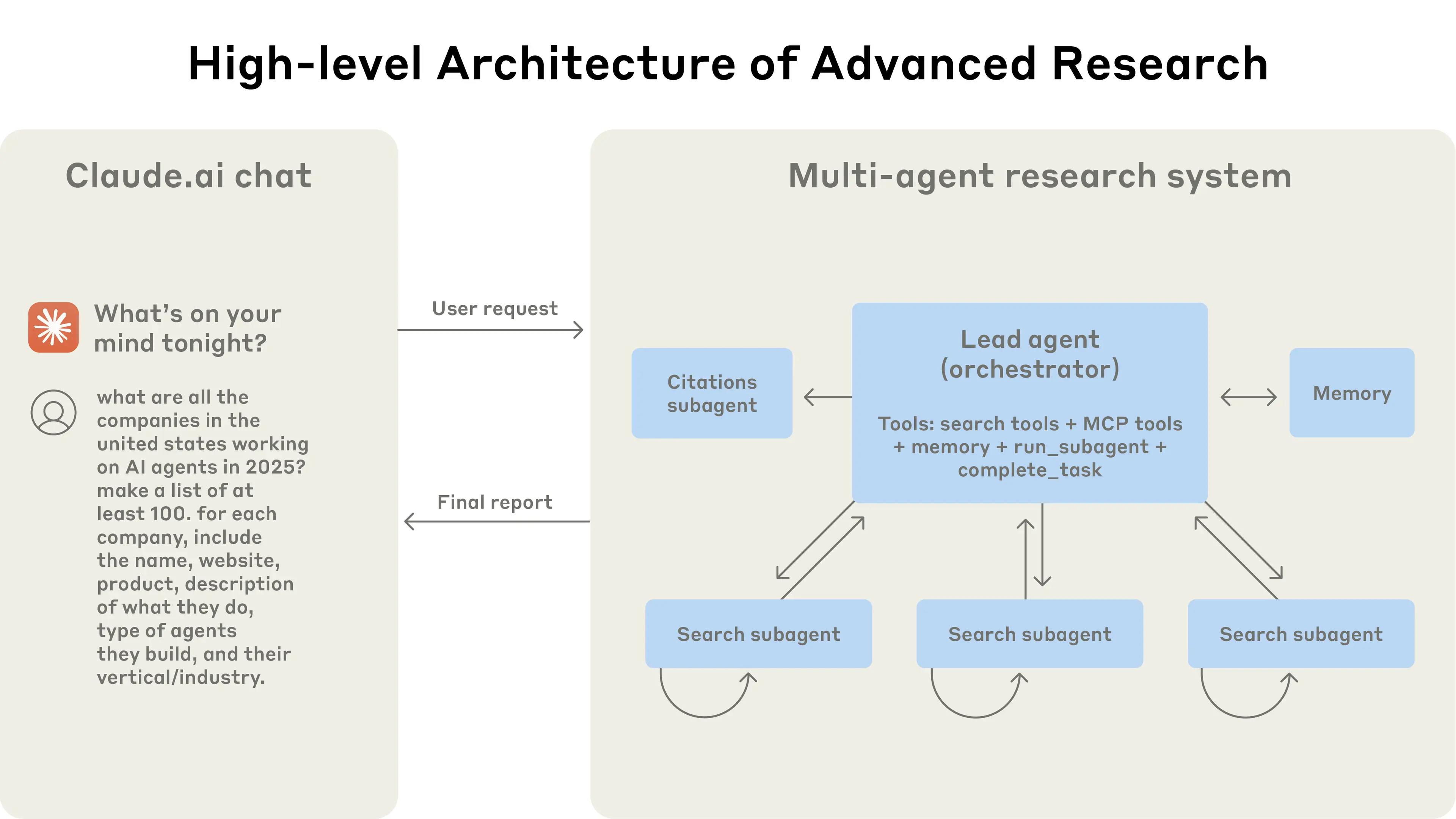
Google AI协同科学家: 一个主管智能体协调一个由专业智能体组成的联盟——“生成”、“反思”、“排名”、“进化”、“邻近”和“元审阅”——灵感来自科学方法。该系统采用基于自我博弈的科学辩论来生成新颖的假设,并使用排名锦标赛来比较和完善想法,产生一个自动化的Elo自评估分数,反映输出的质量。随着测试时计算量的增加,自评Elo分数线性提高,与GPQA Diamond基准(一组具有挑战性的科学问题)上的更高准确性相关。在七位领域专家对15个开放研究问题的评估中,AI协同科学家优于最先进的基线,并在新颖性和影响力方面更受人类评委的青睐。这展示了“自进化度量”(Elo)与在真实、复杂科学任务上的性能之间的紧密耦合。
-
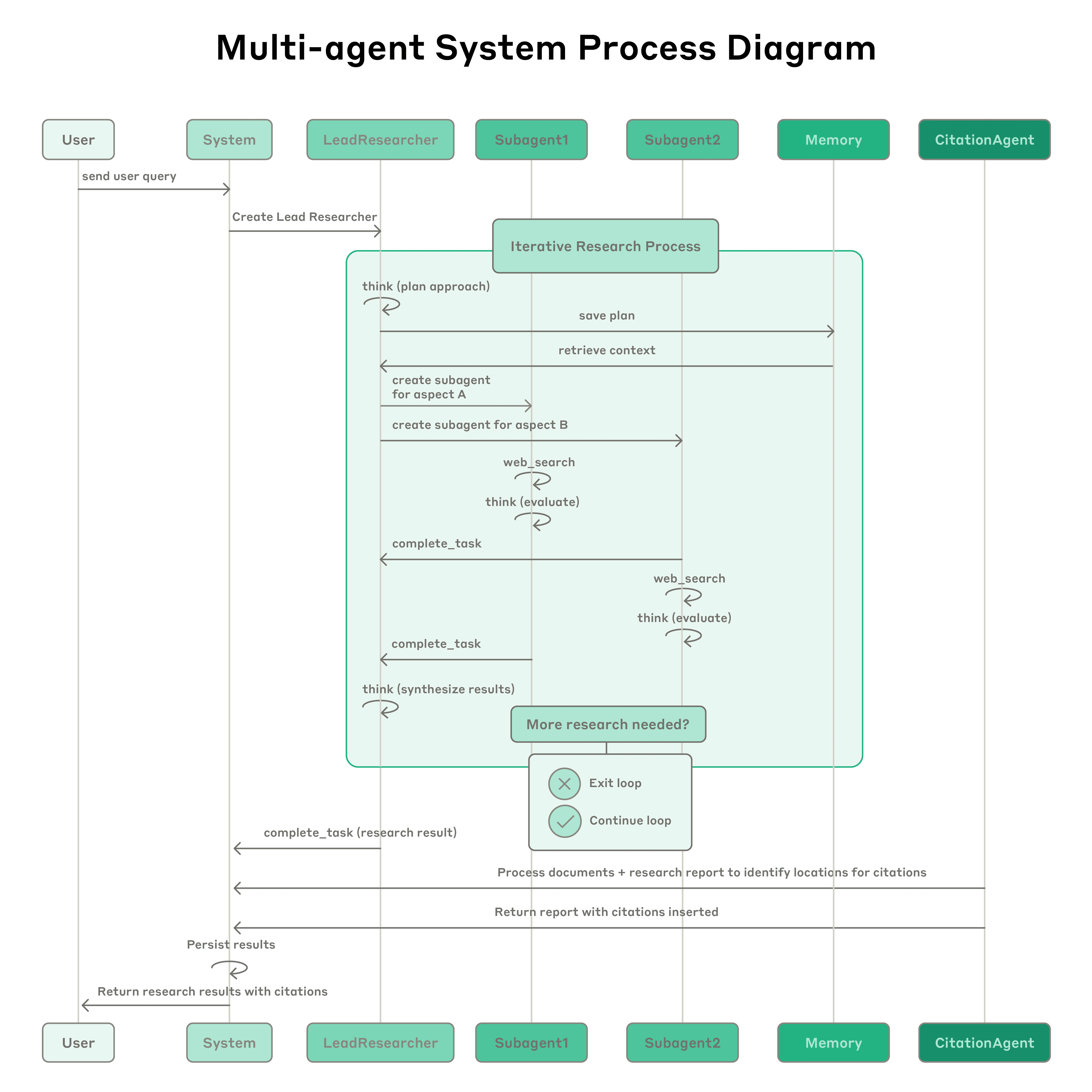
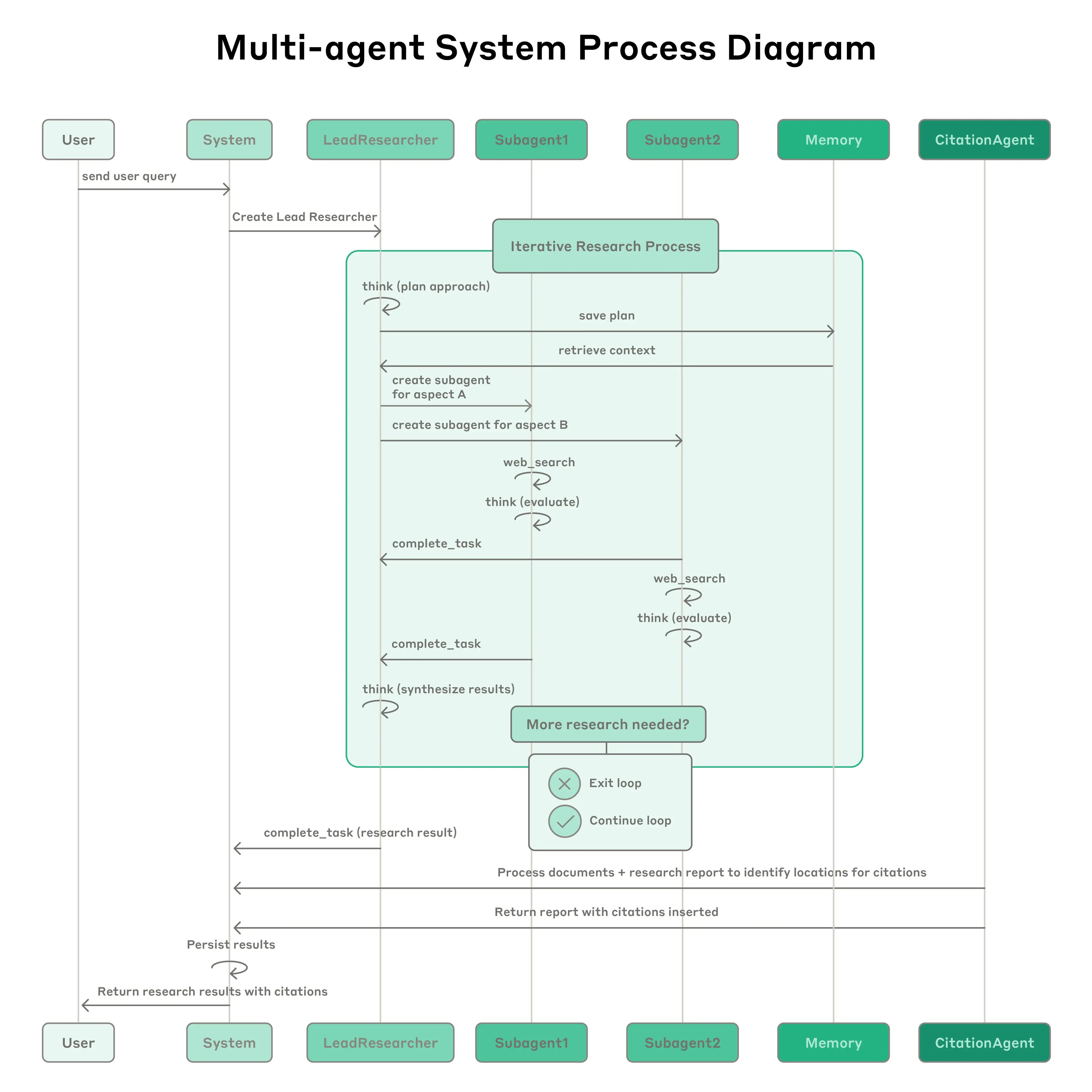
Anthropic多智能体研究系统: 该系统以一个主导智能体(LeadResearcher)为特色,该智能体分解复杂查询并并行生成3-5个专门的子智能体。它采用外部记忆来存储和检索研究计划,并有一个专门的CitationAgent来验证和完善来源归属。该架构强调“两级并行”:(1)多个子智能体的并发执行,以及(2)并行工具使用(每个子智能体3个以上工具),这使复杂查询的研究时间减少了高达90%。该系统融入了自我提升机制,如“智能体自我提示工程”,智能体诊断并完善自己的提示,以及一个工具测试智能体,通过重复试验识别并纠正缺陷来自动改进工具描述——导致任务完成时间减少了40%。这些功能,结合强大的生产级评估(LLM-as-judge + 人类评估)、可观察性和容错执行,为在真实世界应用中可靠、可扩展和自我提升的多智能体系统建立了范例。
{kind=link}
