Guía definitiva del Model Context Protocol (MCP)
3 de abril de 2026Ollie @puppyone
Key takeaways
- MCP no sustituye ni a tu modelo de datos ni a tu capa de gobernanza. Estandariza cómo los hosts de agentes descubren y llaman herramientas, recursos y prompts.
- La decisión de producción rara vez es “MCP o API”; lo importante es qué superficie debe encargarse de discovery, determinismo, enforcement y auditoría.
- Un buen despliegue de MCP mantiene herramientas estrechas, respuestas estables y separa rutas de lectura y escritura.
- El hardening de Docker, el tracing de requests y los logs estructurados importan tanto como los prompts porque determinan si un incidente se puede contener y reconstruir.
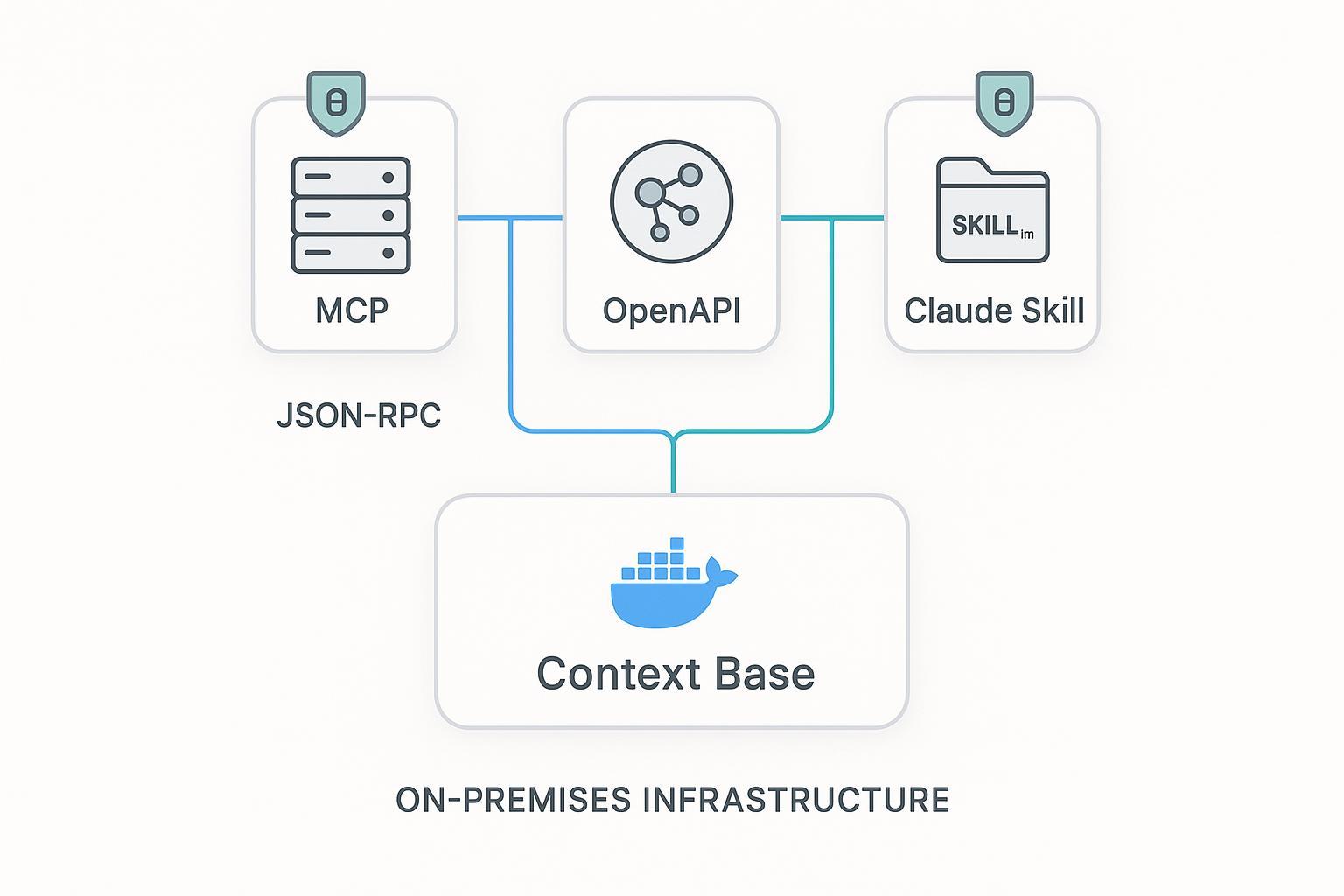
- puppyone cobra sentido cuando el problema real ya no es “conectar herramientas”, sino distribuir una misma base de contexto gobernada por MCP, API y Skills sin duplicar conocimiento.
