Gestão de contexto de agentes IA — Guia de sessão e memória
11 de fevereiro de 2026Ollie @puppyone
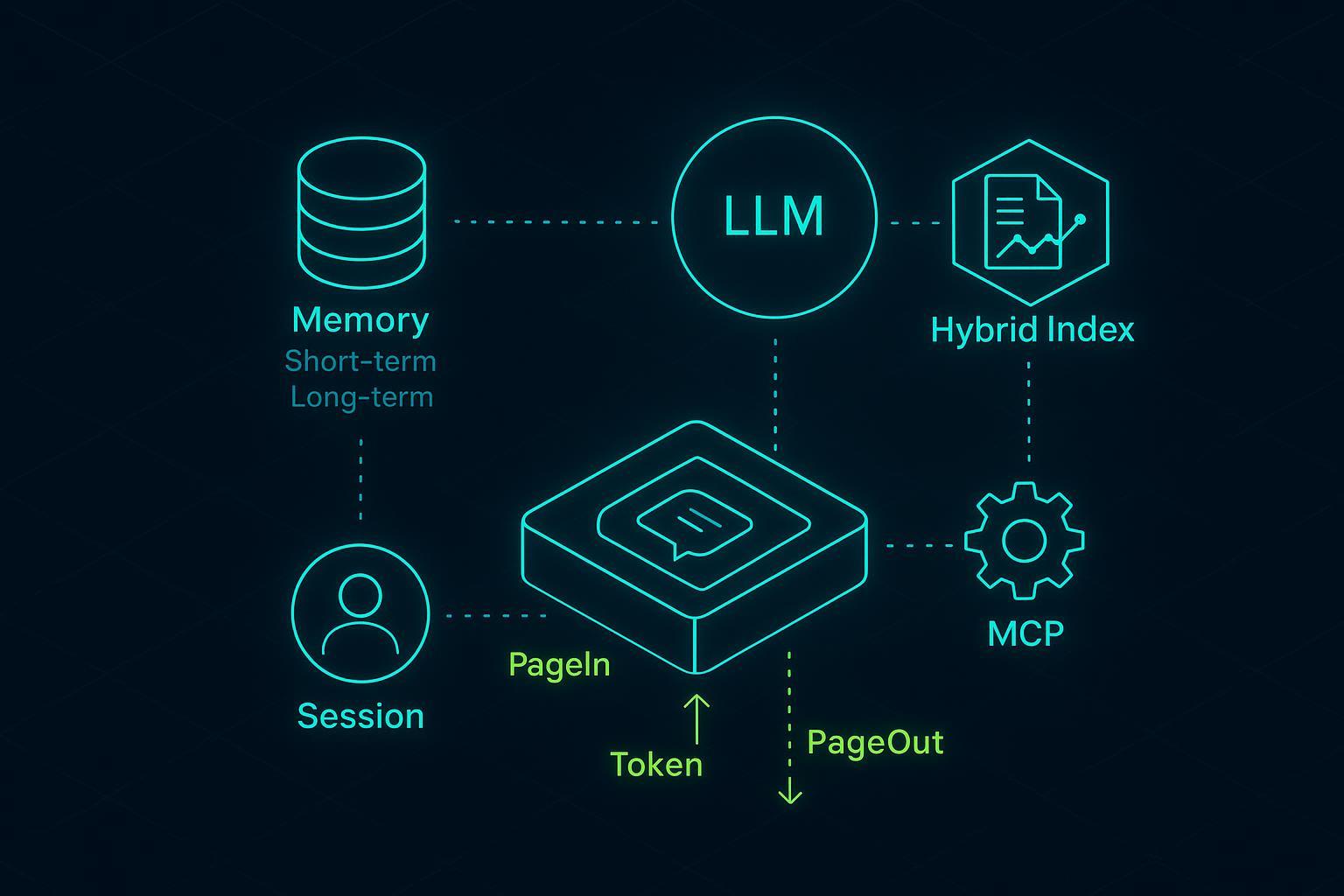
Principais conclusões
- Trate sessão, memória e contexto como preocupações separadas; monte o contexto de forma determinística por turno.
- Use windowing with explicit PageIn/PageOut: score what to include; trim or summarize what to exclude.
- Combine extractive and abstractive compression with milestone notes to minimize summary drift.
- Build a hybrid retriever: filters → lexical (BM25) → vectors → fusion/rerank; bypass vectors for exact IDs.
- Keep tools out of the prompt via programmatic orchestration (MCP), with idempotency and audit trails.
- For customer support, persist user preferences and episodic summaries; inject only what’s relevant each turn.
