Guia definitivo do Model Context Protocol (MCP)
3 de abril de 2026Ollie @puppyone
Key takeaways
- MCP não substitui seu modelo de dados nem sua camada de governança. Ele padroniza como hosts de agentes descobrem e chamam tools, resources e prompts.
- A decisão de produção quase nunca é “MCP ou API”; o ponto central é qual superfície deve responder por discovery, determinismo, enforcement e auditoria.
- Um bom rollout de MCP mantém tools estreitos, respostas estáveis e separa caminhos de leitura e escrita.
- Hardening de Docker, tracing de requests e logs estruturados importam tanto quanto prompts porque determinam se um incidente pode ser contido e reconstruído.
- puppyone se torna útil quando o problema deixa de ser “conectar ferramentas” e passa a ser distribuir a mesma base de contexto governada por MCP, API e Skills sem duplicar conhecimento.
O que o MCP faz de verdade
Muitas equipes descrevem o Model Context Protocol como “o padrão para conectar ferramentas a agentes de IA”. Isso está certo, mas ainda é vago demais para orientar arquitetura.
Uma leitura mais útil:
- MCP padroniza a descoberta de capacidades
- MCP padroniza a invocação dessas capacidades
- MCP não resolve sozinho modelagem de conhecimento, desenho de políticas ou estabilidade de saída
A especificação oficial define MCP como um protocolo baseado em JSON-RPC para expor tools, resources e prompts a runtimes de agentes. Vale revisar a especificação, a seção de lifecycle e o anúncio original da Anthropic sobre Model Context Protocol.
O que MCP não resolve:
- dados desatualizados ou contraditórios
- limites de tool amplos demais
- autorização fraca
- trilhas de auditoria insuficientes
- payloads instáveis que obrigam o modelo a adivinhar
Por isso equipes maduras tratam MCP como protocolo de entrega, não como arquitetura completa.
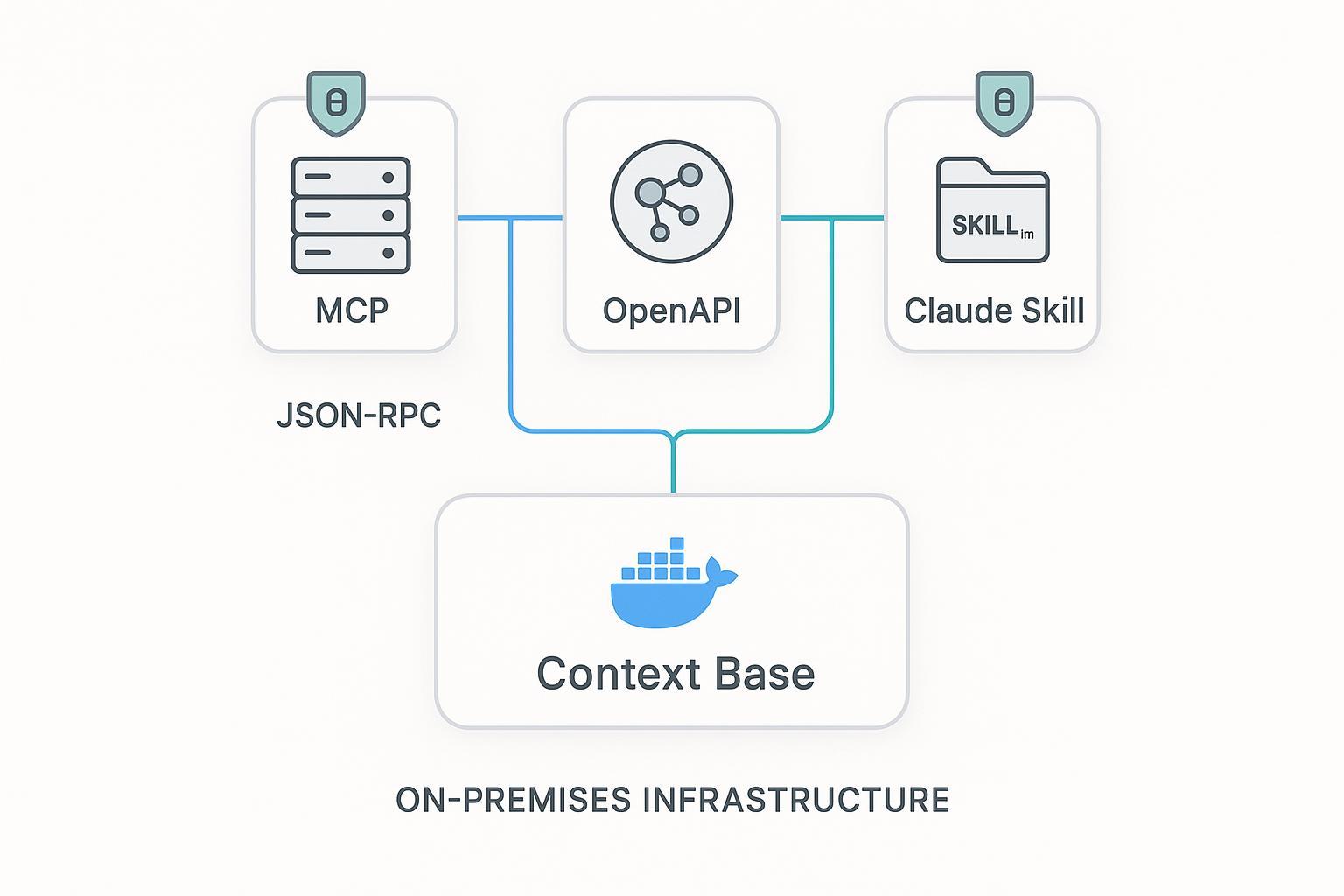
Quando usar MCP e quando não usar
Um erro comum é colocar toda capacidade atrás de MCP apenas porque parece moderno. Na prática, é melhor escolher a superfície conforme o trabalho.
| Superfície | Força | Fraqueza | Use quando |
|---|---|---|---|
| Servidor MCP | Discovery, execução nativa para agentes, interoperabilidade | Payloads estáveis e políticas ainda precisam ser projetados | O consumidor é um host de agentes e aproveita a semântica de tools/resources |
| REST API | Contratos determinísticos, auth/gateways/caches maduros | O agente precisa conhecer a semântica do endpoint | Você precisa de contratos duradouros para agentes, apps e serviços |
