上下文学习混合索引终极指南
2026年2月7日Ollie @puppyone
核心要点
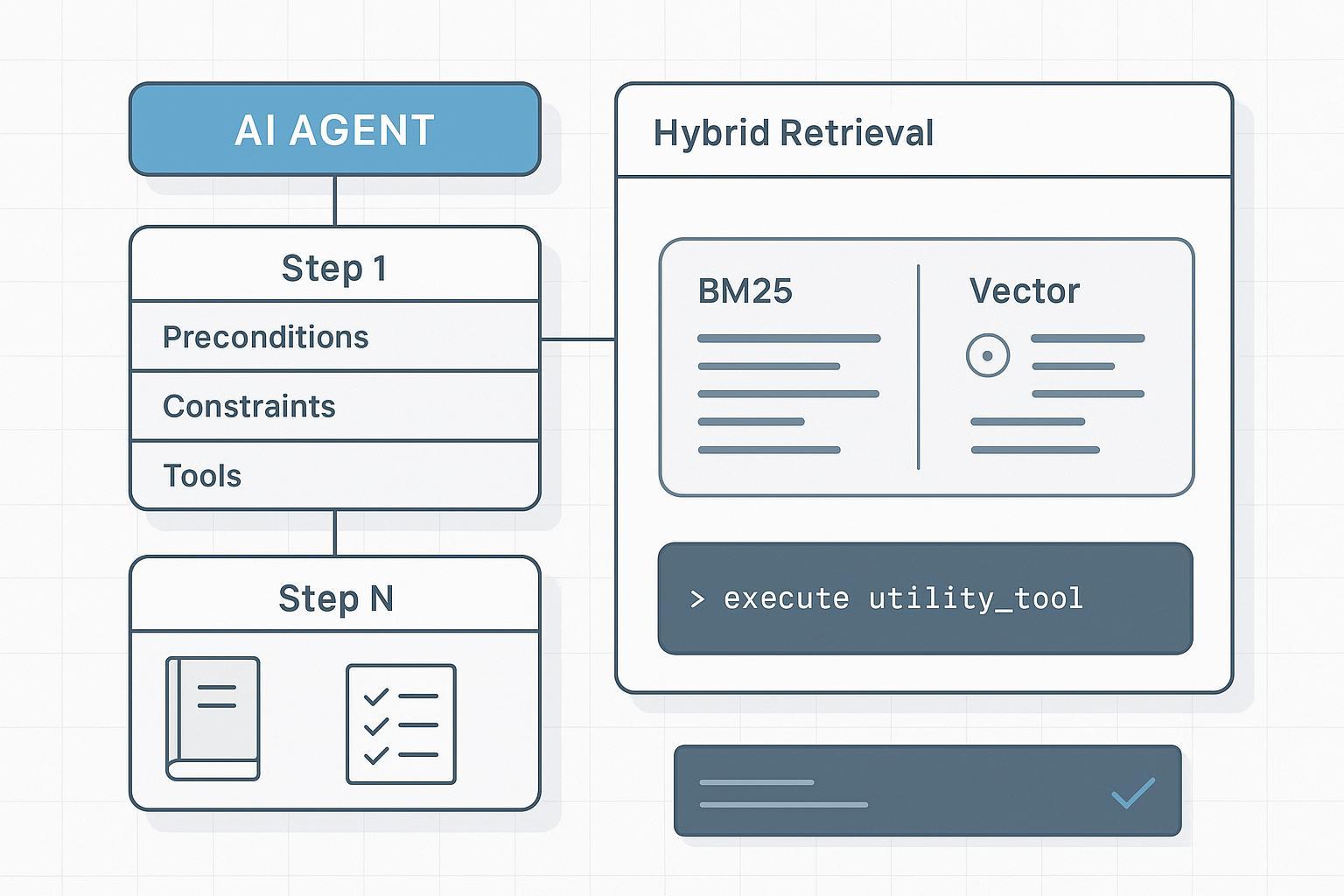
- 混合、字段感知的检索优于「单纯把上下文拉长」。需要的是每一步的确定性切片,而不是一堵长文本墙。
- 模型限制真实存在:基准显示高比例的忽略/误用上下文;要把系统设计成能预防、发现并纠正这类错误。
- 在运营/支持场景中,将 Know-How JSON/图与混合索引、以及「规划→执行→验证」的智能体闭环结合,才能实现步骤遵从与可审计性。
为何模型在 SOP 上会忽略和误用上下文
专门测试上下文学习的新基准(CL-bench:500 个上下文、1,899 个任务、31,607 条验证规则)表明,当前模型从给定上下文中学习时非常脆弱:十个前沿模型平均只完成约 17.2% 的任务;最佳模型在推理模式下也仅约 23.7%。主要错误是未正确使用给定上下文—遗漏关键细节或套用错误规则。参见 CL-bench 论文 (arXiv)、腾讯混元研究博客。仅靠长上下文能力无法解决;LongBench v2 等研究表明,更好的窗口处理仍会在多文档推理与聚合上留下缺口(LongBench v2 ACL)。在多步 SOP 中,这表现为跳步、指令漂移或不安全操作。
朴素 RAG 执行 SOP 的常见失败模式
即使不错的 RAG 栈在运营工作流上也会失效,因为检索单元与动作单元错位:过宽的块导致检索漂移;未加权的字段把关键 token(步骤 ID、前置条件、警告)埋在长文中。单一大 prompt 进一步鼓励模型即兴发挥、跳过验证或编造步骤与工具。解决办法是面向确定性检索与可验证执行做设计。
基础:将 SOP 建模为 Know-How JSON/图
文本手册是为人写的;智能体需要与生产动作方式一致的结构化、字段化知识。实用 schema 应编码步骤、依赖、约束与验证方法,以便检索能精确命中执行器所需内容。文中 JSON 示例(sop.router.reset.v3,含 step_number、preconditions、constraints、tools_allowed、checkpoints、verification_method、dependencies)保持不变。这样检索可以更侧重 title、step_number、preconditions、constraints 而非叙述。Context Base 概念:puppyone 关于我们。
长而密集手册中的上下文学习混合索引
核心不是「更长上下文」,而是「更好的检索单元与排序信号」。实践中即:带字段感知的混合索引 + 轻量级重排。
- 将稀疏词法信号(BM25/BM25F)与稠密向量结合:词法命中精确 ID、警告、约束;稠密向量提升语义表述步骤的召回。可参考 Elastic 什么是混合搜索、Elastic retrievers and RRF、Weaviate 混合搜索说明。
- 字段感知加权:优先 title、step_number、preconditions、constraints、tools_allowed。
- 每步只取最小、确定的切片;不要每次都喂入整份 SOP。
- 可选:用 cross-encoder 或结构感知 reranker 对 top-k 重排,突出约束与检查点。
SOP 的智能体 RAG:规划→检索→执行→验证
规划器将任务分解为步骤级意图,用 step_number、所需工具等字段构造针对性检索查询。检索器返回带 ID 的最小字段切片(前置条件、约束、参数、检查点)。执行器仅调用枚举工具并传入符合 schema 的参数,必须引用所用切片 ID 并将工具反馈写入状态。验证器在推进前按检查点与约束核对完成情况;偏差时可触发重规划或人工复核。参见 Anthropic 多智能体研究系统。
