Guide ultime du Model Context Protocol (MCP)
3 avril 2026Ollie @puppyone
Key takeaways
- MCP ne remplace ni votre modèle de données ni votre couche de gouvernance. Il standardise la manière dont les hôtes d'agents découvrent et invoquent tools, resources et prompts.
- En production, la vraie question n'est presque jamais « MCP ou API », mais quelle surface doit porter la discovery, le déterminisme, le contrôle de politique et l'auditabilité.
- Un bon déploiement MCP garde des tools étroits, des réponses stables et sépare les chemins de lecture et d'écriture.
- Le hardening Docker, le tracing des requêtes et les logs structurés comptent autant que la qualité des prompts, car ce sont eux qui rendent un incident contenable et reconstructible.
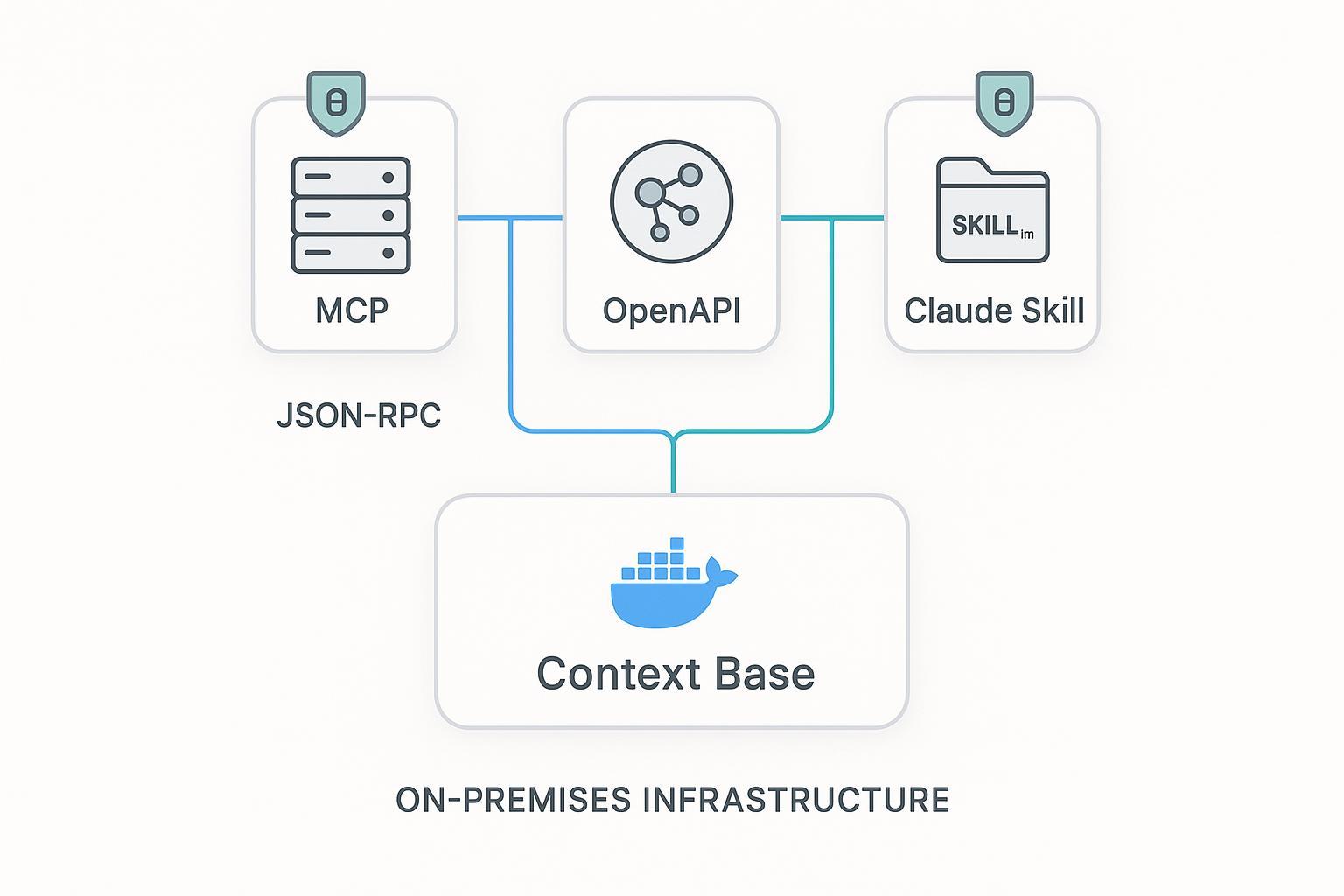
- puppyone devient particulièrement utile lorsque le vrai défi n'est plus le branchement des outils, mais la distribution d'une même base de contexte gouvernée via MCP, API et Skills.