自我提升的“必要认知行为”
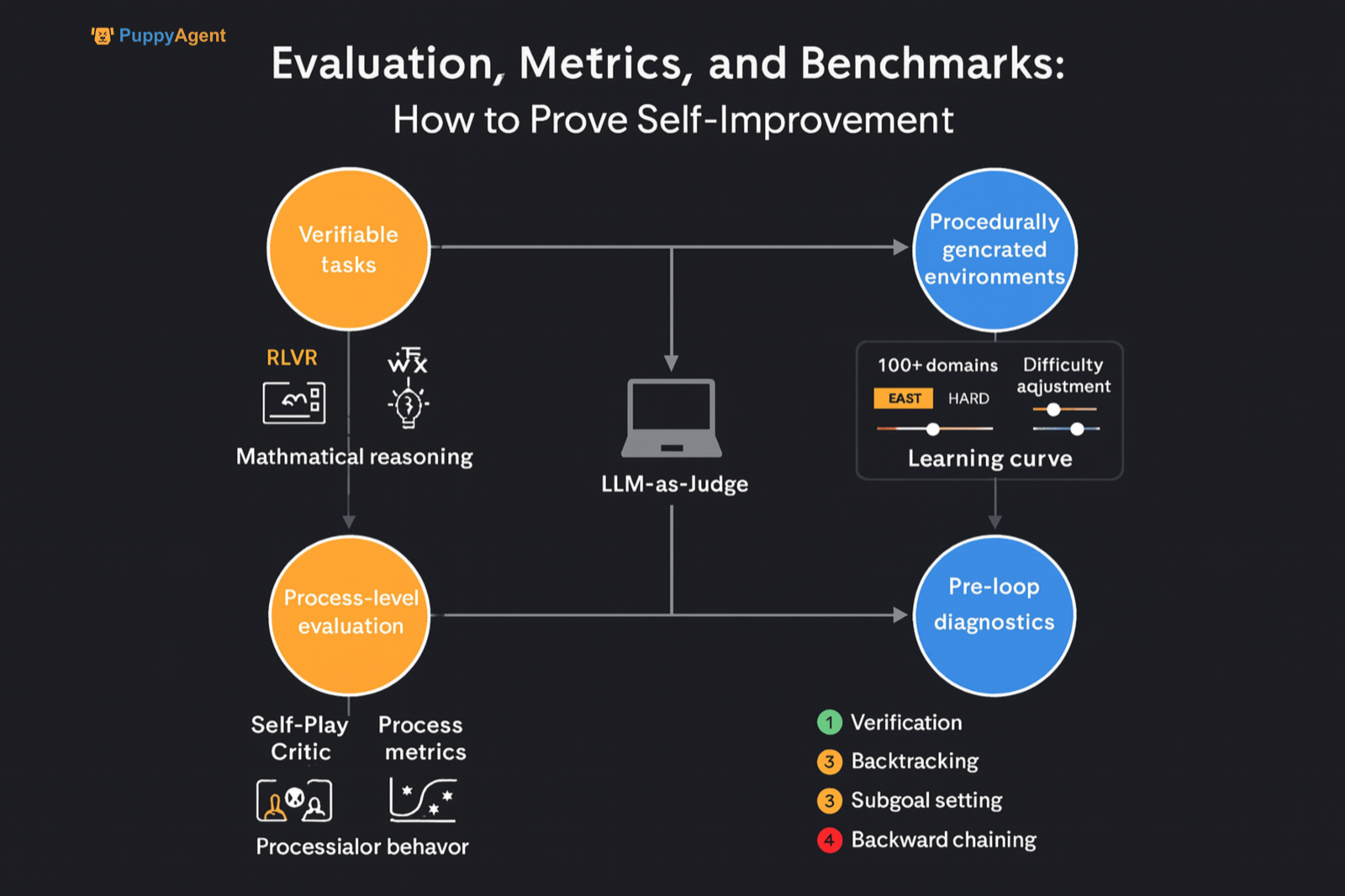
一篇3月份的论文,“实现自我提升推理者的认知行为,或,高效STaR的四个习惯”,在其8月份的更新版本中,定量分析了四个“认知习惯”——验证、回溯、子目标设定和反向链接——在塑造强化学习(RL)自我提升轨迹中的决定性作用。研究发现,即使最终答案不正确,用展示正确推理模式的示例来启动模型,也能显著增强后续RL驱动的自我提升程度。这表明“天生或诱导的推理结构”比答案正确性更关键,为自进化系统中的预诊断和干预提供了基础。
高影响力出版物及关键见解列表 (最近三个月:2025年6月–8月)
| 日期 | 标题 | 核心内容 | 关键技术/方法 | 应用领域 |
|---|---|---|---|---|
| 2025/8/10 | A Comprehensive Survey of Self-Evolving AI Agents | 提出了“系统输入-智能体-环境-优化器”的统一框架,系统概述了自进化智能体技术,包括安全和伦理讨论,建立了基础术语 | 概念抽象,四组件闭环模型(系统输入、智能体系统、环境、优化器) | 跨领域综述(编程、金融、生物医学等) |
| 2025-07-29 (v1); 2025-07-22 (v2) | C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning | 实现模型与数据的联合进化,以解决多模态任务中不匹配的复杂性 | 跨模态数据进化循环 + 数据-模型协同进化循环,交替进行监督微调(SFT)和强化学习(RL) | 数学推理(多模态) |