动手示例:单步端到端(中性、可复现)
说明:Puppyone 为我们产品;此处中性提及,可作为一种 Context Base,也可用您偏好的任意栈替代。更多见 puppyone。目标:用混合检索与智能体闭环执行「Router Safe Reset」第 7 步。查询计划:intent apply staged configuration;constraints_required;fields 含 step_number=7、preconditions、constraints、tools_allowed、checkpoints、verification_method。伪代码(Python 风格)与英文版一致:hybrid_search(BM25F+vector+RRF)、field_boosts、rerank_and_select_minimal;执行前 assert 充分性;schema 校验的 tool_call;验证器检查 ACL delta 与 outage;通过则 mark_step_complete,否则 escalate_or_replan。状态日志示例:used_slice、preconditions_ok、constraints_ok、executor、verifier。同一闭环可用 Elastic/OpenSearch/Vespa/Weaviate 或 RDBMS+pgvector+BM25 实现。
评估手册:先证明可靠性,再扩展
检索质量:Recall@k、每步 MRR/nDCG、Context Precision、Context Sufficiency。执行:Step Adherence %、Action Success Rate、Instruction Drift Rate、每 1,000 次执行的事故数、Time-to-Resolution。对每个 SOP 步骤保存 ground-truth 切片 ID 与期望工具/结果模式;断言执行器引用所用切片且检查点通过后再推进。综述:RAG 评估综述 (2024)。
替代方案与对等选择
| 技术栈 | 混合融合 | 字段感知加权 | 本地/VPC | 备注 |
|---|---|---|---|---|
| Elasticsearch | RRF、加权混合 | BM25F、多字段加权 | 成熟自托管 | 丰富 Retriever API、cross-encoder reranker |
| OpenSearch | 加权 + rerank 模式 | 通过分析器做字段加权 | 原生自托管 | 向量性能持续优化 |
| Vespa | 词法 + ANN + rerank | 每字段特征 | 自托管、可扩展 | 强排序/ML 管线 |
| Weaviate | RRF/加权混合 | 属性权重/过滤 | 托管+自托管 | 文档清晰 |
若采用「Agent Context Base」思路(将规程存为结构化、版本化 Know-How 并供给确定性切片),可选产品之一为 puppyone。评估时看:字段感知打分、确定性切片保证、审计日志与评估 harness 支持。
实践中「好」长什么样
试点中,从整文档 prompt 转为按步、字段化切片后,指令漂移明显下降、步骤遵从度上升,与基准结论一致:模型不会自动从长文中提炼并遵守每条约束。混合索引用于上下文学习的要义,是把精确的约束表面交到智能体手中,并要求其验证后再继续。坚持这样做,事故复盘就会越来越像无聊的检查清单—正是运维想要的结果。
下一步
若您正在评估面向 SOP 自动化的生产级方案—结构化 Know-How、混合索引与规划→执行→验证闭环—我们可以一起看您的语料与约束。预约一场针对您环境的「混合索引 + 智能体 RAG」技术演示。