Model Context Protocol(MCP)完全ガイド
2026年4月3日Ollie @puppyone
Key takeaways
- MCP はデータモデルやガバナンス層の代替ではありません。agent host が tools、resources、prompts を発見し実行する方法を標準化するものです。
- 本番環境での本当の判断は「MCP か API か」ではなく、どのインターフェースに discovery、determinism、policy enforcement、auditability を持たせるかです。
- よい MCP 導入では tool の責務を狭くし、安定した response envelope を返し、read path と write path を分離します。
- Docker の hardening、request tracing、structured logs は prompt quality と同じくらい重要です。事故を止められるか、再現できるかを決めるからです。
- 課題が「知識の複製」ではなく「同じ governed context を MCP、API、Skills へ配布すること」に変わったとき、puppyone が役立ちます。
MCP の本当の役割
多くのチームは Model Context Protocol を「AI エージェントに tool をつなぐ標準」として理解します。それ自体は間違っていませんが、設計判断にはまだ粗い表現です。
より実務的な見方は次の通りです。
- MCP は capability discovery を標準化する
- MCP は capability invocation を標準化する
- MCP は knowledge modeling、policy design、stable output を自動では与えない
公式仕様では、MCP は JSON-RPC ベースで tools、resources、prompts を agent runtime に公開するためのプロトコルです。Model Context Protocol specification、lifecycle、そして Anthropic の announcement を読むと位置づけがつかみやすくなります。
一方で、MCP だけでは解決しません。
- 古いデータや矛盾したデータ
- 広すぎる tool boundary
- 弱い authorization
- 不十分な audit trail
- モデルに推測を強いる不安定な payload
だからこそ、成熟したチームは MCP を「delivery protocol」として扱い、アーキテクチャ全体の代替品にはしません。
いつ MCP を使い、いつ使わないか
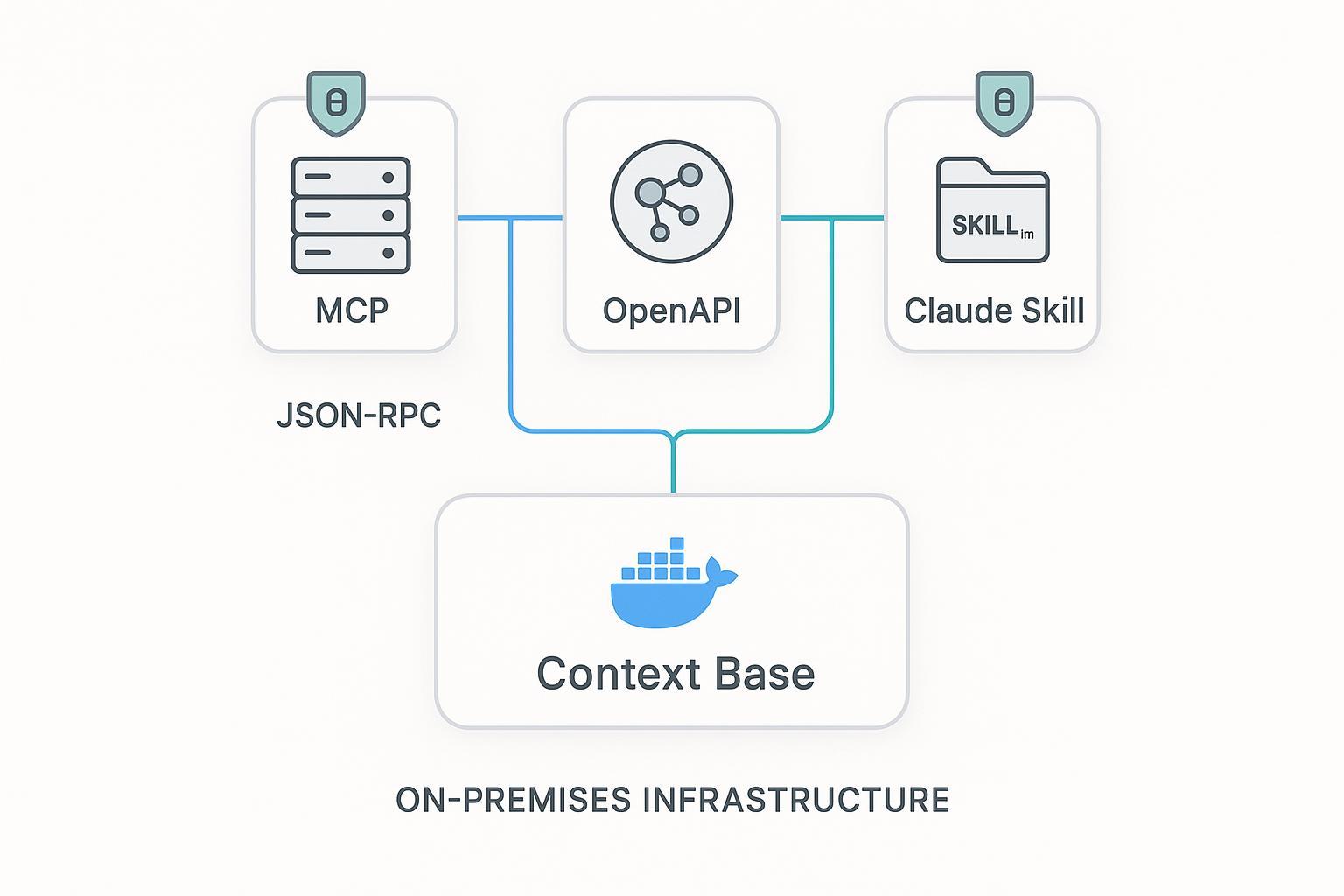
MCP が新しいからという理由だけで、すべての capability を MCP に押し込むのはよくある失敗です。実際には、役割に応じて surface を選び分けた方がうまくいきます。
| Surface | 強み | 弱み | 向いているケース |
|---|---|---|---|
| MCP server | discovery、agent-native execution、host interoperability | stable payload と policy は自分で設計する必要がある | caller が agent host であり、tools/resources semantics を活かせるとき |
| REST API | deterministic contract、成熟した auth / cache / gateway | agent 側が endpoint semantics を理解する必要がある | agent・app・internal service で長期に再利用する contract が必要なとき |