- Favor local-first deployments for sensitive data; encrypt, audit, and enforce RBAC.
What session, memory, and context mean in production
- Session: The bounded thread of interaction (a conversation window) with lifecycle states such as opened, active, compacted, archived. Sessions own short-term history and counters (turns, tokens).
- Memory: Durable knowledge that survives sessions. Two flavors: short-term (recent turns kept verbatim or summarized) and long-term (facts, preferences, episodic summaries tied to users or entities).
- Context: The turn-specific bundle the model actually sees—system instructions, the latest few messages, selected memories, retrieved snippets, and tool results. In AI Agent context management, you store everything, but you inject only a sliver each turn. That selection is where engineering pays off.
Session lifecycle and windowing model
A simple relational shape works well and keeps options open:
-- Core session objects
CREATE TABLE sessions (
session_id TEXT PRIMARY KEY,
user_id TEXT NOT NULL,
status TEXT CHECK (status IN ('opened','active','compacted','archived')),
created_at TIMESTAMP NOT NULL,
last_turn_at TIMESTAMP,
turn_count INT DEFAULT 0,
token_in INT DEFAULT 0,
token_out INT DEFAULT 0
);
CREATE TABLE messages (
msg_id TEXT PRIMARY KEY,
session_id TEXT NOT NULL,
role TEXT CHECK (role IN ('user','assistant','system','tool')),
content TEXT NOT NULL,
tokens INT,
created_at TIMESTAMP NOT NULL,
FOREIGN KEY (session_id) REFERENCES sessions(session_id)
);
CREATE INDEX idx_messages_session_time ON messages(session_id, created_at);
Short-term history can be modeled as a ring buffer of most-recent N tokens/turns. Beyond thresholds, compact older spans into summaries and milestone notes.
class Window:
def __init__(self, max_tokens: int, keep_last_turns: int = 6):
self.max_tokens = max_tokens
self.keep_last_turns = keep_last_turns
def assemble(self, sys_msg, recent_msgs, milestone_notes, retrieved_snippets, tool_outputs):
# Deterministic ordering by role, then recency
context = [sys_msg]
context += recent_msgs[-self.keep_last_turns:]
context += milestone_notes
context += retrieved_snippets
context += tool_outputs
return trim_to_token_budget(context, self.max_tokens)
Compaction triggers keep the window stable:
def maybe_compact(session, messages, thresholds):
too_many_turns = session.turn_count > thresholds.max_turns
too_many_tokens = (session.token_in + session.token_out) > thresholds.max_tokens
if not (too_many_turns or too_many_tokens):
return None
span = select_older_span(messages, keep_last=thresholds.keep_last_turns)
summary = summarize_extractive_then_abstractive(span)
milestone = extract_structured_facts(span) # commitments, constraints, ids
persist_summary_and_milestone(session.id, summary, milestone)
mark_span_compacted(span)
Key design notes
- Keep the last K turns verbatim (e.g., 4–8) to reduce summary drift.
- Summaries become synthetic “assistant” notes with provenance; milestone notes are structured (YAML/JSON) to support deterministic recall.
- Token accounting should be measured, not guessed. Instrument both input/output tokens per turn and compaction overhead.
PageIn and PageOut selection — scoring and eviction
Think of PageIn as a ranked include-list and PageOut as principled forgetting in AI Agent context management.
Scoring function (example):
def score(item, now):
# item: {type, text, embedding, timestamp, role, metadata}
w_recency = 0.35
w_semantic = 0.45
w_role = 0.10
w_signal = 0.10 # clicks, tool success, citations
recency = exp_decay(now - item.timestamp, half_life_minutes=45)
semantic = cosine(item.embedding, query_embedding())
role_boost = 1.0 if item.role in ("system","milestone") else 0.7
signal = min(1.0, item.metadata.get("utilization_rate", 0.0))
return w_recency*recency + w_semantic*semantic + w_role*role_boost + w_signal*signal
Selection and eviction:
def page_in_out(candidates, budget_tokens):
ranked = sorted(candidates, key=lambda x: score(x, now()), reverse=True)
selected, used = [], 0
for c in ranked:
if used + c.tokens <= budget_tokens:
selected.append(c)
used += c.tokens
else:
continue
# PageOut policy: LRU for plain chat, semantic TTL for knowledge
evict = [x for x in candidates if x not in selected and should_evict(x)]
return selected, evict
def should_evict(item):
if item.type == 'verbatim_turn' and is_older_than(item, minutes=120):
return True
if item.type == 'snippet' and below_similarity(item, 0.25):
return True
return False
Operational notes
- Fuse recency and similarity to avoid pulling irrelevant but recent chatter.
