Hybrid Indexing & Structured Know‑How for Dev Velocity
2026年3月20日Ollie @puppyone
混合索引与结构化 Know‑How:加速 PR 合并的开发者 RAG
开发者速度停滞并不是因为人们忘记了如何编码。当团队无法找到、信任或复用代码库和文档中已有的知识时,速度就会减慢。这就是知识熵:ADR 散落在 wiki 中,API 合约埋在 PDF 里,所有权因组织变动而丢失。检索增强生成 (RAG) 可以提供帮助,但前提是它必须建立在既具有语义性又具有确定性的检索骨干之上。这就是在结构化 Know‑How 上进行混合索引改变 PR 合并和更安全重构游戏规则的地方。
核心要点
- 混合索引 + 结构化 Know‑How 减少了幻觉,并产生精确、可审查的引用,从而加快 PR 审查。
- 将面向开发者的 RAG 视为一个工程系统:衡量 precision@k、引用准确率、合并时间 (time‑to‑merge) 和回滚率。
- 使用混合检索器(稀疏词法 + 稠密向量 + 结构化/图谱键)来回答带有准确文件路径和 ADR ID 的代码库问题。
- 从微工作流开始:带有引用的 PR 描述助手和基于 ADR/所有权的重构顾问。
- 优先选择私有/本地部署、嵌入前的密钥脱敏,以及对任何写入建议的人工干预关口。
开发者 RAG——哪些有效,哪些失效
RAG 将 LLM 与从代码、文档和设计历史中获取证据的检索器配对。成功时,开发者会获得有根据的摘要和带有来源的 PR 文本草稿。失败时,你会得到自信的错误答案,信任随之崩溃。
需要注意的失败模式:
- 仅文本向量会遗漏精确标识符(ADR‑1234、函数名),返回看似合理但错误的片段。
- 过度检索淹没提示词;审查者看到的是噪音而非信号。
- 没有引用意味着没有信任;审查者必须重新进行搜索。
最佳实践修复借鉴了详尽的指南:语义分块、混合检索和重排序。有关简明的架构概述,请参阅 InfoQ 文章中关于 RAG 流水线的生产导向模式,该文章强调了检索组合和评估,而非魔术般的提示词 (InfoQ — Effective Practices for Architecting a RAG Pipeline)。对于 CI 时的智能体开发者工作流,GitHub 对持续 AI 的讨论展示了助手如何在环节中起草和验证产物 (GitHub Blog — Continuous AI in practice: agentic CI for developers)。
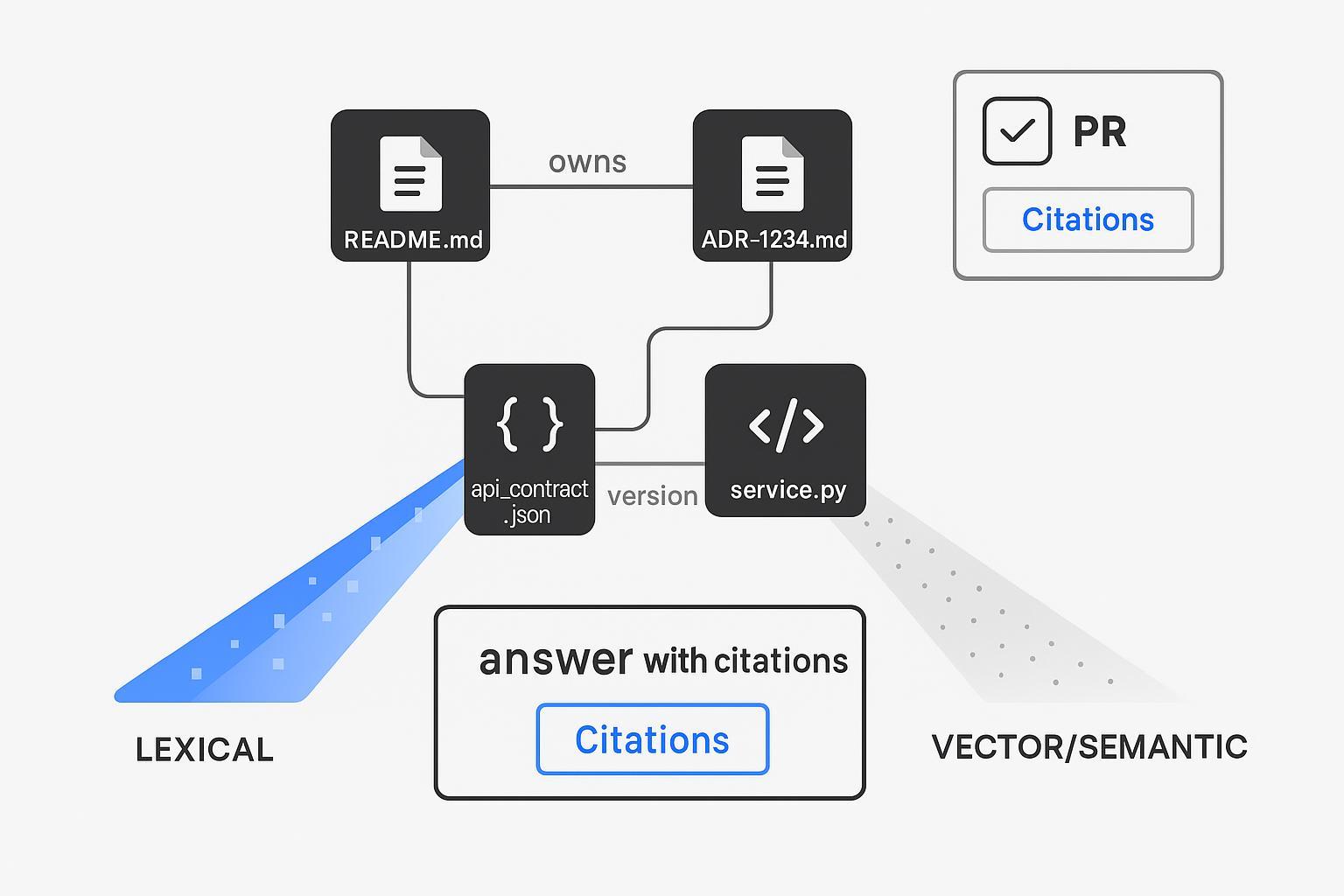
结构化 Know‑How + 混合索引作为检索骨干
仅靠文本无法支撑你的开发者工作流。显式建模企业 Know‑How,并跨文本和结构进行检索。