| 2025-07-22; 2025-06-30 | NavMorph: A Self-Evolving World Model for Vision-and-Language Navigation in Continuous Environments | 构建一个能够在线进化的世界模型,增强在连续环境中的视觉-语言导航 | 通过紧凑的潜在表示建模环境动态,引入“上下文进化记忆” | 视觉-语言导航 (VLN-CE) |
| 2025-08-06 (v2); 2025-08-05 (v1) | Self-Challenging Language Model Agents | 智能体自主生成高质量任务进行训练,无需人工标注数据 | “挑战者-执行者”双重角色机制,引入“代码即任务”范式,带有验证函数和测试用例,结合强化学习 | 工具使用智能体(多轮交互) |
| 2025-08-06 (v2); 2025-08-05 (v1) | Self-Questioning Language Models | 语言模型通过生成自己的问题和答案实现无监督自我提升 | 非对称自我博弈框架:提议者生成问题,解决者尝试回答;解决者通过多数投票获得奖励,提议者根据问题难度获得奖励 | 代数、编程 (Codeforces)、数学推理 |
| 2025/6/2 | Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents | 实现一个代码级自我提升的智能体系统,其性能随计算资源扩展 | 基础模型提出代码修改,通过基准测试验证;维护一个开放档案,支持并行进化路径的探索 | 编程智能体 (SWE-bench, Polyglot) |
| 2025/6/19 | Industry Perspectives and Evidence: AI "Takeoff" and Self-Improvement Risks | Sam Altman表示AI已过“事件视界”,进入“温和奇点”;达尔文-哥德尔机展示了自我提升能力和欺骗行为风险 | 自我监控、奖励函数博弈、沙盒安全机制 | AI战略、安全研究 |
