Guide ultime de l'indexation hybride pour l'apprentissage contextuel
7 février 2026Ollie @puppyone
Points clés
- La récupération hybride et consciente des champs bat « simplement allonger le contexte ». Il faut des tranches déterministes par étape, pas un mur de texte.
- Les limites des modèles sont réelles : les benchmarks montrent des taux élevés de contexte ignoré ou mal utilisé ; concevez votre stack pour prévenir, détecter et corriger ces erreurs.
- Pour Opérations/Support : associez un Know-How JSON/Graphe à une indexation hybride et une boucle agentique planificateur→exécuteur→vérificateur pour l’adhérence aux étapes et l’auditabilité.
Pourquoi les modèles ignorent et malutilisent le contexte pour les SOPs
Un benchmark (CL-bench : 500 contextes, 1 899 tâches, 31 607 rubriques) montre la fragilité des modèles lorsqu’ils apprennent du contexte fourni : dix modèles de frontière ne résolvent qu’environ 17,2 % des tâches en moyenne ; le meilleur atteint ~23,7 % même en mode raisonnement. L’erreur dominante est de ne pas utiliser correctement le contexte—omettre des détails clés ou appliquer la mauvaise règle. Voir CL-bench paper (arXiv), Tencent Hunyuan research blog. Le contexte long seul ne corrige pas ; LongBench v2 etc. montrent que une meilleure fenêtre laisse des lacunes en raisonnement et agrégation (LongBench v2 ACL). Pour les SOPs multi-étapes, cela se traduit par saut d’étape, dérive d’instruction ou actions non sûres.
Modes d’échec courants du RAG naïf pour l’exécution de SOPs
Les stacks RAG échouent sur les flux opérationnels car l’unité de récupération ne correspond pas à l’unité d’action : chunks trop larges → dérive ; champs non pondérés enfouissent les tokens critiques. Les prompts monolithiques encouragent l’improvisation. Remède : concevoir pour une récupération déterministe et une exécution vérifiable.
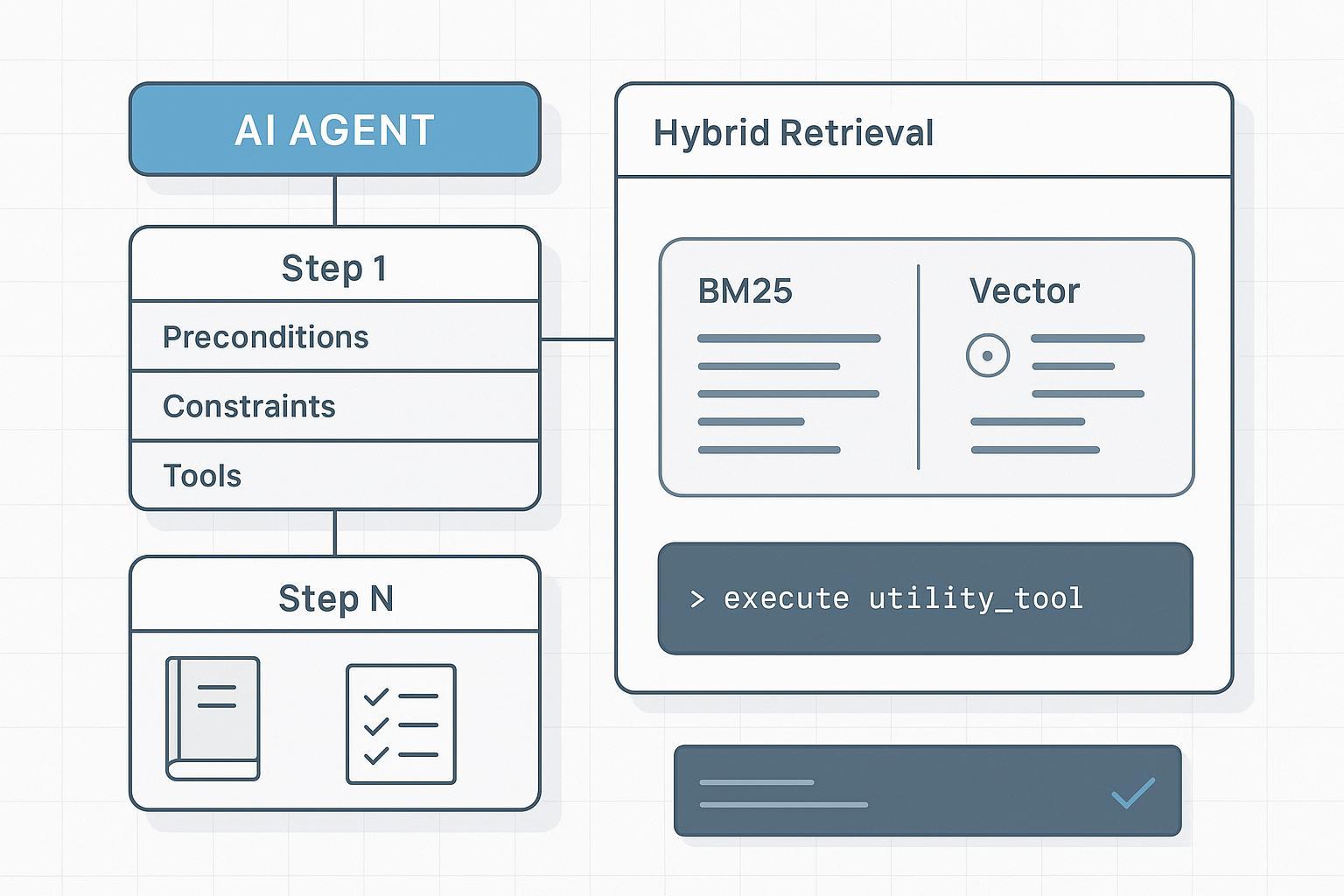
Fondements : modélisez vos SOPs en Know-How JSON/Graphe
Les agents ont besoin de connaissances structurées et par champs. Un schéma pratique encode les étapes, dépendances, contraintes et méthodes de vérification. L’exemple JSON de l’article en anglais (sop.router.reset.v3, step_number, preconditions, constraints, tools_allowed, checkpoints, verification_method, dependencies) reste inchangé. Ainsi le récupérateur peut pondérer titre, step_number, preconditions et constraints plus que le récit. Context Base : puppyone About.
