Ultimativer Leitfaden zum Model Context Protocol (MCP)
3. April 2026Ollie @puppyone
Key takeaways
- MCP ersetzt weder Ihr Datenmodell noch Ihre Governance-Schicht. Es standardisiert, wie Agent-Hosts Tools, Ressourcen und Prompts entdecken und aufrufen.
- Die eigentliche Produktionsfrage lautet selten „MCP oder API“, sondern welche Oberfläche für Discovery, Determinismus, Richtlinienkontrolle und Auditierbarkeit zuständig sein soll.
- Ein gutes MCP-Setup hält Tools eng, Rückgabeobjekte stabil und trennt Lese- von Schreibpfaden.
- Docker-Hardening, Request-Tracing und strukturierte Logs sind genauso wichtig wie gute Prompts, weil sie über Eindämmung und Nachvollziehbarkeit entscheiden.
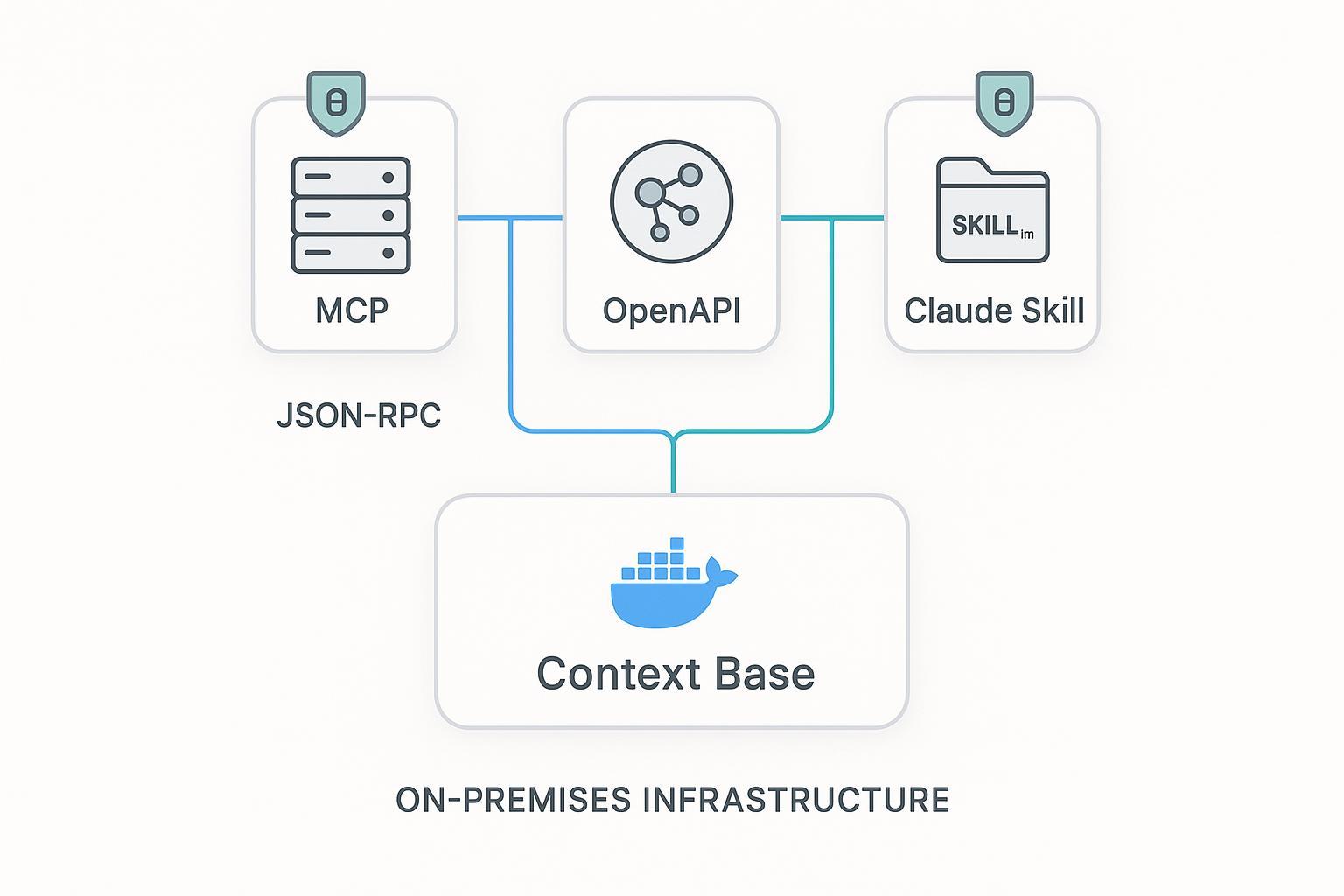
- puppyone ist besonders dann hilfreich, wenn nicht die Tool-Anbindung schwierig ist, sondern die Verteilung einer einzigen, sauber regierten Kontextbasis über MCP, API und Skills.
Was MCP wirklich leistet
Viele Teams beschreiben Model Context Protocol zunächst als „den Standard, um Tools mit KI-Agenten zu verbinden“. Das stimmt, ist aber für Architekturentscheidungen zu grob.