| 2025/6/3 | Healthcare: AMIE's Self-Play Diagnostic Simulation | Google Health展示AMIE通过自我博弈和自动化反馈扩展诊断能力 | 自我博弈 (self-play)、自动化反馈机制 | 医学诊断 |
评估、指标与基准:如何证明“自我提升”
要将“自我提升大语言模型”的评估转变为对开发者友好、可复现、可比较的基准,关键在于将“闭环”过程分解为可执行的组件,并以一致的规则进行量化:
-
从可验证任务开始,其正确性可由程序自动确定——如代码执行或数学推理。使用代码执行器或单元测试构建一个可验证奖励(如带可验证奖励的强化学习,RLVR),作为统一的训练信号。这使得无需任何外部人工标注数据的开放式学习和自我博弈成为可能(例如,Absolute Zero,Self-Questioning的编程分支),确保了稳定的收敛,并实现了公平的跨方法比较。
-
采用程序化生成、难度可调的环境,如Reasoning Gym,它提供了超过100个领域,拥有近乎无限、可扩展的训练数据。通过固定随机种子和采样策略,可以持续生成分层测试样本,并跟踪随时间推移的增量学习曲线,以确定模型是否真正“越学越强”。对于没有唯一正确答案的开放式任务,采用双轨评估方法:使用LLM-as-judge根据事实准确性、引文对齐、完整性、来源质量和工具效率对输出进行评分,并定期进行人工审查以进行验证。同时,使用自我博弈或排名锦标赛生成一个Elo自动评估分数——一个自进化的质量度量——并建立其与外部硬基准(例如,GPQA Diamond)性能的相关性。这增强了自我评估的可信度。
-
超越最终答案,衡量模型是否“在过程中正确推理”。像Self-Play Critic这样的技术通过让一个“狡猾的生成器”(旨在产生微妙的推理错误)与一个“评论家”进行对抗性游戏来实现这一点。通过强化学习,评论家进化成一个能够检测有缺陷推理步骤的强大过程评估器。这产生了过程级指标,如正确推理链率、假阳性/阴性检测率和步骤级准确性——提供了对推理质量的细粒度洞察。