| Skills | workflow instructions と guardrails の配布 | live data plane には弱い | 手順や運用知識を配り、runtime data は MCP / API に任せたいとき |
実務では次のルールが役立ちます。
- discovery-heavy な能力は MCP
- contract-heavy な能力は REST
- workflow-heavy な知識は Skills
つまり、本番では MCP、REST、Skills を併用するのが自然です。
puppyoneで統制されたMCP配布を見るGet started本番で壊れにくい最小 MCP 設計
弱い MCP tool は「何でもできる大きな関数」になりがちです。強い MCP tool は、責務が狭く、入力が厳密で、出力が安定しています。
そのための基本は次の通りです。
- 1 tool = 1 job
- strict input schema
- stable output envelope
- data を返す前に policy check
- trace 可能な identifier を含める
import { McpServer } from "@modelcontextprotocol/sdk/server";
const server = new McpServer({ name: "org-context" });
server.tool(
"get_knowhow_item",
{
description: "Read one governed Know-How item by id",
inputSchema: {
type: "object",
properties: { id: { type: "string" } },
required: ["id"],
additionalProperties: false
}
},
async ({ id }, ctx) => {
const item = await ctx.store.read(id);
if (!ctx.policy.canRead(ctx.user, item.policyTag)) {
return {
ok: false,
error: { code: "forbidden", message: "Access not permitted" }
};
}
return {
ok: true,
data: {
id: item.id,
title: item.title,
version: item.version,
summary: ctx.redactor(item.summary)
},
trace: {
requestId: ctx.requestId,
policyTag: item.policyTag
}
};
}
);
本番価値は派手さではなく、「内部システムの広い権限をそのまま露出しない」点にあります。
Docker hardening も MCP 設計の一部
MCP の紹介記事の多くは「server が起動した」で終わります。しかし、その server が sensitive context を読み、internal tools を呼び、場合によっては write action を起こすなら、それでは不十分です。
最低限の hardening は次のようなものです。
- non-root user で実行する
- 可能な限り read-only filesystem を使う
- secret は image に焼かず file mount する
- health check を入れる
- network egress を制限する
- request ごとに correlation ID を付ける
Docker docs の HEALTHCHECK、Compose healthchecks、rootless tips、bind mounts はそのまま実装に役立ちます。
FROM node:22-slim AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci --ignore-scripts
COPY . .