Qué hace MCP de verdad
Muchos equipos describen Model Context Protocol como “el estándar para conectar herramientas con agentes de IA”. Es correcto, pero demasiado amplio para tomar buenas decisiones de arquitectura.
Una forma más útil de pensarlo:
- MCP estandariza el descubrimiento de capacidades
- MCP estandariza la invocación de capacidades
- MCP no resuelve por sí solo modelado de conocimiento, diseño de políticas ni estabilidad de salida
La especificación oficial define MCP como un protocolo basado en JSON-RPC para exponer tools, resources y prompts a runtimes de agentes. Merece la pena revisar la especificación, la sección de lifecycle y el anuncio original de Anthropic sobre Model Context Protocol.
Lo que MCP no soluciona:
- datos obsoletos o contradictorios
- límites de herramienta demasiado amplios
- autorizaciones débiles
- falta de auditoría
- payloads inestables que obligan al modelo a adivinar
Por eso los equipos maduros tratan MCP como un protocolo de entrega, no como una arquitectura completa.
Cuándo usar MCP y cuándo no
Un error común es meter toda capacidad detrás de MCP solo porque parece moderno. En realidad, conviene elegir la superficie según el trabajo que debe hacer.
| Superficie | Fortalezas | Debilidad | Úsala cuando |
|---|---|---|---|
| Servidor MCP | Discovery, ejecución nativa para agentes, interoperabilidad | Hay que diseñar bien payloads y políticas | El consumidor es un host de agentes y aprovecha la semántica de tools/resources |
| REST API | Contratos deterministas, auth y gateways maduros | El agente debe conocer la semántica del endpoint | Necesitas contratos duraderos para agentes, apps y servicios |
| Skills | Empaquetar workflows y guardrails | Débil como plano de datos en tiempo real | Quieres distribuir instrucciones reutilizables y obtener datos vivos vía MCP/API |
La regla práctica:
- capacidades centradas en discovery: MCP
- capacidades centradas en contrato: REST
- conocimiento centrado en workflow: Skills
Esa combinación suele ser la más estable en producción.
Ver MCP gobernado con puppyoneGet startedUn diseño mínimo de MCP que sí aguanta producción
Una herramienta MCP débil suele ser un wrapper gigantesco que “hace de todo”. Una herramienta MCP fuerte tiene un alcance estrecho, entradas rígidas y salidas estables.
Reglas básicas:
- una herramienta, un trabajo
- esquema de entrada estricto
- envelope de salida estable
- chequeo de políticas antes de devolver datos
- respuestas con identificadores trazables
import { McpServer } from "@modelcontextprotocol/sdk/server";
const server = new McpServer({ name: "org-context" });
server.tool(
"get_knowhow_item",
{
description: "Read one governed Know-How item by id",
inputSchema: {
type: "object",
properties: { id: { type: "string" } },
required: ["id"],
additionalProperties: false
}
},
async ({ id }, ctx) => {
const item = await ctx.store.read(id);
if (!ctx.policy.canRead(ctx.user, item.policyTag)) {
return {
ok: false,
error: { code: "forbidden", message: "Access not permitted" }
};
}
return {
ok: true,
data: {
id: item.id,
title: item.title,
version: item.version,
summary: ctx.redactor(item.summary)
},
trace: {
requestId: ctx.requestId,
policyTag: item.policyTag
}
};
}
);
El valor está en no convertir el tool en un paso directo a todo tu sistema interno.
El hardening de Docker es parte del diseño MCP
Muchos tutoriales de MCP terminan en “el servidor ya corre”. No alcanza si ese servidor puede leer contexto sensible o disparar acciones.
La base mínima de hardening incluye:
- ejecutar como usuario no root
- usar filesystem de solo lectura cuando sea posible
- montar secrets como archivos
- definir health checks
- restringir el egress de red
- adjuntar correlation IDs a cada ejecución
La documentación de Docker para HEALTHCHECK, Compose healthchecks, rootless/non-root y bind mounts sigue siendo muy útil.
FROM node:22-slim AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci --ignore-scripts
COPY . .
RUN npm run build && npm prune --omit=dev
FROM gcr.io/distroless/nodejs22-debian12:nonroot
WORKDIR /app
COPY --from=build /app/dist ./dist
USER 65532:65532
ENV NODE_ENV=production
CMD ["/nodejs/bin/node", "dist/server.js"]
Ya sea local-first u on-prem, sin límites claros de runtime no hay verdadera confianza operacional.
