Guide ultime de l'Agent Context Base : indexation hybride
12 février 2026Ollie @puppyone
Elevating from RAG to an Agent Context Base: Puppyone’s hybrid indexing and deterministic retrieval for mission‑critical agents
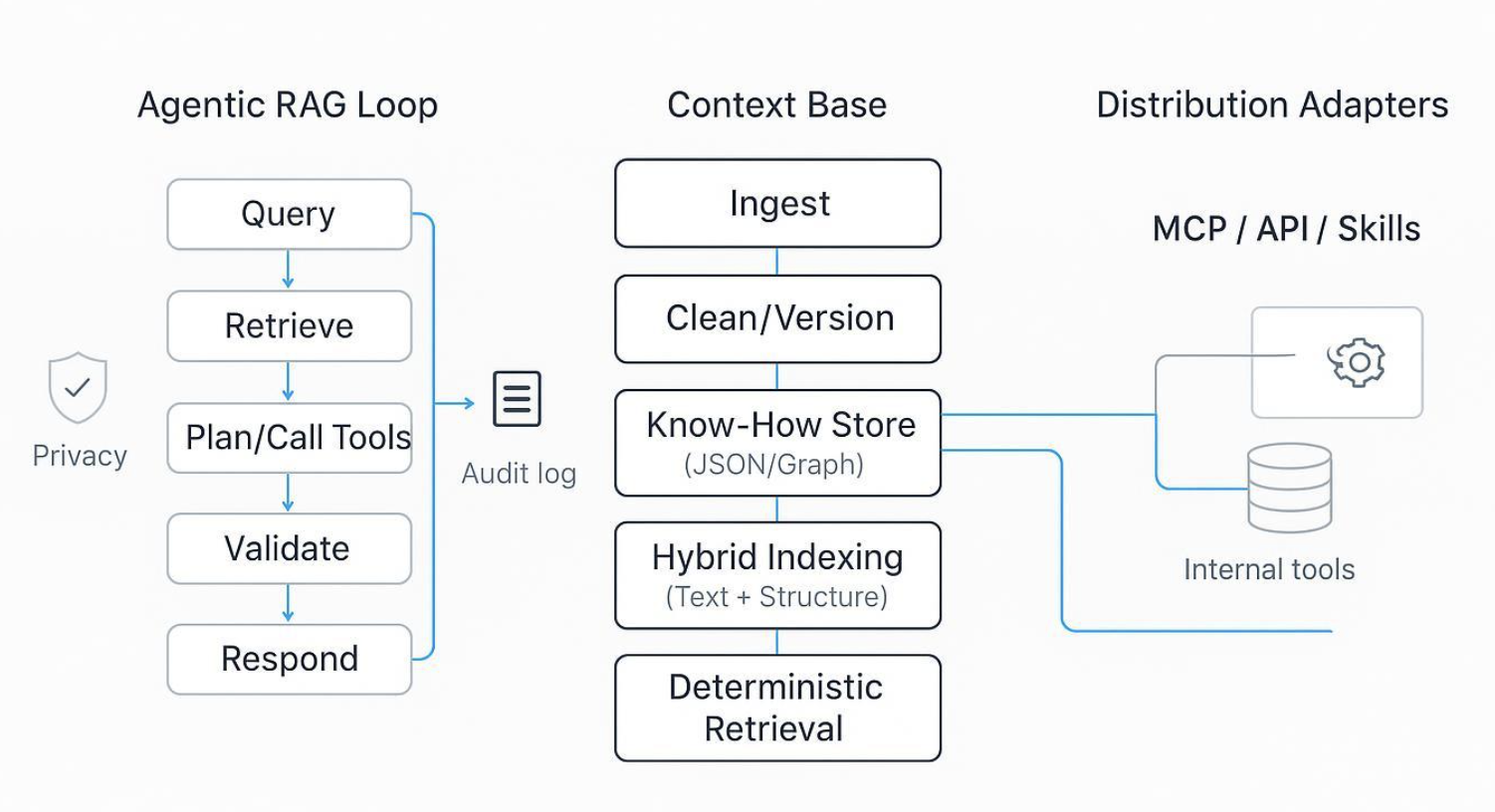
Modern agent teams don’t fail because they lack embeddings—they fail when retrieval is unpredictable, hard to audit, and impossible to reproduce under SLAs. If you’re building agents that must handle IDs, policies, SKUs, and compliance logic, a vector‑only RAG stack won’t cut it. The alternative isn’t “more prompts” or “bigger rerankers,” but a shift in the data foundation: move from a fuzzy, document‑centric RAG system to an Agent Context Base that stores machine‑readable Know‑How and retrieves it deterministically via hybrid indexing.