| Skills | Empacotar workflows e guardrails | Fraco como plano de dados em tempo real | Você quer distribuir instruções reutilizáveis e puxar dados vivos via MCP/API |
Regra prática:
- capacidades centradas em discovery: MCP
- capacidades centradas em contrato: REST
- conhecimento centrado em workflow: Skills
Essa combinação costuma ser a mais sólida em produção.
Ver MCP governado com puppyoneGet startedUm design mínimo de MCP que aguenta produção
Um tool MCP fraco costuma virar um wrapper gigante que “faz tudo”. Um tool MCP forte tem escopo estreito, entrada rígida e saída previsível.
Princípios básicos:
- um tool, um trabalho
- esquema de entrada estrito
- envelope de saída estável
- checagem de política antes de devolver dados
- respostas com identificadores rastreáveis
import { McpServer } from "@modelcontextprotocol/sdk/server";
const server = new McpServer({ name: "org-context" });
server.tool(
"get_knowhow_item",
{
description: "Read one governed Know-How item by id",
inputSchema: {
type: "object",
properties: { id: { type: "string" } },
required: ["id"],
additionalProperties: false
}
},
async ({ id }, ctx) => {
const item = await ctx.store.read(id);
if (!ctx.policy.canRead(ctx.user, item.policyTag)) {
return {
ok: false,
error: { code: "forbidden", message: "Access not permitted" }
};
}
return {
ok: true,
data: {
id: item.id,
title: item.title,
version: item.version,
summary: ctx.redactor(item.summary)
},
trace: {
requestId: ctx.requestId,
policyTag: item.policyTag
}
};
}
);
O valor está em não transformar o tool em uma passagem sem fronteiras para todo o sistema interno.
Hardening de Docker faz parte do design de MCP
Muitos tutoriais de MCP terminam em “o servidor está rodando”. Isso não basta se esse servidor pode ler contexto sensível ou disparar ações.
Base mínima de hardening:
- executar como usuário não root
- usar filesystem somente leitura sempre que possível
- montar secrets como arquivos
- definir health checks
- restringir egress de rede
- anexar correlation IDs a cada execução
A documentação do Docker para HEALTHCHECK, Compose healthchecks, rootless/non-root e bind mounts continua muito útil.
FROM node:22-slim AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci --ignore-scripts
COPY . .
RUN npm run build && npm prune --omit=dev
FROM gcr.io/distroless/nodejs22-debian12:nonroot
WORKDIR /app
COPY --from=build /app/dist ./dist
USER 65532:65532
ENV NODE_ENV=production
CMD ["/nodejs/bin/node", "dist/server.js"]
Seja local-first ou on-prem, sem fronteiras claras de runtime não existe confiança operacional real.