RUN npm run build && npm prune --omit=dev
FROM gcr.io/distroless/nodejs22-debian12:nonroot
WORKDIR /app
COPY --from=build /app/dist ./dist
USER 65532:65532
ENV NODE_ENV=production
CMD ["/nodejs/bin/node", "dist/server.js"]
ローカル実行でもオンプレでも、runtime boundary が明確でなければ trustworthy にはなりません。
なぜ versioned REST API がまだ必要なのか
MCP は agent-native execution に強い一方、REST API には依然として明確な価値があります。
- explicit versioning
- stable pagination と filter semantics
- gateway-native auth、rate limit、cache
- agent 以外の consumer でも再利用しやすい
そのため、多くのチームは同じ governed context を MCP と REST の両方で公開します。Azure Architecture Center の API design guidance は今でも有効ですし、RFC 6585 と RFC 9110 は throttling の実装に役立ちます。
重要なのは duplication ではなく役割分担です。
- MCP は discovery と tool semantics
- REST は deterministic contract
両方必要なら、それは自然な構成です。
Skills は packaging layer であって data plane ではない
Skills の強みは、手順や guardrails を共有できることです。つまり次のような用途に向いています。
- repeatable workflow instructions
- troubleshooting steps
- shared review habits
- role-specific guidance
しかし Skills 単体では freshness、authorization、structured retrieval を担えません。Anthropic の skills docs や anthropics/skills repository は、フォーマットの参考として十分です。
実務上は次の分担が扱いやすいです。
- Skill が flow と constraints を定義する
- Skill が MCP tool か REST endpoint を呼ぶ
- runtime が request、result、policy decision を記録する
これで instruction と data delivery を分離できます。
Observability があって初めて MCP は audit できる
agent が tool を誤用したとき、少なくとも次は答えられなければいけません。
- 誰が呼んだのか
- どの tool / resource が露出していたのか
- 入力は何だったのか
- どの policy decision が適用されたのか
- どの result hash / record id が返ったのか
- どれくらい時間がかかったのか
そのため OpenTelemetry と structured logs は optional ではありません。context propagation と traces の docs はよい出発点です。さらに、NIST SP 800-92 draft revision と SP 800-53 Rev.5 は retention と audit planning の整理に使えます。
{
"ts": "2026-04-03T09:15:00Z",
"event": "tool.execute",
"requestId": "req_7ad2",
"tool": "get_knowhow_item",
"actor": "agent_ops_reader",
"decision": "allow",
"resultHash": "sha256:ab12...",
"latencyMs": 42
}
この程度の再構成性が出せないなら、いま一番重要なのは protocol choice ではありません。
puppyone が解決する層
多くの MCP プロジェクトが失敗する理由は protocol の不理解ではなく、protocol の背後にある context が散らかっていることです。
- knowledge が複数システムに分散している
- tool ごとに見える内容が違う
- permission を細かく切れない
- versioning と audit lineage が弱い
ここで puppyone のような governed context base が意味を持ちます。enterprise Know-How を構造化し、hybrid indexing を付け、同じ governed knowledge を MCP、API、workflow packaging に配布できるからです。すると MCP server は毎回 ad hoc に context を組み立てる必要がなくなり、curated artifact を返せるようになります。
特に次の条件で効果が出ます。
- 複数 agent が同じ source of truth を使う
- 同じ knowledge を MCP と API の両方に出す
- approval 時に stable identifier と provenance が必要
- local-first / self-hosted が重要
関連する読み物:
- Context Engineering: When RAG Isn't Enough
- Vector Database vs. Context Base: What AI Agents Actually Need in Production
- Puppyone + OpenClaw Integration Playbook for Engineers
次にやること
初期段階なら、大規模な protocol migration から始めない方が安全です。まず 1 つの read-heavy workflow を選び、次を徹底します。
- narrow MCP tool を 1 つ定義する
- stable response envelope を返す
- policy enforcement を model の外に置く
- trace ID と structured logs を入れる
- 本当に別 consumer が必要になった時だけ REST endpoint を足す
基礎が安定してから tools、Skills、orchestration を広げた方が、あとで崩れません。
puppyoneで統制MCP導入を設計するGet startedFAQs
Q1. MCP は REST API を置き換えますか?
置き換えません。MCP は agent-facing execution に強い一方、REST は host-agnostic な安定契約や gateway control、service reuse に向いています。
Q2. すべての internal capability を MCP tool にすべきですか?
いいえ。広すぎる tool は govern しにくく、debug もしづらいです。まずは狭く、型があり、出力が予測可能な capability から始めるべきです。
Q3. Skills だけあれば十分ですか?
通常は十分ではありません。Skills は workflow intent を配布するのに向いていますが、freshness、authorization、auditability が重要なら、runtime data は MCP tool か API に依存する必要があります。