Ultimate Guide to Model Context Protocol (MCP)
April 3, 2026Ollie @puppyone
Key takeaways
- MCP is not a replacement for your data model or your governance layer. It standardizes how agent hosts discover and call tools, resources, and prompts.
- The production decision is usually not "MCP or API." It is which interface should own discovery, determinism, policy enforcement, and auditability for each workflow.
- A strong MCP rollout keeps tools narrow, returns stable envelopes, and separates read paths from write paths so agents do not improvise their way into risky actions.
- Docker hardening, request tracing, and structured logs matter as much as prompt quality because they decide whether an incident is containable.
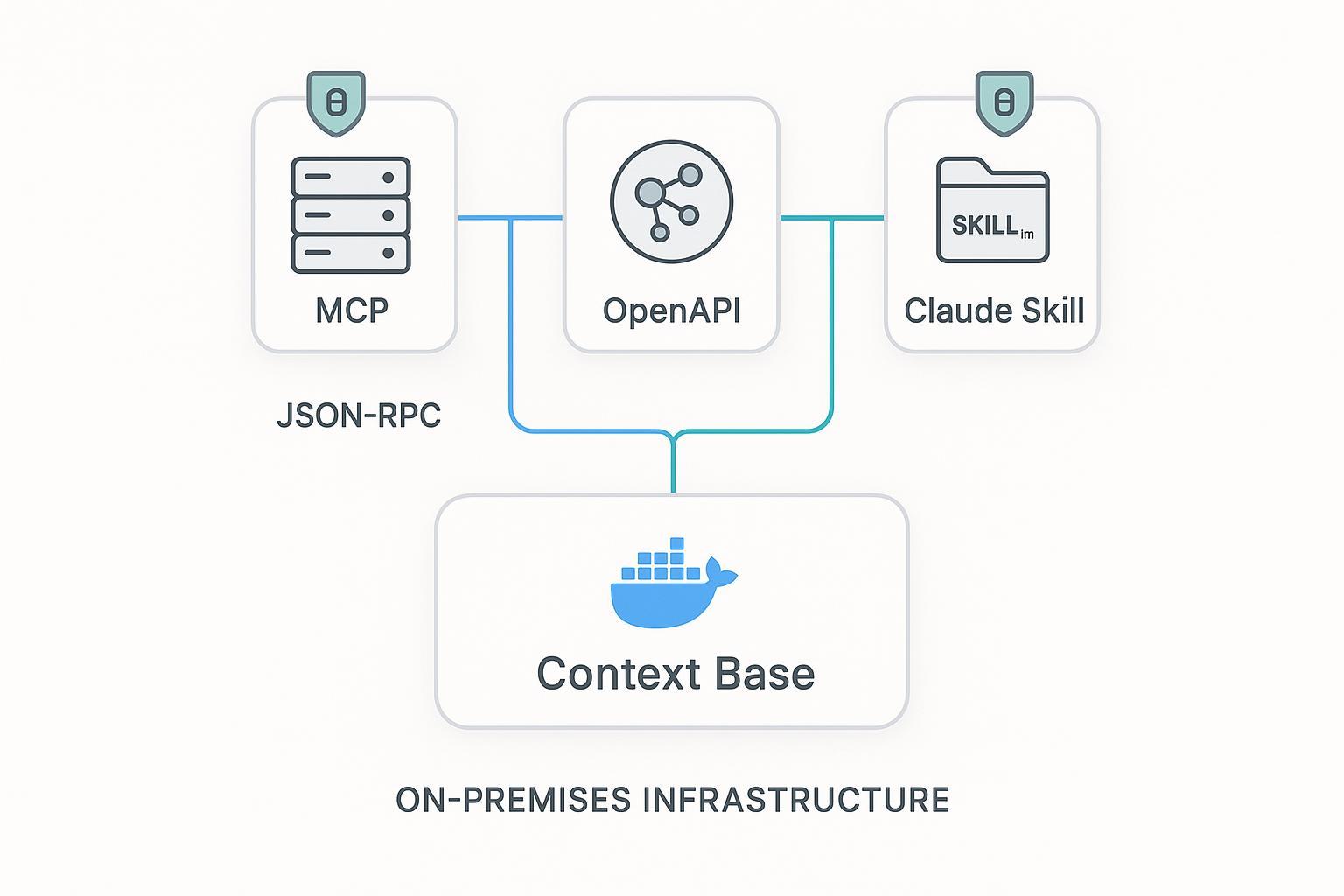
- puppyone is useful when the hard part is not tool wiring but distributing one governed context base through MCP, API, and Skills without duplicating knowledge.
