Guide ultime de l'automatisation du back-office finance
5 février 2026Ollie @puppyone
Points clés
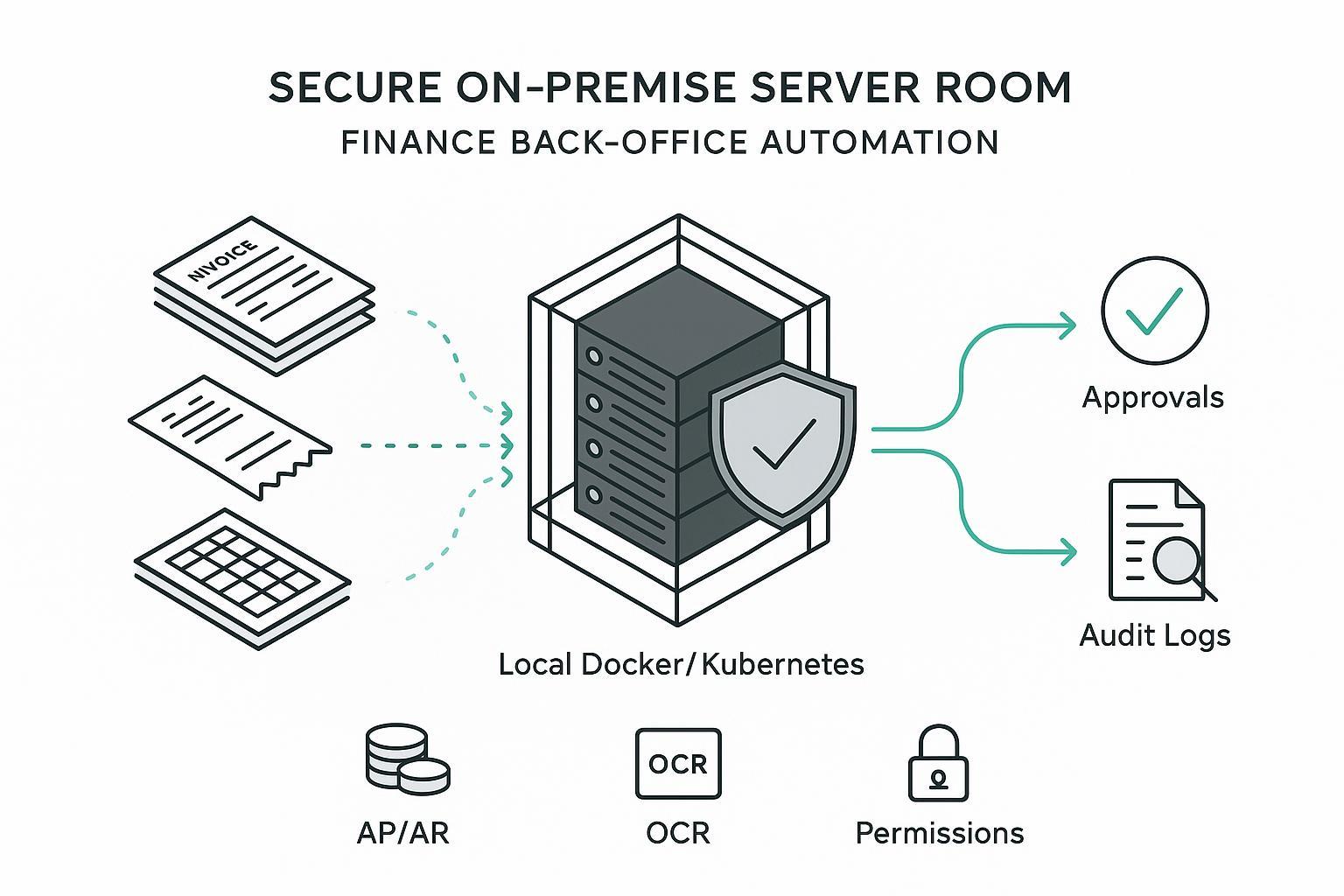
- Les déploiements local-first réduisent le risque de transfert transfrontalier et améliorent le contrôle, tout en augmentant la responsabilité opérationnelle à planifier.
- La récupération déterministe vient de la structuration du « know-how » finance en modèles JSON ou graphe et d’une indexation hybride, pas des seuls vecteurs.