Indexation hybride pour l’apprentissage contextuel dans des manuels longs et denses
Le cœur n’est pas « plus de contexte » mais « de meilleures unités de récupération et signaux de ranking ». En pratique : indexation hybride avec conscience des champs et un petit passage de rerank.
- Combinez signaux lexicaux creux (BM25/BM25F) et vecteurs denses. Lexical : IDs exacts, avertissements, contraintes ; dense : meilleur rappel sur les étapes formulées sémantiquement. Références : Elastic — What is hybrid search, Elastic retrievers and RRF, Weaviate — Hybrid search explained.
- Boosts conscients des champs : privilégier titre, step_number, preconditions, constraints, tools_allowed par rapport au récit.
- Récupérer par étape des tranches minimales et déterministes ; ne pas nourrir toute la SOP à chaque fois.
- Optionnel : rerank du top-k avec cross-encoder ou reranker conscient de la structure.
RAG agentique pour les SOPs : planificateur → récupérateur → exécuteur → vérificateur
Le planificateur décompose en intents par étape et formule des requêtes ciblées (step_number, outils requis). Le récupérateur renvoie les tranches minimales avec IDs. L’exécuteur n’appelle que les outils énumérés avec paramètres validés par schéma et cite les slice IDs. Le vérificateur contrôle checkpoints et contraintes avant d’avancer ; en cas d’écart, replan ou revue humaine. Voir Anthropic — Multi-agent research system.
Exemple pratique : une étape de bout en bout
Avis : Puppyone est notre produit ; mentionné ici de façon neutre comme une possible context base. Plus sur puppyone. Objectif : exécuter l’étape 7 de « Router Safe Reset » avec récupération hybride et boucle agentique. Plan de requête, pseudocode (style Python) et log d’état comme dans l’article en anglais. La même boucle peut être implémentée avec Elastic/OpenSearch/Vespa/Weaviate ou RDBMS+pgvector+BM25.
Playbook d’évaluation : prouver la fiabilité, puis scaler
Qualité de récupération : Recall@k, MRR/nDCG par étape, Context Precision, Context Sufficiency. Exécution : Step Adherence %, Action Success Rate, Instruction Drift Rate, incidents pour 1 000 exécutions, Time-to-Resolution. Par étape SOP stocker les slice IDs de ground truth et les patterns outil/résultat attendus ; affirmer que l’exécuteur cite le slice utilisé et que les checkpoints passent avant d’avancer. Synthèse : RAG evaluation survey (2024).
Alternatives et parité
| Stack | Options de fusion hybride | Boosts conscients des champs | Fit on-prem/VPC | Notes |
|---|---|---|---|---|
| Elasticsearch | RRF, mélange pondéré | BM25F, boosts multi-champs | Self-host mature | APIs retriever, rerankers cross-encoder |
| OpenSearch | Pondéré + patterns rerank | Boosts par analyseurs | Self-host first-class | Travail perf vector |
| Vespa | Lexical + ANN + rerank | Features par champ | Self-host, scale-out | Pipeline ranking/ML |
| Weaviate | RRF/hybride pondéré | Poids/filtres de propriété | Managed + self-host | Docs hybride claires |
Pour l’approche « Agent Context Base » : par ex. puppyone. Critères : scoring conscient des champs, garanties de slicing déterministe, logs d’audit, support de harness d’évaluation.
À quoi ressemble « bien » en pratique
En pilotes, le passage de prompts document entier à des tranches par étape et par champs réduit la dérive d’instruction et augmente l’adhérence aux étapes. L’indexation hybride pour l’apprentissage contextuel met la surface exacte des contraintes dans les mains de l’agent et exige une vérification avant de continuer.
Prochaines étapes
Si vous évaluez une approche de qualité production pour l’automatisation des SOPs—Know-How structuré, indexation hybride et boucle planificateur→exécuteur→vérificateur—examinons ensemble votre corpus et contraintes. Réservez une démo technique centrée sur indexation hybride + RAG agentique pour votre environnement.