Por qué una REST API versionada sigue siendo necesaria
MCP es excelente para ejecución nativa de agentes, pero una REST API versionada sigue aportando:
- versionado explícito
- paginación y filtros estables
- auth, rate limits y caching nativos del gateway
- reutilización por agentes, apps y servicios internos
Por eso muchos equipos exponen el mismo contexto gobernado por MCP y por REST. Siguen siendo valiosas las guías de diseño de APIs de Azure, junto con RFC 6585 y RFC 9110 para throttling y Retry-After.
La clave no es duplicar por duplicar, sino especializar:
- MCP para discovery y semántica de tools
- REST para contratos deterministas
Si necesitas ambos, no es una contradicción.
Skills es la capa de empaque, no el plano de datos
Skills funciona muy bien para distribuir intención operativa: qué hacer, qué evitar y qué secuencia seguir.
Sirve especialmente para:
- instrucciones de workflow
- pasos de troubleshooting
- hábitos compartidos de revisión
- guías por rol
Pero Skills por sí solo no resuelve frescura, autorización ni retrieval estructurado. La documentación de Anthropic sobre skills y el repositorio público de anthropics/skills muestran bien el formato.
La división pragmática suele ser:
- el Skill define el flujo y las restricciones
- el Skill llama a un tool MCP o a un endpoint REST
- el runtime registra request, resultado y decisión de política
La observabilidad convierte MCP en un sistema auditable
Si un agente usa mal un tool, deberías poder responder:
- quién hizo la llamada
- qué tool o resource estaba expuesto
- qué inputs se enviaron
- qué decisión de política se aplicó
- qué hash o identificador de resultado volvió
- cuánto tardó
Por eso OpenTelemetry y los logs estructurados no son un lujo. Son el mecanismo para reconstruir incidentes. Los documentos de context propagation y traces son un buen punto de partida. Para retención y auditoría, sirven NIST SP 800-92 y SP 800-53 Rev.5.
{
"ts": "2026-04-03T09:15:00Z",
"event": "tool.execute",
"requestId": "req_7ad2",
"tool": "get_knowhow_item",
"actor": "agent_ops_reader",
"decision": "allow",
"resultHash": "sha256:ab12...",
"latencyMs": 42
}
Si tu sistema no puede producir algo así de reconstruible, el problema principal todavía no es la elección del protocolo.
Dónde encaja puppyone
La mayoría de los proyectos MCP no fallan por el protocolo, sino por el contexto detrás del protocolo:
- el conocimiento está repartido en muchos sistemas
- cada tool ve una verdad distinta
- cuesta aplicar permisos finos
- el versionado y la trazabilidad de auditoría son débiles
Ahí encaja una base de contexto gobernada. Los equipos evalúan puppyone para estructurar Know-How empresarial, aplicar hybrid indexing y distribuir el mismo conocimiento gobernado vía MCP, API o empaquetado de workflow. Así, el servidor MCP deja de reconstruir contexto ad hoc en cada llamada.
Es especialmente útil cuando:
- varios agentes necesitan la misma source of truth
- el mismo conocimiento debe salir por MCP y por API
- las aprobaciones requieren identificadores estables y provenance
- local-first o self-hosted son requisitos reales
Lecturas relacionadas:
- Context Engineering: When RAG Isn't Enough
- Vector Database vs. Context Base: What AI Agents Actually Need in Production
- Puppyone + OpenClaw Integration Playbook for Engineers
Qué hacer ahora
Si estás empezando, no arranques con una gran migración de protocolo. Elige un workflow con mucha lectura y vuelve la base aburridamente fiable:
- define un MCP tool estrecho
- devuelve un response envelope estable
- deja el enforcement fuera del modelo
- añade trace IDs y logs estructurados
- crea un endpoint REST solo cuando un segundo consumidor lo necesite de verdad
Después de eso, ampliar tools, Skills y orquestación será mucho más seguro.
Planifica MCP gobernado con puppyoneGet startedFAQs
Q1. ¿MCP reemplaza a las REST APIs?
No. MCP es fuerte para la ejecución orientada a agentes; REST sigue siendo mejor cuando necesitas contratos estables, controles de gateway y reutilización más amplia.
Q2. ¿Toda capacidad interna debería convertirse en un tool MCP?
No. Los tools demasiado amplios son difíciles de gobernar y de depurar. Empieza con capacidades estrechas, tipadas y predecibles.
Q3. ¿Bastan los Skills por sí solos?
Normalmente no. Los Skills empaquetan muy bien la intención del workflow, pero si importan la frescura, la autorización y la auditabilidad, necesitarás tools MCP o APIs para los datos de runtime.