- Les flux agentiques doivent appliquer la ségrégation des fonctions (SoD) avec des points de contrôle human-in-the-loop et une traçabilité complète à chaque étape.
- Les contrôles de conformité essentiels : gouvernance d’accès, chiffrement, journaux d’audit, rétention et cartographie SoD vers ICFR.
- Mesurez ce qui compte : temps de cycle, taux sans toucher, taux d’exception, précision d’extraction et coût par facture.
Pourquoi le local-first compte pour l’automatisation du back-office finance
Local-first signifie que le cœur de l’automatisation (ingestion, parsing, indexation, récupération, orchestration) s’exécute sur une infrastructure que vous contrôlez (Docker/Kubernetes en datacenter ou VPC). Trois raisons : (1) Confidentialité et résidence—garder images de reçus, factures et données fournisseurs en interne limite l’exposition et simplifie la conformité GDPR ; l’EDPB 2024 souligne les tests de nécessité et la supervision humaine. (2) Auditabilité et explicabilité—les décisions de comptabilité ont besoin de raisons traçables ; le local-first permet des pipelines déterministes et des logs explicites. (3) Prédictibilité opérationnelle—latence stable et visibilité des coûts. Pour les modèles d’IA générative on-prem, voir la perspective TrueFoundry.
Le cas d’usage central en AP et AR
Trois types de documents dominent : factures et reçus, feuilles de calcul (répartitions, fournisseurs), e-mails. Automatisation : capture depuis boîtes partagées, SFTP, portails AP ; OCR et document AI pour en-têtes, lignes, totaux, dates, TVA/identifiants fiscaux ; enrichissement avec données de référence et politiques ; routage vers une couche de récupération pour approbations ; application de la SoD et des seuils avec checkpoints humains lorsque la confiance ou le montant le justifient ; comptabilisation en GL/AP avec traçabilité complète ou remontée d’exceptions. Hypatos cite 60–80 % de réduction du temps de cycle ; NetSuite décrit de forts taux de traitement direct. Validez ces chiffres avec vos propres bases.
Comparaison des modèles d’architecture
| Modèle | Résidence des données | Contrôle sur modèles et logs | Prédictibilité latence | Responsabilité opérationnelle |
|---|---|---|---|---|
| SaaS cloud | Limitée par les régions du fournisseur | Faible | Variable | Minimale |
| Hybride | Documents sensibles en local, inférence possible en cloud | Moyenne | Mixte | Modérée |
| Local-first | Dans le pays ou on-prem par défaut | Élevée, contrôle et audit complets | Stable et ajustable | Élevée |
Choisissez le local-first pour les reçus sensibles, documents proches de la paie ou données carte présente, et lorsque les auditeurs exigent des preuves solides de résidence et de contrôle d’accès.
Ingestion et document AI de confiance pour la finance
L’objectif n’est pas 100 % d’extraction automatisée le premier jour mais des données fiables avec confiance et routage clairs. Privilégiez les moteurs qui exposent les confiances par champ et les primitives de mise en page pour concevoir des boucles de révision. La documentation Azure Document Intelligence aide à interpréter confiance et limites. Le YAML d’exemple de l’article en anglais (boîte IMAP, S3, OCR, redaction PII, schéma invoice_v1) sert de base. Évaluez sur votre mix de documents : précision d’extraction pour fournisseur, numéro de facture, date, ID fiscal, devise, totaux, code GL ; en dessous du seuil de confiance → routage vers révision.
Structuration pour une récupération déterministe
Les vecteurs accélèrent la similarité sémantique ; la finance a besoin de réponses reproductibles liées à des sources et règles explicites. Combinez une couche « know-how » structurée (JSON ou graphe) avec une indexation hybride et des plans de requête privilégiant des chemins déterministes. Structurez factures, reçus et politiques en objets typés (Vendor → Invoices → Lines → Approvals → Payment) ; indexez texte et champs (vendor_id, due_date, tax_amount, approval_threshold) ; à la requête, combinez filtres déterministes ou parcours de graphe avec reranking ; enregistrez chemin et sources pour l’audit. ArangoDB HybridRAG et les approches graph-RAG explicables sont des références. L’exemple d’objet JSON de l’article en anglais est réutilisable.