The real job of MCP
Most teams first hear about Model Context Protocol as "the standard way to connect tools to AI agents." That is directionally right, but too vague to help with architecture.
The useful framing is simpler:
- MCP standardizes how a host discovers capabilities.
- MCP standardizes how an agent calls those capabilities.
- MCP does not decide how your knowledge is modeled, how your policies work, or whether your outputs are deterministic enough for production.
The official specification describes MCP as a JSON-RPC-based protocol for exposing tools, resources, and prompts across agent runtimes. That matters because it reduces custom adapter work and gives you one lifecycle for initialization, capability negotiation, and execution. See the Model Context Protocol specification, the lifecycle section, and Anthropic's original Model Context Protocol announcement.
What MCP does not solve for you:
- stale or contradictory source data
- vague tool boundaries
- weak authorization checks
- missing audit trails
- unstable payload shapes that force the model to guess
That is why mature teams treat MCP as a delivery protocol, not as a complete agent architecture.
When MCP is the right interface, and when it is not
The easiest way to overcomplicate a rollout is to force every capability behind MCP because it feels modern. A better pattern is to choose the surface that best matches the job.
| Surface | Best at | Weak spot | Use it when |
|---|---|---|---|
| MCP server | Tool discovery, agent-native execution, host interoperability | You still need to design stable payloads and policy enforcement | The caller is an agent host that benefits from standardized tool and resource semantics |
| REST API | Deterministic contracts, gateway policy, mature auth and caching | The agent must already know endpoint semantics | You need long-lived contracts across agents, apps, and human-operated systems |
| Skills | Packaging workflow instructions and guardrails | Weak for live data by themselves | You want to distribute repeatable procedures, then pair them with MCP or API for runtime data |
One practical rule:
- expose discovery-heavy capabilities through MCP
- expose contract-heavy capabilities through REST
- expose workflow-heavy guidance through Skills
That is often the real production stack: MCP for discovery, REST for deterministic service contracts, and Skills for operator-friendly workflow packaging.
See governed MCP delivery with puppyoneGet startedMinimal MCP design that survives production pressure
The weak version of an MCP tool is "here is a broad function, good luck." The stronger version is a narrow, typed capability with obvious boundaries.
That usually means:
- one tool does one job
- the input schema is strict
- the output envelope is stable
- policy checks happen before data leaves the server
- the response includes identifiers you can trace later
Illustrative example:
import { McpServer } from "@modelcontextprotocol/sdk/server";
const server = new McpServer({ name: "org-context" });
server.tool(
"get_knowhow_item",
{
description: "Read one governed Know-How item by id",
inputSchema: {
type: "object",
properties: { id: { type: "string" } },
required: ["id"],
additionalProperties: false
}
},
async ({ id }, ctx) => {
const item = await ctx.store.read(id);
if (!ctx.policy.canRead(ctx.user, item.policyTag)) {
return {
ok: false,
error: { code: "forbidden", message: "Access not permitted" }
};
}
return {
ok: true,
data: {
id: item.id,
title: item.title,
version: item.version,
summary: ctx.redactor(item.summary)
},
trace: {
requestId: ctx.requestId,
policyTag: item.policyTag
}
};
}
);
Nothing here is fancy. That is the point.
The production advantage comes from refusing to let the tool become a loose wrapper around an entire internal system.
Docker hardening is part of the MCP design
Many MCP tutorials stop at "the server runs." That is not enough if the server can read sensitive knowledge, call internal tools, or trigger actions.
If you ship MCP in containers, the hardening baseline should be boring and explicit:
- run as a non-root user
- prefer read-only filesystems where possible
- mount secrets as files instead of baking them into images
- add health checks so orchestration layers can fail fast
- restrict network egress so the server cannot call arbitrary destinations
- emit correlation IDs so tool executions can be reconstructed later
Docker's documentation covers the mechanics for HEALTHCHECK, Compose healthchecks, rootless and non-root operation, and read-only bind mounts. Those are not box-checking details. They are what keep a context-serving process from turning into an unbounded sidecar with too much reach.
Illustrative container pattern:
FROM node:22-slim AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci --ignore-scripts
COPY . .
RUN npm run build && npm prune --omit=dev
FROM gcr.io/distroless/nodejs22-debian12:nonroot
WORKDIR /app
COPY --from=build /app/dist ./dist
USER 65532:65532
ENV NODE_ENV=production
CMD ["/nodejs/bin/node", "dist/server.js"]
The same logic applies even if your runtime is not Docker. Local-first deployments are only trustworthy when the runtime boundary is clear.