- Assign higher priority to system prompts and milestone notes.
- Keep eviction deterministic; log what was dropped and why to aid debugging.
Complexity and failure modes
- Sorting O(n log n) per turn over tens–hundreds of candidates is fine; cache embeddings and precompute features.
- Failure modes: over-aggressive summarization (loss of rare facts), similarity collapse (poor embedding quality), and drifting milestones. Mitigate with tests and guardrails.
Compression that doesn’t break recall
You’ll need both hard and soft compression:
- Extractive: keep salient sentences, IDs, numbers. Fast, faithful, but may lose paraphrased nuance.
- Abstractive: rephrase and condense. Captures gist, risks omitting edge details; adds latency.
- Token-pruning: model-based pruning (e.g., LLMLingua-2); strong ratios, but prompts become terse.
A hybrid pipeline works well in practice:
def summarize_extractive_then_abstractive(span):
key_sents = extract_top_k_sentences(span, k=8, with_numbers=True)
draft = llm_abstractive_summary(key_sents, style="bullet+yaml_facts")
return draft
Safeguards against summary drift
- Maintain milestone notes as structured facts (YAML/JSON) extracted per span; inject them with high priority.
- Keep N recent turns verbatim.
- Rehydrate details on demand via retrieval if the user reopens a topic.
Comparison (rule-of-thumb)
| Method | Strength | Risk | Added latency |
|---|---|---|---|
| Extractive | Faithful, cheap | Fragmented context | Low |
| Abstractive | Coherent gist | Miss rare facts | Medium |
| Token-pruning | Big savings | Cryptic prompts | Medium–High |
Citations: See the 2024 Prompt Compression Survey and the 2025 LLM-DCP paper for technique overviews and trade-offs.
- Prompt compression overview — 2024: see the survey in Prompt Compression Survey (2024).
- Dynamic Compressing Prompts — 2025: see LLM-DCP (2025).
AI Agent context management with hybrid indexing and deterministic retrieval
Vector-only retrieval is great for paraphrases but brittle for IDs and policies. In AI Agent context management, hybrid pipelines combine filters, sparse lexical signals, and dense vectors; top-K gets fused and optionally reranked.
Retrieval plan
- Filters first: tenant, product, locale, version.
- Lexical pass: BM25/BM25F for exact terms and rare tokens.
- Dense pass: cosine or dot-product over embeddings.
- Fusion: RRF (reciprocal rank fusion) or weighted linear blend.
- Optional: cross-encoder reranker over the fused top-K.
Pseudocode
def hybrid_retrieve(query, k=20, filters=None):
cand_a = bm25_search(query, filters=filters, k=3*k)
cand_b = vector_search(embedding(query), filters=filters, k=3*k)
fused = reciprocal_rank_fusion(cand_a, cand_b, top=k)
return fused
When to bypass vectors
- Deterministic lookups: ticket IDs, SKUs, policy codes → exact-match in structured stores.
- Safety-critical facts: always gate by metadata filters and provenance.
Authoritative references: Elastic’s hybrid search guidance (2024–2026), Weaviate hybrid search primers, and Pinecone’s RAG guides offer concrete fusion and reranking recipes.
- Elastic’s hybrid search practices (2024–2025): see Elastic hybrid search guides and Elastic Labs articles (2024–2025).
- Hybrid retrieval primers: Weaviate hybrid search explained (2024) and Pinecone RAG guide.
MCP tool orchestration patterns that keep context lean
Rather than stuffing tool specs and transcripts into the prompt, call tools programmatically and log the results. MCP formalizes secure, two-way connections to tools and data.
Principles
- Idempotency: each tool call should be safe to retry.
- Atomic execution: wrap multi-step actions with checkpoints and rollbacks.
- Observability: log tool I/O with redaction; include only short summaries in the prompt.
- Timeouts and backoff: avoid hanging turns.
Sketch
@retry(idempotent=True, backoff=expo)
def update_ticket(tool, ticket_id, payload):
with atomic():
ok = tool.call("update_ticket", {"id": ticket_id, "payload": payload})
log_tool_io(tool="ticketing", op="update", id=ticket_id, ok=ok)
return ok
References: Anthropic’s MCP docs and engineering posts (2024–2026) detail patterns for programmatic tool calling, catalogs, and secure connections.
- Standard overview: Anthropic — Model Context Protocol (2024) and MCP docs.
- Programmatic tool calling: Advanced tool use (2025).