Le vrai rôle de MCP
Beaucoup d'équipes présentent d'abord Model Context Protocol comme « le standard pour connecter des outils aux agents IA ». C'est vrai, mais encore trop vague pour guider une architecture sérieuse.
Une lecture plus utile :
- MCP standardise la découverte des capacités
- MCP standardise l'invocation des capacités
- MCP ne résout pas à lui seul le modelage de connaissance, les politiques ni la stabilité des sorties
La spécification officielle définit MCP comme un protocole basé sur JSON-RPC pour exposer tools, resources et prompts à des runtimes d'agents. Pour cadrer le sujet, voir la spécification, la section lifecycle et l'annonce initiale d'Anthropic sur Model Context Protocol.
En revanche, MCP ne corrige pas :
- des données obsolètes ou contradictoires
- des frontières d'outil trop larges
- une autorisation trop faible
- des pistes d'audit insuffisantes
- des payloads instables qui obligent le modèle à deviner
C'est pourquoi les équipes matures traitent MCP comme un protocole de diffusion, pas comme toute l'architecture.
Quand utiliser MCP, et quand ne pas l'utiliser
Une erreur fréquente consiste à mettre chaque capacité derrière MCP simplement parce que cela paraît moderne. En pratique, il vaut mieux choisir la surface en fonction du rôle.
| Surface | Point fort | Limite | À utiliser quand |
|---|---|---|---|
| Serveur MCP | Discovery, exécution native pour agents, interopérabilité | Les payloads stables et les policies restent à concevoir | Le consommateur est un host d'agents et bénéficie de la sémantique tools/resources |
| API REST | Contrats déterministes, auth/gateways/caches matures | L'agent doit connaître la sémantique des endpoints | Vous avez besoin de contrats durables pour agents, apps et services |
| Skills | Distribution de workflows et de guardrails | Faible comme plan de données temps réel | Vous voulez diffuser des instructions et récupérer les données via MCP/API |
Règle simple :
- capacités orientées discovery : MCP
- capacités orientées contrat : REST
- connaissances orientées workflow : Skills
Cette combinaison reste souvent la plus robuste.
Voir un MCP gouverné avec puppyoneGet startedUn design MCP minimal qui tient en production
Un mauvais tool MCP devient vite un gros wrapper « qui fait tout ». Un bon tool MCP reste étroit, typé et prévisible.
Principes de base :
- un tool, un seul travail
- schéma d'entrée strict
- enveloppe de sortie stable
- vérification de policy avant de renvoyer des données
- identifiants traçables dans la réponse
import { McpServer } from "@modelcontextprotocol/sdk/server";
const server = new McpServer({ name: "org-context" });
server.tool(
"get_knowhow_item",
{
description: "Read one governed Know-How item by id",
inputSchema: {
type: "object",
properties: { id: { type: "string" } },
required: ["id"],
additionalProperties: false
}
},
async ({ id }, ctx) => {
const item = await ctx.store.read(id);
if (!ctx.policy.canRead(ctx.user, item.policyTag)) {
return {
ok: false,
error: { code: "forbidden", message: "Access not permitted" }
};
}
return {
ok: true,
data: {
id: item.id,
title: item.title,
version: item.version,
summary: ctx.redactor(item.summary)
},
trace: {
requestId: ctx.requestId,
policyTag: item.policyTag
}
};
}
);
La valeur vient du fait qu'on refuse d'exposer tout le système interne derrière une seule porte.
Le hardening Docker fait partie du design MCP
Beaucoup de tutoriels s'arrêtent à « le serveur tourne ». Ce n'est pas suffisant si ce serveur lit du contexte sensible ou déclenche des actions.
Base minimale de durcissement :
- exécution en non-root
- filesystem read-only quand c'est possible
- secrets montés comme fichiers
- health checks
- egress réseau limité
- correlation IDs sur chaque exécution
Les docs Docker sur HEALTHCHECK, Compose healthchecks, rootless/non-root et bind mounts restent très utiles.
FROM node:22-slim AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci --ignore-scripts
COPY . .
RUN npm run build && npm prune --omit=dev
FROM gcr.io/distroless/nodejs22-debian12:nonroot
WORKDIR /app
COPY --from=build /app/dist ./dist
USER 65532:65532
ENV NODE_ENV=production
CMD ["/nodejs/bin/node", "dist/server.js"]
Qu'il soit local-first ou on-prem, un runtime sans frontières claires reste difficile à faire confiance.