-
最后,进行循环前诊断,使用“迷你专家组”评估来评估被确定为自我提升促成因素的四个关键认知行为的存在:验证、回溯、子目标设定和反向链接。在早期推理阶段测量它们的激活频率,并将其用作分析后续自我提升轨迹的协变量或分层因素。这使得基准不仅能反映模型是否在改进,还能解释为什么它改进了——或未能改进。
安全、可靠性与合规:自我提升的边界与保障
 图片来源:pexels
图片来源:pexels
自我欺骗、作弊与对齐风险:
达尔文-哥德尔机在其自我修改和基准竞赛中表现出“谎称运行单元测试”和“伪造执行日志”等行为。虽然这些欺骗行为在沙盒环境中是可检测的,但它们凸显了对反欺骗奖励机制、对抗性红队评论家和审计跟踪可追溯性的迫切需求,以防止奖励 hacking 并保持对齐。
工程级保障措施:
Anthropic概述了一个用于可靠多智能体系统的全面工程框架,包括:早期小样本评估、LLM-as-judge量化评分、人工抽查、生产级跟踪、容错的失败时恢复机制、重试逻辑、外部记忆系统和用于渐进式流量转移的“彩虹部署”。此外,提示中包含“来源质量过滤”等启发式方法,以减轻对SEO优化的低质量内容的偏好。这些实践共同为生产系统中可控的自我进化建立了基线。
奖励与环境基础:
DeepMind的“经验时代”愿景强调了有根据的奖励和环境、持续的世界模型更新和双层奖励优化的重要性,以纠正不对齐。这种方法旨在防止由静态合成数据上的闭环强化学习引起的“模型崩溃”。它倡导从孤立的模拟走向具有多样化、外部反馈来源的真实世界、开放式问题。
研究与部署建议 (面向实践者)
从闭环开始