最小 Know‑How 模式(示例):
{
"type": "adr",
"adr_id": "ADR-1234",
"title": "Deprecate legacy payment gateway",
"status": "accepted",
"decision": "Move to PayFast v3",
"owners": ["@payments-core"],
"links": {"repo_paths": ["/services/payments"], "docs": ["/docs/payments/adr-1234.md"]},
"supersedes": ["ADR-0899"],
"date": "2025-11-06",
"version": "1.2"
}
混合检索器设计(概览):
- 词法:精确过滤(repo_path:/services/payments, file:*.md),针对标识符的 BM25。
- 稠密:针对释义和意图的代码/文档嵌入。
- 结构化:通过键(adr_id, owner, module)进行确定性连接,以提取正确的文件/所有者。
- 可选:使用交叉编码器 (cross‑encoder) 进行重排序以确保忠实度。
这种模式反映了关于混合搜索的供应商和社区指南——稠密 + 稀疏融合以及可选的重排序,正如 Qdrant 的混合搜索工程资源所记录的那样 (Qdrant — Hybrid Search Revamped;Qdrant Docs — Hybrid Queries)。其结果是一个可以引用准确文件路径和 ADR ID 的检索层,而不仅仅是“某种类似的东西”。这就是审查者需要的信任杠杆。
加快 PR 进度的微工作流
- 带有引用的 PR 描述助手
目标:根据 diff 和本地 Know‑How 起草有根据的 PR 正文。
核心步骤:
- 将分支/PR 标题扩展为查询变体。
- 从以下渠道检索 top‑k:(a) 变更路径(词法过滤),(b) 语义相似的文档/片段,(c) 结构化键(ADRs/所有者)。
- 生成一个始终包含带有永久链接的“引用 (Citations)”区块的 PR 正文。
示例 PR 正文模板:
#### Summary
- Implements PayFast v3 retry policy in /services/payments/retry.go
#### Rationale
- Aligns with ADR-1234 (Deprecate legacy payment gateway). See details below.
#### Impact
- Touches retry.go; no public API changes. Adds metric payments.retry.backoff_ms.