Praktischer ist diese Sicht:
- MCP standardisiert Capability Discovery
- MCP standardisiert Capability Invocation
- MCP löst nicht automatisch Knowledge Modeling, Policy Design oder stabile Outputs
Die offizielle Spezifikation beschreibt MCP als JSON-RPC-basiertes Protokoll für Tools, Ressourcen und Prompts in Agent-Runtimes. Relevant sind vor allem die Spezifikation, der Lifecycle-Teil und die ursprüngliche Ankündigung von Anthropic.
Nicht gelöst werden damit:
- veraltete oder widersprüchliche Daten
- zu breite Tool-Grenzen
- schwache Autorisierung
- fehlende Audit-Trails
- instabile Payloads, die das Modell zum Raten zwingen
Darum behandeln reife Teams MCP als Delivery-Protokoll und nicht als vollständige Agent-Architektur.
Wann MCP passt und wann nicht
Ein häufiger Fehler ist, jede Fähigkeit hinter MCP zu verstecken, nur weil es modern wirkt. Besser ist es, je nach Aufgabe die passende Oberfläche zu wählen.
| Oberfläche | Stärken | Schwäche | Verwenden Sie sie, wenn |
|---|---|---|---|
| MCP-Server | Discovery, agent-native Ausführung, Host-Interop | Stabile Payloads und Policies müssen Sie selbst entwerfen | Der Aufrufer ein Agent-Host ist und Tool-/Resource-Semantik wichtig ist |
| REST API | Deterministische Verträge, ausgereifte Auth/Gateways/Caches | Der Agent muss die Endpoint-Semantik kennen | Sie langfristige, host-unabhängige Verträge für mehrere Konsumenten brauchen |
| Skills | Workflow-Anweisungen und Guardrails verteilen | Schwach als Live-Datenebene | Sie Verfahrenswissen verpacken und Laufzeitdaten via MCP/API beziehen wollen |
Die einfache Regel:
- discovery-lastige Fähigkeiten über MCP
- contract-lastige Fähigkeiten über REST
- workflow-lastige Anleitungen über Skills
Genau diese Kombination ist in der Praxis oft am stabilsten.
Governed MCP mit puppyone sehenGet startedEin minimales MCP-Design, das Produktion überlebt
Ein schwaches MCP-Tool ist meist ein „kann alles“-Wrapper. Ein starkes MCP-Tool ist schmal, typisiert und gut begrenzt.
Die Grundregeln:
- Ein Tool, ein Job
- Strenges Input-Schema
- Stabiles Output-Envelope
- Policy-Checks vor der Datenausgabe
- Rückgaben mit nachvollziehbaren IDs
import { McpServer } from "@modelcontextprotocol/sdk/server";
const server = new McpServer({ name: "org-context" });
server.tool(
"get_knowhow_item",
{
description: "Read one governed Know-How item by id",
inputSchema: {
type: "object",
properties: { id: { type: "string" } },
required: ["id"],
additionalProperties: false
}
},
async ({ id }, ctx) => {
const item = await ctx.store.read(id);
if (!ctx.policy.canRead(ctx.user, item.policyTag)) {
return {
ok: false,
error: { code: "forbidden", message: "Access not permitted" }
};
}
return {
ok: true,
data: {
id: item.id,
title: item.title,
version: item.version,
summary: ctx.redactor(item.summary)
},
trace: {
requestId: ctx.requestId,
policyTag: item.policyTag
}
};
}
);
Die Stärke liegt nicht in Raffinesse, sondern darin, dass das Tool nicht zur unkontrollierten Durchreiche des Gesamtsystems wird.
Docker-Hardening gehört zum MCP-Design
Viele Tutorials hören bei „der Server läuft“ auf. Das reicht nicht, wenn der Server sensible Kontexte lesen oder Aktionen auslösen kann.
Ein sinnvolles Mindestmaß:
- als Non-Root ausführen
- nach Möglichkeit Read-Only-Filesystems
- Secrets als Dateien mounten statt ins Image backen
- Healthchecks definieren
- Network Egress begrenzen
- Correlation IDs an jede Ausführung hängen
Nützlich sind hier Docks Dokumentationen zu HEALTHCHECK, Compose Healthchecks, rootless/non-root Betrieb und Read-Only Mounts.
FROM node:22-slim AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci --ignore-scripts
COPY . .
RUN npm run build && npm prune --omit=dev
FROM gcr.io/distroless/nodejs22-debian12:nonroot
WORKDIR /app
COPY --from=build /app/dist ./dist
USER 65532:65532
ENV NODE_ENV=production
CMD ["/nodejs/bin/node", "dist/server.js"]
Ob lokal oder on-prem: ohne klare Runtime-Grenzen bleibt „local-first“ nur ein Versprechen.