Key takeaways
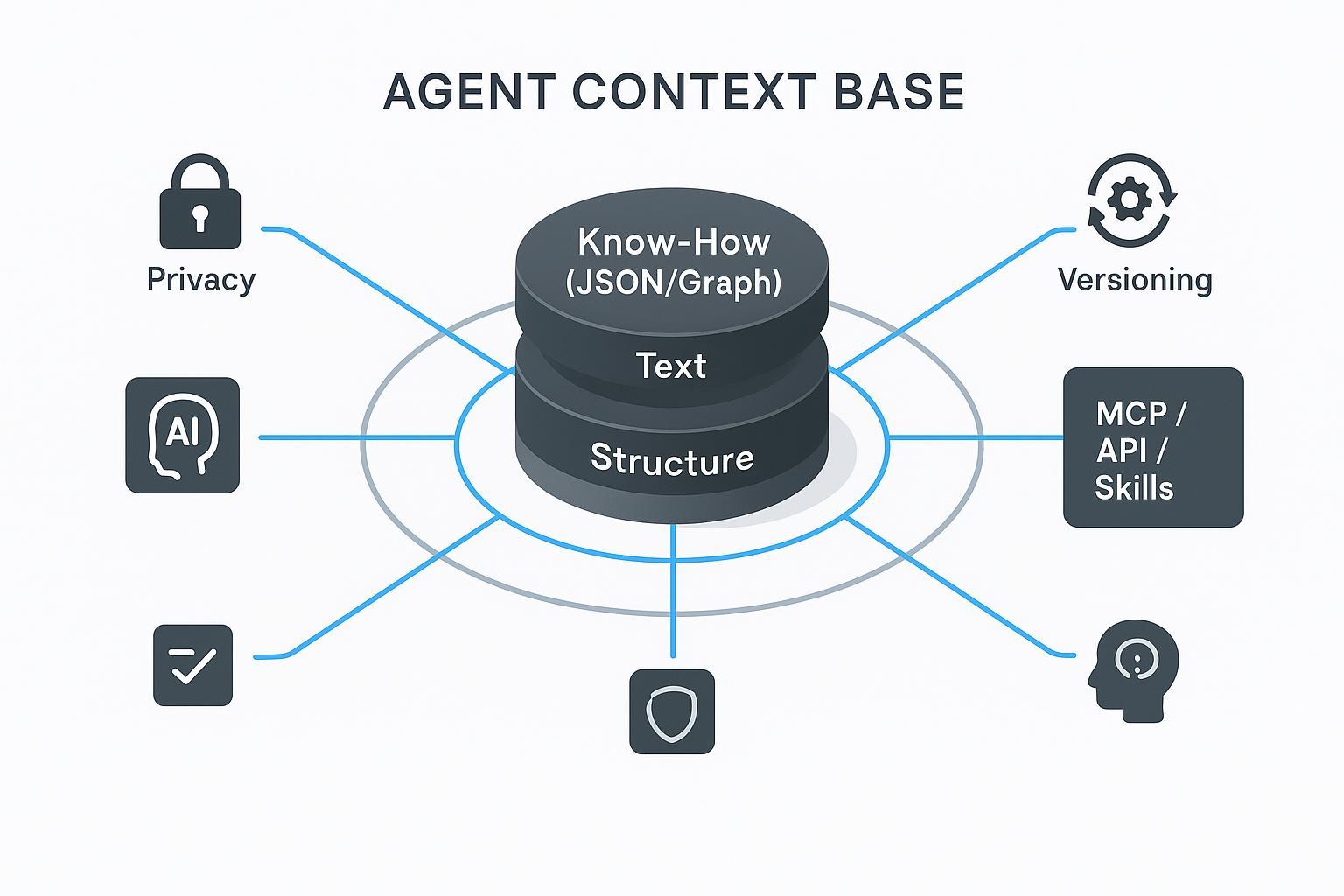
- An Agent Context Base treats organizational knowledge as structured Know‑How (JSON/Graph), not just text, making retrieval auditable and reproducible.