Why a versioned REST API still belongs in the stack
MCP is great for agent-native execution, but deterministic APIs still matter because they give you:
- explicit versioning
- stable pagination and filter semantics
- gateway-native auth, throttling, and caching
- cleaner reuse across agents, web apps, and internal services
That is why many teams expose the same governed context through both MCP and REST. Microsoft's web API design guidance is still useful for pagination, versioning, and envelope discipline, while RFC 6585 and RFC 9110 cover throttling and Retry-After.
The key production pattern is not duplication for its own sake. It is surface specialization:
- MCP gives hosts discovery and tool semantics.
- REST gives operators and services deterministic contracts.
If your agent stack needs both, that is normal.
Skills are the packaging layer, not the data plane
Skills are useful because they let teams distribute reusable operator intent: what to do, what to avoid, what sequence to follow, and what evidence to cite.
That makes them excellent for:
- guarded workflow instructions
- reusable troubleshooting steps
- shared review patterns
- role-specific guidance
They are weak as a standalone data plane because instructions alone do not solve freshness, authorization, or structured retrieval. Anthropic's docs on extending Claude with skills and the public anthropics/skills repository are helpful examples of the format.
A pragmatic pattern looks like this:
- the Skill defines the workflow and constraints
- the Skill calls an MCP tool or REST endpoint for live context
- the runtime logs the request, result, and policy outcome
That division keeps instructions readable and data delivery governed.
Observability is what turns MCP into an auditable system
If an agent used a tool incorrectly, you need to know:
- which user or agent identity made the call
- which tool or resource was exposed
- what input was supplied
- what policy decision was applied
- what output hash or record identifier came back
- how long it took
This is where OpenTelemetry and structured logs stop being "platform team nice-to-haves." They become the only way to replay an incident without guessing. The OpenTelemetry docs on context propagation and traces are a practical starting point. For retention and audit planning, NIST's SP 800-92 draft revision and SP 800-53 Rev.5 remain useful references.
Minimal log shape:
{
"ts": "2026-04-03T09:15:00Z",
"event": "tool.execute",
"requestId": "req_7ad2",
"tool": "get_knowhow_item",
"actor": "agent_ops_reader",
"decision": "allow",
"resultHash": "sha256:ab12...",
"latencyMs": 42
}
If your tooling cannot produce something this reconstructable, the protocol choice is not your main problem yet.
Where puppyone fits in an MCP rollout
Most MCP projects do not fail because the protocol is unclear. They fail because the context behind the protocol is messy:
- duplicated across systems
- inconsistent across tools
- hard to permission correctly
- difficult to version and audit
That is the gap a governed context base is supposed to close.
In practice, teams evaluating puppyone use it as the system that structures enterprise Know-How, applies hybrid indexing, and distributes the same governed knowledge through MCP, API, or workflow packaging. That means the MCP server is no longer assembling context ad hoc on every call. It is serving a curated, permission-aware artifact.
This matters most when:
- multiple agents need the same source of truth
- the same knowledge must be exposed through MCP and API
- reviewers need stable identifiers and provenance during approvals
- local-first or self-hosted operation matters for control
Related reads if you want the adjacent architecture patterns:
- Context Engineering: When RAG Isn't Enough
- Vector Database vs. Context Base: What AI Agents Actually Need in Production
- Puppyone + OpenClaw Integration Playbook for Engineers
What to do next
If you are early, do not start with a giant protocol migration. Pick one read-heavy workflow and make it boring:
- define one narrow MCP tool
- return one stable response envelope
- put policy enforcement outside the model
- emit trace IDs and structured logs
- add a matching REST endpoint only if another consumer genuinely needs it
Once that works, you can add more tools, more Skills, and richer orchestration without losing control of the foundation.
Plan a governed MCP rollout with puppyoneGet startedFAQs
Q1. Is MCP a replacement for REST APIs?
No. MCP is a strong agent-facing protocol, but REST still wins when you need stable, host-agnostic contracts, gateway controls, and service reuse beyond agent runtimes.
Q2. Should every internal capability become an MCP tool?
No. Broad tools are hard to govern and harder to debug. Start with narrow, typed capabilities that have obvious boundaries and predictable outputs.
Q3. Are Skills enough without MCP or APIs?
Usually not. Skills package workflow intent well, but they still need governed runtime data from MCP tools or APIs if freshness, authorization, and auditability matter.