Warum eine versionierte REST API weiter wichtig ist
MCP ist stark für agent-native Ausführung, aber REST bleibt sinnvoll wegen:
- expliziter Versionierung
- stabiler Pagination und Filtersemantik
- Gateway-nativer Authentifizierung, Limits und Caches
- Wiederverwendung durch Agenten, Apps und interne Services
Deshalb veröffentlichen viele Teams denselben regierten Kontext sowohl via MCP als auch via REST. Weiterhin hilfreich sind Microsofts API-Design-Guidelines sowie RFC 6585 und RFC 9110 für Rate Limits und Retry-After.
Entscheidend ist nicht Redundanz, sondern Spezialisierung:
- MCP für Discovery und Tool-Semantik
- REST für deterministische Verträge
Wenn Sie beides brauchen, ist das normal.
Skills sind Verpackung, nicht Datenebene
Skills eignen sich hervorragend, um Arbeitsweisen, Guardrails und wiederholbare Abläufe zu verteilen.
Typische Anwendungsfälle:
- Workflow-Anweisungen
- Troubleshooting-Abläufe
- gemeinsame Review-Gewohnheiten
- rollenspezifische Leitfäden
Als alleinige Datenebene taugen sie jedoch wenig. Für Frische, Autorisierung und strukturierte Retrieval-Pfade brauchen Sie weiterhin MCP oder APIs. Die Anthropic-Dokumentation zu Skills und das öffentliche Skills-Repository zeigen das Format gut.
Die praktikable Aufteilung:
- Skill definiert Ablauf und Grenzen
- Skill ruft MCP-Tool oder REST-Endpoint auf
- Die Laufzeit protokolliert Request, Ergebnis und Policy-Entscheidung
Observability macht MCP auditierbar
Wenn ein Agent ein Tool falsch verwendet, sollten Sie beantworten können:
- wer den Aufruf ausgelöst hat
- welches Tool oder welche Ressource betroffen war
- welche Eingaben übergeben wurden
- welche Policy-Entscheidung gegriffen hat
- welcher Result-Hash oder Datensatz zurückkam
- wie lange der Vorgang dauerte
Genau deshalb sind OpenTelemetry und strukturierte Logs keine Kür. Gute Startpunkte sind Context Propagation und Traces. Für Retention und Audit helfen NIST SP 800-92 und SP 800-53 Rev.5.
{
"ts": "2026-04-03T09:15:00Z",
"event": "tool.execute",
"requestId": "req_7ad2",
"tool": "get_knowhow_item",
"actor": "agent_ops_reader",
"decision": "allow",
"resultHash": "sha256:ab12...",
"latencyMs": 42
}
Wenn Ihr Stack so etwas nicht liefern kann, ist das eigentliche Problem noch nicht die Protokollwahl.
Wo puppyone in diese Architektur passt
Die meisten MCP-Projekte scheitern nicht am Protokoll, sondern am Kontext dahinter:
- Wissen liegt verstreut in mehreren Systemen
- unterschiedliche Tools sehen unterschiedliche Wahrheiten
- Berechtigungen lassen sich nicht fein genug schneiden
- Versionierung und Audit-Linien sind instabil
Hier kommt eine regierte Kontextbasis ins Spiel. Teams evaluieren puppyone genau für diesen Zweck: Enterprise-Know-How strukturieren, hybrid indexieren und dieselbe kontrollierte Wissensbasis via MCP, API oder Workflow-Packaging ausliefern. Dadurch muss der MCP-Server Kontext nicht bei jedem Call neu zusammensuchen.
Besonders relevant ist das, wenn:
- mehrere Agenten dieselbe Source of Truth brauchen
- dieselben Inhalte über MCP und API bereitgestellt werden
- Freigaben stabile IDs und Provenance benötigen
- local-first oder self-hosted Kontrolle wichtig ist
Weiterführend:
- Context Engineering: When RAG Isn't Enough
- Vector Database vs. Context Base: What AI Agents Actually Need in Production
- Puppyone + OpenClaw Integration Playbook for Engineers
Nächste Schritte
Starten Sie nicht mit einer großen Protokollmigration. Wählen Sie lieber einen read-heavy Workflow und machen Sie ihn langweilig stabil:
- ein schmales MCP-Tool definieren
- ein stabiles Response-Envelope liefern
- Policies außerhalb des Modells durchsetzen
- Trace IDs und strukturierte Logs ergänzen
- nur bei echtem Bedarf einen REST-Endpoint danebenstellen
Danach können Sie Tools, Skills und Orchestrierung sicher ausbauen.
Governed MCP mit puppyone planenGet startedFAQs
Q1. Ersetzt MCP REST APIs?
Nein. MCP ist stark für agentenseitige Ausführung, REST für host-unabhängige Verträge, Gateway-Kontrollen und breitere Wiederverwendung.
Q2. Sollte jede interne Fähigkeit zu einem MCP-Tool werden?
Nein. Zu breite Tools sind schwer zu kontrollieren und zu debuggen. Beginnen Sie mit schmalen, typisierten, vorhersagbaren Fähigkeiten.
Q3. Reichen Skills allein aus?
Meistens nicht. Skills verpacken Workflow-Intention gut, aber für Frische, Autorisierung und Auditierbarkeit brauchen Sie MCP-Tools oder APIs.