- Hybrid indexing (Text + Structure) improves precision on exact terms and numeric facts versus vector‑only approaches, and is widely supported across platforms like Azure, Oracle, Google, and Weaviate.
- Deterministic retrieval stems from schema discipline, composite keys, ranking rules, and logged fusion parameters—not from embeddings alone.
- MCP‑based distribution aligns tools/skills and context with Agentic RAG orchestration so agents can call the right capabilities with the right context.
- Local‑first deployment via Docker helps keep sensitive data inside your boundary while retaining performance and governance.
What is an Agent Context Base?
An Agent Context Base is a context system designed for AI consumption. Instead of warehousing unstructured documents and hoping similarity search finds the right fragments, it stores organizational Know‑How as machine‑readable JSON/Graph—procedures, policies, skills, IDs, and relationships. Retrieval then operates over both text and structure to produce predictable, auditable results. For a primer on how this concept is framed in practice, see the overview on the puppyone homepage and the discussion of hybrid indexing and deterministic retrieval in the puppyone FAQ.
Think of it this way: text is the narrative, structure is the map. Agents need both to arrive at the same answer every time.
Why RAG alone falls short in mission‑critical settings
Vector‑only RAG is excellent at capturing meaning, but several gaps appear when SLAs and audits enter the picture:
- Exactness and auditability: IDs, SKUs, codes, and policy clauses often require lexical matches, filters, or structural joins. Purely semantic similarity can skip a precise hit or reorder candidates unpredictably.
- Governance and versioning: Document chunks don’t naturally encode versions, provenance, or rollbacks. Reconstructing “what the agent saw” becomes tedious.
- Ranking determinism: Fusion, reranking, and retrieval parameters can drift. Without structured constraints and logged rules, identical prompts may surface different contexts.
Hybrid indexing and deterministic retrieval
Across major platforms, hybrid search—combining lexical and vector signals—has become a first‑class pattern for better grounding and precision in generative systems. Microsoft describes hybrid search as running full‑text and vector in one request with fusion and filtering to improve relevance for RAG scenarios, as outlined in Azure’s hybrid search overview (2025). Oracle’s 26ai documentation introduces Hybrid Vector Indexes that unify Oracle Text and Vector Search with JSON‑configurable fusion. Google highlights hybrid benefits in Vertex AI Vector Search, and engines like Weaviate document fusion strategies (e.g., relative score fusion and rank fusion) in their hybrid search concepts.
Deterministic retrieval, however, requires more than hybrid fusion. It’s a design choice:
- Model knowledge as JSON/Graph with keys, relations, and constraints.
- Use composite indexes that bind text fields to structured identifiers.
- Apply explicit ranking rules and fixed fusion parameters (and log them).
- Enforce filters and scopes (e.g., project, version, jurisdiction) at query time.
- Emit a retrieval trace so identical inputs produce identical context packs.
Decision matrix (executive view):
| Mode | Strengths | Weaknesses | Fit for mission‑critical agents |
|---|---|---|---|
| Vector‑only | Strong semantic recall; fast to start | Weak on exact IDs/codes/numbers; harder to audit deterministically | Often insufficient alone for SLAs |
| Hybrid (text + vector) | Combines semantics with lexical precision; vendor‑supported fusion | More tuning; score alignment needed | Strong default; pair with structure for determinism |
| Structured JSON/Graph + Hybrid | Deterministic keys/relations; auditable, reproducible results | Upfront schema work; governance discipline | Best fit where accuracy and traceability are required |
Representing Know‑How as JSON and Graph
A minimal Know‑How object might encode a policy or skill with deterministic lookup keys and human‑readable text for grounding. Here’s a compact illustration:
{
"type": "policy_clause",
"id": "FIN-GL-7.3",
"title": "Revenue recognition cutoff",
"jurisdiction": "US",
"version": "2025-10",
"conditions": ["close_date <= fiscal_q_end", "materiality > 10k"],
"steps": ["validate_docs", "apply_policy", "log_exception"],
"text": "Revenue after quarter end must be deferred unless..."