Reference build — customer support agent with long-term memory
Goal: an agent that remembers user preferences and prior resolutions across sessions, retrieves the right policy/ticket context, and safely executes updates.
Minimal schema
CREATE TABLE users (
user_id TEXT PRIMARY KEY,
locale TEXT,
tier TEXT,
created_at TIMESTAMP
);
CREATE TABLE memories (
memory_id TEXT PRIMARY KEY,
user_id TEXT NOT NULL,
kind TEXT CHECK (kind IN ('preference','fact','episodic')),
key TEXT,
value JSONB,
embedding VECTOR,
created_at TIMESTAMP,
last_used_at TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
CREATE TABLE tool_logs (
id TEXT PRIMARY KEY,
session_id TEXT,
tool TEXT,
op TEXT,
req JSONB,
res JSONB,
ok BOOLEAN,
created_at TIMESTAMP
);
Memory capture and consolidation
def capture_long_term(session_id, turn_bundle):
prefs = extract_preferences(turn_bundle)
facts = extract_facts(turn_bundle)
episodic = summarize_episode(turn_bundle)
upsert_memories(prefs+facts+[episodic])
Per-turn retrieval and assembly
def assemble_turn_context(session, user_id, query):
filters = {"locale": user_locale(user_id), "tier": user_tier(user_id)}
mem_cands = search_memories(user_id, embedding(query), k=12)
kb_cands = hybrid_retrieve(query, k=20, filters=filters)
candidates = (
last_k_turns(session.id, k=6)
+ milestone_notes(session.id)
+ mem_cands
+ kb_cands
+ recent_tool_summaries(session.id)
)
selected, _ = page_in_out(candidates, budget_tokens=8_000)
return selected
Tool actions with MCP
def maybe_escalate(session, answer):
if needs_escalation(answer):
return update_ticket(mcp_ticket_tool(), ticket_id(answer), payload(answer))
return None
Turn loop (simplified)
def handle_turn(session, user_id, user_msg):
query = user_msg.content
selected = assemble_turn_context(session, user_id, query)
reply = llm_chat(selected + [user_msg])
action = maybe_escalate(session, reply)
capture_long_term(session.id, turn_bundle=(user_msg, reply, action))
return reply
A neutral product example (Knowledge Base Source)
- If you prefer a context base designed for agents, you can store structured “Know-How” and hybrid indexes in a system like puppyone (Knowledge Base Source). It focuses on machine-readable JSON/Graph and local-first deployment via Docker so sensitive data stays on your infra. This can simplify deterministic lookups for IDs/policies while still supporting semantic recall. Use this only where it fits your stack; the patterns above work with general-purpose stores, too.
Privacy and local-first deployment
For customer data, keep the kernel close to the data.
Checklist (mapped to widely used controls)
- Local-first: run the agent kernel and stores inside your VPC; use signed images and minimal base OS.
- Encryption at rest: encrypt volumes for vector/structured stores; rotate keys; zeroize on decommission (maps to NIST SC-28 guidance).
- Access control: strict RBAC for agent services; deny-by-default network policy; short-lived credentials (AC-2/3/6 family).
- Audit logging: centralize and protect tool logs, retrieval traces, and escalation events; alert on anomalies (AU-2/3/6/12 family).
Background sources: NIST CSRC materials on encryption, access control, and auditing provide stable anchors for privacy-first operations.
- General mappings: NIST SP 800-171 Rev.3 (2024) and CSRC guidance at NIST CSRC portal.
Evaluate what matters
Define success with a small pilot before broad rollout.
Metrics
- Retrieval quality: Precision@K, Recall@K, nDCG@K, and MRR.
- Response quality: groundedness/faithfulness and completeness; judge with rubric + spot audits.
- System: token-in/out per turn, added compression latency, retrieval latency, cost per query, and tool success/error rates.
Pilot plan (example targets)
| Area | Baseline | Target after windowing + hybrid |
|---|---|---|
| Token in (p50) | 11k | 6k |
| Latency (p50) | 3.2s | 2.1s |
| nDCG@10 | 0.62 | 0.74 |
| Task success | 72% | 83% |
Run A/Bs: toggle compression, vary K in hybrid retrieval, and compare keep_last_turns=4 vs. 8. Instrument compaction overhead to confirm savings aren’t eaten by summarization calls.
Closing thoughts and next steps
Keep the window small, the rules explicit, and the logs honest. Start with deterministic trims, add hybrid retrieval, and layer compression only where it pays. For reliable AI Agent context management at scale, treat recall as a product feature, not a side effect. If you need a context base purpose-built for agents, evaluate options like puppyone alongside your existing stack.