Flux agentiques avec approbations et supervision humaine
L’orchestration agentique aide lorsqu’elle est bornée par des politiques explicites, des seuils et des pauses HITL. Séparez les agents par responsabilité (extraction, vérification de politique, codification GL, coordination des approbations) ; appliquez la SoD pour qu’un même principal ne puisse pas extraire, approuver et comptabiliser ; traitez les éléments incertains ou à risque comme des pauses pour les humains avec instantanés de contexte et actions recommandées. Hyperproof SoD est une référence. L’exemple Rego de l’article en anglais (ap_bot peut lire sous seuil, deny post_gl) illustre le modèle de permissions.
Permissions et distribution pour les agents
Utilisez des contrôles basés sur les rôles et les attributs liés aux groupes IdP et aux tags de documents. Gardez une seule source de vérité pour le contexte et exposez plusieurs protocoles depuis celle-ci pour ne pas dupliquer les permissions ni fragmenter les logs d’audit.
Contrôles de conformité qui comptent vraiment
GDPR (légalité, minimisation, limitation de stockage, contestation des décisions automatisées ; EDPB 2024). SOC 2 (accès, opérations, changement, risque ; Processing Integrity pour les pipelines finance ; AuditBoard SOC 2). PCI DSS 4.0 en présence de données carte (accès, MFA, chiffrement, surveillance). SOX 404 : liez les contrôles système aux assertions ICFR et conservez des traînées d’audit complètes et immuables (Exabeam SOX 404). Documentez les flux de données et la rétention, reliez les politiques aux contrôles techniques et automatisez la collecte de preuves.
Observabilité et évaluation continue
Qualité d’extraction : échantillonnage hebdomadaire, précision/rappel par champ. Flux : temps de cycle, taux sans toucher, motifs d’exception, respect des SLA d’approbation. Identifiants de corrélation de bout en bout pour reconstruire les chaînes d’événements. AuditBoard rétention des logs de sécurité.
Exemple pratique avec une context base local-first
Avis : puppyone est notre produit. Une context base s’exécute en Docker sur votre infrastructure pour ingérer et structurer reçus, factures et fils d’e-mails en « know-how » machine-readable, indexer texte et champs et exposer le résultat aux agents via plusieurs protocoles. Bénéfice : une source de vérité, des plans de récupération déterministes et des journaux d’audit unifiés. Alternative : OCR open-source, Postgres + vector, graphe, moteur de politiques type OPA.
Playbook de migration : des boîtes partagées aux pipelines déterministes
(1) Base et risque : cartographier flux, classifier documents, bases légales, rétention, corpus de 200–500 documents. (2) Fondation local-first : Kubernetes/Docker, chiffrement, TLS, SSO, logging, sauvegardes, connecteurs IMAP/S3. (3) Évaluation document AI : tests A/B, seuils de confiance, révision HITL. (4) Structure et indexation : schémas JSON, index hybrides, filtres déterministes et parcours de graphe. (5) Orchestration : seuils d’approbation, SoD, escalade, pauses HITL. (6) Contrôles et preuves : mappage GDPR, SOC 2, PCI, SOX, capture automatique de preuves. (7) Déploiement : une entité ou unité d’abord, puis élargir ; surveiller les KPIs et corriger les défaillances.
KPIs et fourchettes de résultats réalistes
Coût par facture, temps de cycle, taux sans toucher, taux d’exception, précision d’extraction, respect des SLA d’approbation. Hypatos et NetSuite donnent des fourchettes indicatives ; validez avec votre base. Exemple : si votre cycle de base est de 10 jours et 20 % sans toucher, un objectif de phase 1 raisonnable pourrait être 30–40 % d’amélioration du cycle et +15–25 points de taux sans toucher avec HITL et contrôles adaptés.
Critères de choix des outils
Document AI (langues, tableaux, confiances), stockage et indexation (hybride, filtres déterministes, traçabilité), orchestration (moteur de flux + couche de politique/SoD avec IdP), observabilité (IDs de corrélation, métriques, export de preuves), déploiement (local-first/on-prem, chiffrement, sauvegardes, HA/DR). Ressources : PCI DSS 4.0, AuditBoard SOC 2, patterns de conception agentiques Google Cloud.
Prochaines étapes
Si vous explorez l’automatisation local-first du back-office finance et souhaitez voir comment une context base s’intègre à votre mix de documents, IAM et flux d’approbation, réservez une courte session avec notre équipe. Réserver une démo.