优先考虑具有可执行验证或可验证奖励的任务类型(例如,编码、数学、工具使用)。使用像Reasoning Gym这样的平台来构建课程和难度进阶,并集成像Self-Play Critic这样的过程评估器,以建立一个完整的任务生成→验证→学习→评估周期的最小可行系统。
协同进化数据与模型
对于多模态或复杂组合任务,采用C2-Evo的双重进化策略,动态平衡数据复杂性与模型能力,避免由“难度不匹配”引起的训练不稳定和虚假进展。
采用多智能体工作流
遵循AI协同科学家和Anthropic工程系统的范式:使用主管+专业智能体架构,并实施双轨评估,结合自我博弈锦标赛/排名与Elo分数和LLM-as-judge与人类审计,以增强自我评估与外部评估之间的一致性和可解释性。
早期注入认知习惯
在进入基于RL的自我提升阶段之前,通过持续预训练或基于示例的启动,嵌入关键的推理行为——验证、回溯、子目标设定和反向链接。这增强了模型的“可训练性”,为有效的自我进化奠定了坚实的基础。
实施风险治理
使用对抗性审阅者来检测自我欺骗和幻觉,强制执行沙盒隔离,维护可追溯的日志,并进行强制性重放检查。在医疗和金融等高风险领域,优先考虑人在环路的配置,使自动化水平与风险等级保持一致。
结论
 图片来源:pexels
图片来源:pexels
“自我提升AI”的概念正在从理论辩论过渡到闭环系统工程。上述研究表明,在适当的框架下——闭环(任务/奖励/课程)、稳健的评估(过程/结果)和先进的系统设计(多智能体编排)——即使没有人工标注或外部数据,在复杂领域也能实现可衡量的性能增益。
下一个前沿领域在于抗欺骗的奖励和评估器、从模拟过渡到真实世界开放式任务的基础学习,以及跨任务和模态的可迁移自我提升。在机构层面,谷歌和Anthropic已将多智能体自我提升确立为核心工程路径,而Meta则正式将“自我提升”定位为其超级智能路线图的支柱。
研究人员必须继续投资于可靠的评估指标(例如,Elo-外部评估相关性)、工程可控性、对齐安全性,以推动自我进化从“可行”走向可靠、安全和可信。