}
- Determinism: id + jurisdiction + version form a composite key for precise retrieval.
- Hybrid indexing: text anchors semantic similarity; keys and conditions enable exact filters and joins.
- Auditability: steps and version make the agent’s decision path traceable.
When you store thousands of such objects—and related entities in a graph (e.g., clauses linked to products, geographies, or workflows)—you can answer both “what does the policy say?” and “which clause applies to this SKU and region?” with the same retrieval plan.
MCP distribution and Agentic RAG orchestration
Agentic RAG adds planning and tool choice to the loop: the agent decides when to retrieve, which source to query, and which tool to invoke. The Model Context Protocol specification (2025‑11‑25) formalizes how tools, resources, and prompts can be exposed and consumed across agents and environments. In practice, this means your Context Base can publish relevant skills and datasets as MCP servers, while clients (e.g., IDEs, service agents) consume them with authorization and tracing.
Industry overviews describe agents evaluating context quality and coordinating specialized roles; for example, Arize outlines these coordination patterns in Understanding Agentic RAG. The key is observability: retrieval traces plus tool‑call logs should make it clear why the agent selected a given clause, dataset, or calculator.
Deployment choices and a privacy checklist
Many teams require a private, VPC‑bounded setup. A Local‑First architecture—running the kernel via Docker on your own infrastructure—keeps sensitive data inside your boundary while maintaining performance. For a brief overview of this posture, see the puppyone About page.
A practical privacy checklist for an Agent Context Base:
- Confirm that ingestion, indexing, and retrieval run entirely inside your VPC.
- Validate that logs and traces redact sensitive fields and remain within your logging boundary.
- Ensure data residency controls for all sources; verify container images and supply‑chain attestations.
Evaluation checklist and pilot playbook
Start with a small, representative workload and measure what matters:
- Determinism and reproducibility: with fixed prompts and the same context snapshot, do you get identical retrieval sets and ranks? Log fusion parameters, filters, and versions.
- Retrieval quality: precision@k and groundedness on policy/ID‑heavy queries; compare vector‑only vs. hybrid vs. structured+hybrid.
- Performance: p95 latency for retrieval + generation under hybrid queries; examine the cost of filters and rerankers.
- Governance: versioned context snapshots, rollback tests, and impact analysis; access controls by project and jurisdiction.
- Deployment boundary: verify local‑first Docker/VPC operation; confirm that no data or telemetry exits unintentionally.
Two short case vignettes
- Financial controls assistant: A finance team encodes revenue‑recognition clauses as JSON objects keyed by jurisdiction and version, with a graph linking clauses to product lines. Hybrid indexing surfaces the clause with exact ID matches; semantic fields provide grounding text. Deterministic retrieval plus retrieval traces reduce audit prep time and stabilize answers across monthly closes.
- Internal knowledge base assistant: An engineering org stores runbooks, SLAs, and escalation policies as structured Know‑How with composite keys (service, severity, region). Agents retrieve the exact runbook and version for an incident, attach a human‑readable summary, and log each step. Reproducibility improves hand‑offs and post‑mortems.
Example: where Puppyone fits (neutral reference)
In environments that need structured Know‑How, hybrid indexing, and private operation, a Context Base such as puppyone can be used to ingest, clean, version, and govern knowledge, store it as JSON/Graph, and retrieve it deterministically. The FAQ outlines how hybrid indexing supports deterministic retrieval and governance in practice; see puppyone FAQ. For teams standardizing tool access, context and capabilities can be distributed as MCP, API, or skills while keeping the kernel local‑first.
Further reading
- Hybrid search concepts and practices: Azure hybrid search overview (2025); Oracle 26ai Hybrid Vector Indexes; Google Vertex AI hybrid search; Weaviate hybrid search concepts.
- Agentic RAG and MCP: Model Context Protocol specification (2025‑11‑25); Understanding Agentic RAG (Arize).
Closing and next steps
If your evaluation criteria include determinism, auditability, and a private deployment model, run a two‑week pilot on a narrow, policy‑ or ID‑heavy workload. If you want a starting point for scoping and cost modeling, review the puppyone pricing page and map it to your deployment boundary and SLA targets.