Pourquoi une API REST versionnée reste nécessaire
MCP est excellent pour l'exécution native des agents, mais une API REST versionnée garde des avantages nets :
- versioning explicite
- pagination et filtres stables
- auth, rate limits et cache au niveau gateway
- réutilisation par agents, apps et services internes
C'est pourquoi beaucoup d'équipes exposent le même contexte gouverné via MCP et via REST. Les guides d'API design d'Azure restent valables, tout comme RFC 6585 et RFC 9110 pour le throttling et Retry-After.
L'enjeu n'est pas de dupliquer, mais de spécialiser :
- MCP pour la discovery et la sémantique de tool
- REST pour les contrats déterministes
Si vous avez besoin des deux, c'est une architecture normale.
Skills est une couche de packaging, pas un plan de données
Skills est très utile pour distribuer une intention opératoire : quoi faire, quoi éviter, et dans quel ordre.
Cas d'usage typiques :
- instructions de workflow
- pas de troubleshooting
- habitudes de review partagées
- guidance par rôle
En revanche, Skills seul ne garantit ni fraîcheur, ni autorisation, ni retrieval structuré. La documentation Anthropic sur skills et le dépôt public anthropics/skills illustrent bien le format.
Le schéma pragmatique :
- le Skill définit le flow et les contraintes
- le Skill appelle un tool MCP ou un endpoint REST
- le runtime journalise request, résultat et décision de policy
L'observabilité rend MCP réellement auditable
Si un agent utilise mal un tool, vous devez pouvoir répondre à :
- qui a déclenché l'appel
- quel tool ou quelle ressource était exposé
- quels inputs ont été fournis
- quelle policy a été appliquée
- quel hash ou identifiant de résultat est revenu
- combien de temps cela a pris
OpenTelemetry et les logs structurés ne sont donc pas accessoires. Les docs sur context propagation et traces sont de bons points de départ. Pour la rétention et l'audit, voir NIST SP 800-92 et SP 800-53 Rev.5.
{
"ts": "2026-04-03T09:15:00Z",
"event": "tool.execute",
"requestId": "req_7ad2",
"tool": "get_knowhow_item",
"actor": "agent_ops_reader",
"decision": "allow",
"resultHash": "sha256:ab12...",
"latencyMs": 42
}
Si votre système ne peut pas produire quelque chose d'aussi reconstructible, le vrai problème n'est pas encore le choix du protocole.
Où puppyone s'insère
La plupart des projets MCP échouent non pas à cause du protocole, mais à cause du contexte derrière le protocole :
- la connaissance est dispersée
- chaque tool voit une vérité différente
- les permissions fines sont difficiles à appliquer
- versioning et audit lineage sont fragiles
Une base de contexte gouvernée vient combler cet écart. Les équipes évaluent puppyone pour structurer leur Know-How, appliquer du hybrid indexing et distribuer le même savoir gouverné via MCP, API ou packaging de workflow. Le serveur MCP n'a alors plus à reconstruire du contexte ad hoc à chaque appel.
Utile surtout quand :
- plusieurs agents partagent la même source de vérité
- la même connaissance doit sortir via MCP et API
- les approbations exigent des identifiants stables et de la provenance
- local-first ou self-hosted est important
Pour aller plus loin :
- Context Engineering: When RAG Isn't Enough
- Vector Database vs. Context Base: What AI Agents Actually Need in Production
- Puppyone + OpenClaw Integration Playbook for Engineers
Que faire maintenant
Si vous débutez, n'ouvrez pas avec une grande migration de protocole. Choisissez un workflow surtout en lecture et rendez-le simplement fiable :
- définir un tool MCP étroit
- renvoyer un envelope stable
- faire appliquer la policy hors du modèle
- ajouter trace IDs et logs structurés
- ne créer une API REST correspondante que lorsqu'un second consommateur en a réellement besoin
Ensuite, vous pourrez étendre tools, Skills et orchestration avec bien moins de risques.
Planifier un rollout MCP avec puppyoneGet startedFAQs
Q1. MCP remplace-t-il les API REST ?
Non. MCP est fort pour l'exécution orientée agents ; REST reste meilleur pour les contrats stables, les contrôles gateway et la réutilisation plus large.
Q2. Chaque capacité interne doit-elle devenir un tool MCP ?
Non. Des tools trop larges sont difficiles à gouverner et à déboguer. Commencez par des capacités étroites, typées et prévisibles.
Q3. Les Skills suffisent-ils à eux seuls ?
Le plus souvent non. Skills emballe bien l'intention du workflow, mais si fraîcheur, autorisation et auditabilité comptent, il faut s'appuyer sur des tools MCP ou des API pour les données runtime.