#### Citations
- ADR-1234 — /docs/payments/adr-1234.md#decision
- Code — /services/payments/retry.go#L120-L168
- Runbook — /ops/runbooks/payments-retries.md#rollback
- 基于 ADR 和所有权的重构顾问
目标:通过自动呈现设计意图和所有者,使大型重构更安全。
核心步骤:
- 给定一个提议的重构计划,检索被取代的 ADR 和受影响的模块所有者。
- 生成清单:“通知 @payments-core”,“更新合约测试”,“根据 ADR‑0899 确认弃用窗口”。
- 输出每个来源的引用,以便审查者快速验证。
衡量开发者速度和检索质量
将 RAG 视为具有可审计结果的工程系统。
跟踪指标:
- 速度:中位合并时间 (TTM)、合并率(已合并/已开启)、每个 PR 的审查迭代次数。
- 质量:回滚率、CI 失败率、重构后的合并后缺陷。
- 检索:precision@k、引用准确率(引用的来源是否支持该主张?)、幻觉率。
A/B 计划(8–12 周):
- 对照组:标准工作流。
- 实验组:启用带有引用的 PR 描述助手 + 重构顾问(只读建议)。
- 在 检索 → 建议 → 审查者接受/覆盖 → 合并 环节记录事件。
有关衡量和提高 RAG 忠实度和引用行为的更广泛行业背景,请参阅最近的调查和评估工作,这些工作将相关性/忠实度指标和 LLM‑as‑judge 审计正式化 (arXiv — Evaluation of Retrieval‑Augmented Generation: A Survey;arXiv — Comprehensive and Practical Evaluation of RAG)。
从演示到生产
你不需要一个单体应用;你需要一个可靠的循环。
- 摄取:针对代码(函数/类)和文档(标题/语义)的语言感知分块。附加元数据(repo_path, module, owner, version)。代码目标为 500–1500 token;文档为 400–1000 token。
- 索引节奏:变更时重新嵌入;热门仓库每日批处理;冷门仓库每周处理。为你的索引建立版本以备回滚。
- 治理:优先选择私有/本地部署;将检索 ACL 与仓库权限对齐;在嵌入前对密钥进行脱敏。
- 服务:限制 k 值以控制 token;缓存频繁查询;对于棘手的命名空间考虑使用交叉编码器重排序。
- 监控:跟踪 precision@k、引用准确率、延迟和单次查询成本。对漂移(精确度/引用准确率下降)进行告警。
现实世界的信号显示了为什么这值得去做。亚马逊报告称,Amazon Q Developer 将数万个应用程序的大规模 Java 升级从几天缩短到几分钟,估计节省了 4,500 个开发者年,并贡献了 2.6 亿美元的年度影响 (AWS DevOps & Developer Productivity Blog, 2024) —— 这证明了当嵌入式开发者助手集成到 SDLC 中时,可以实现吞吐量的阶跃式变化 (AWS DevOps Blog — Amazon Q Developer milestone)。GitHub 关于 Mercado Libre 的客户案例指出,全组织范围的采用使编写代码的时间减少了约 50%,并实现了非凡的 PR 吞吐量,这表明当助手处于关键路径上时,天花板是很高的 (GitHub Customer Stories — Mercado Libre)。
工具说明——协作良好的技术栈
- 向量 + 稀疏:Qdrant, Pinecone, Weaviate 都支持混合模式;根据对评分融合的控制、运维成熟度和成本进行选择。
- 编排:LangChain/LlamaIndex 用于快速组合;Dagster/Airflow 用于摄取运维。
- 嵌入:为代码库选择经过代码微调的模型;监控漂移并选择性地重新嵌入。
- 图谱/结构:Neo4j/TigerGraph 用于显式 Know‑How 图谱,或为较小团队使用轻量级 JSON/kv。
- 智能体 CI:根据 GitHub 的智能体 CI 指南,在 PR 钩子和 CI 评论中集成助手。
实践示例:使用 puppyone 的结构化 Know‑How 和混合索引
只有当你的知识为机器建模时,混合索引才会大放异彩。一种中立的实现方式是将企业知识存储为结构化 Know‑How(JSON/图谱),并在单个检索器中融合词法、向量和结构化查找。
示例工作流(说明性,中立):
- 将 ADR、所有权和 API 合约建模为一等 Know‑How 节点(例如 adr_id, status, decision, owners, repo_paths, version)。
- 摄取带有元数据(repo_path, symbols, owners)的代码/文档块。构建一个混合索引,结合词法过滤(如仓库路径)、向量(语义相似性)和结构化连接(adr_id → 相关文件/所有者)。
- 在 PR 助手中,要求提供一个包含 ADR 永久链接和文件行范围的“引用”区块,以便审查者快速验证。
这种模式得到了 puppyone 公开概念材料的支持,该产品围绕结构化 Know‑How 和混合索引进行定位,以实现确定性检索和精确引用。有关此方法的概述,请参阅该公司关于混合索引的文章,该文章总结了如何结合文本和结构以在智能体工作流中实现可靠的落地(参见“Ultimate Guide to Agent Context Base: Hybrid Indexing”中的概述)(puppyone’s hybrid indexing guide)。在设计你自己的模式和检索器时,请将其作为概念参考;并根据你的技术栈和治理约束进行调整。
结论与后续步骤
如果你的目标是更快、更安全的 PR,请首先投资于结构化 Know‑How 和一个能够通过引用证明每一项主张的混合检索器。试点 PR 描述助手和重构顾问,衡量 TTM 和引用准确率,然后推广有效的方案。如果你正在探索结构化 Know‑How 和混合索引,可以在小规模、私有的试点中评估 puppyone,并将其与你现有的技术栈进行比较。