Por que uma REST API versionada ainda importa
MCP é excelente para execução nativa de agentes, mas uma REST API versionada continua oferecendo:
- versionamento explícito
- paginação e filtros estáveis
- auth, rate limits e cache no gateway
- reaproveitamento por agentes, apps e serviços internos
Por isso muitas equipes expõem o mesmo contexto governado via MCP e via REST. As orientações de design de APIs da Azure, junto com RFC 6585 e RFC 9110, continuam úteis para throttling e Retry-After.
O importante não é duplicar por duplicar, mas especializar:
- MCP para discovery e semântica de tools
- REST para contratos determinísticos
Se você precisa dos dois, isso é totalmente normal.
Skills é camada de empacotamento, não plano de dados
Skills funciona muito bem para distribuir intenção operacional: o que fazer, o que evitar e em que sequência agir.
Serve especialmente para:
- instruções de workflow
- passos de troubleshooting
- hábitos compartilhados de revisão
- guias por papel
Mas Skills sozinho não resolve frescor, autorização ou retrieval estruturado. A documentação da Anthropic sobre skills e o repositório público anthropics/skills mostram bem o formato.
Divisão pragmática:
- o Skill define fluxo e restrições
- o Skill chama um tool MCP ou endpoint REST
- o runtime registra request, resultado e decisão de política
Observabilidade é o que torna MCP auditável
Se um agente usar um tool de forma incorreta, você precisa conseguir responder:
- quem fez a chamada
- qual tool ou resource estava exposto
- quais inputs foram enviados
- qual decisão de política foi aplicada
- qual hash ou identificador de resultado voltou
- quanto tempo levou
Por isso OpenTelemetry e logs estruturados não são luxo. São o que permite reconstruir incidentes. Os documentos sobre context propagation e traces são bons pontos de partida. Para retenção e auditoria, veja NIST SP 800-92 e SP 800-53 Rev.5.
{
"ts": "2026-04-03T09:15:00Z",
"event": "tool.execute",
"requestId": "req_7ad2",
"tool": "get_knowhow_item",
"actor": "agent_ops_reader",
"decision": "allow",
"resultHash": "sha256:ab12...",
"latencyMs": 42
}
Se sua stack não consegue produzir algo assim, o problema principal ainda não é a escolha do protocolo.
Onde puppyone entra
A maioria dos projetos MCP falha não por causa do protocolo, mas por causa do contexto atrás dele:
- o conhecimento está espalhado
- cada tool vê uma verdade diferente
- permissões finas são difíceis de aplicar
- versionamento e linhagem de auditoria são frágeis
É aqui que uma base de contexto governada faz diferença. Equipes avaliam puppyone para estruturar Know-How empresarial, aplicar hybrid indexing e distribuir o mesmo conhecimento governado por MCP, API ou empacotamento de workflow. Assim, o servidor MCP deixa de remontar contexto ad hoc a cada chamada.
Isso é especialmente valioso quando:
- vários agentes precisam da mesma source of truth
- o mesmo conhecimento deve sair por MCP e por API
- aprovações exigem identificadores estáveis e provenance
- local-first ou self-hosted é importante
Leituras relacionadas:
- Context Engineering: When RAG Isn't Enough
- Vector Database vs. Context Base: What AI Agents Actually Need in Production
- Puppyone + OpenClaw Integration Playbook for Engineers
O que fazer agora
Se você está no começo, não inicie com uma grande migração de protocolo. Escolha um workflow com muita leitura e torne-o previsivelmente confiável:
- defina um tool MCP estreito
- devolva um response envelope estável
- faça enforcement fora do modelo
- adicione trace IDs e logs estruturados
- só crie um endpoint REST paralelo quando um segundo consumidor realmente precisar
Depois disso, expandir tools, Skills e orchestration fica muito mais seguro.
Planejar rollout MCP com puppyoneGet startedFAQs
Q1. MCP substitui APIs REST?
Não. MCP é forte para execução orientada a agentes; REST continua melhor para contratos estáveis, controles de gateway e reutilização ampla.
Q2. Toda capacidade interna deve virar um tool MCP?
Não. Tools amplos demais são difíceis de governar e depurar. Comece com capacidades estreitas, tipadas e previsíveis.
Q3. Skills sozinho é suficiente?
Na maioria dos casos, não. Skills empacota bem a intenção do workflow, mas se frescor, autorização e auditabilidade importam, você ainda precisará de tools MCP ou APIs para os dados de runtime.