Compliance Management FOR AI Agents
AI 智能体的合规管理:治理与审计
AI 智能体合规管理的技术指南:审计跟踪、信息治理、沙盒隔离,以及为什么 MUT 等协议层至关重要。
Ollie @puppyone2026年3月31日
很多团队第一次接触 Model Context Protocol,都会把它理解成“把工具接给 AI 智能体的标准协议”。这个说法没错,但还是太宽泛,不足以指导架构设计。
更有用的理解方式是:
官方规范把 MCP 描述为一个基于 JSON-RPC 的协议,用来向 agent runtime 暴露 tools、resources 和 prompts。它的价值在于减少一堆自定义适配器,并给初始化、能力协商和执行过程一个统一生命周期。可参考 Model Context Protocol 规范、生命周期章节 以及 Anthropic 最初发布的 Model Context Protocol 公告。
但 MCP 不会替你解决:
所以成熟团队会把 MCP 当作“交付协议”,而不是一整套 agent 架构的答案。
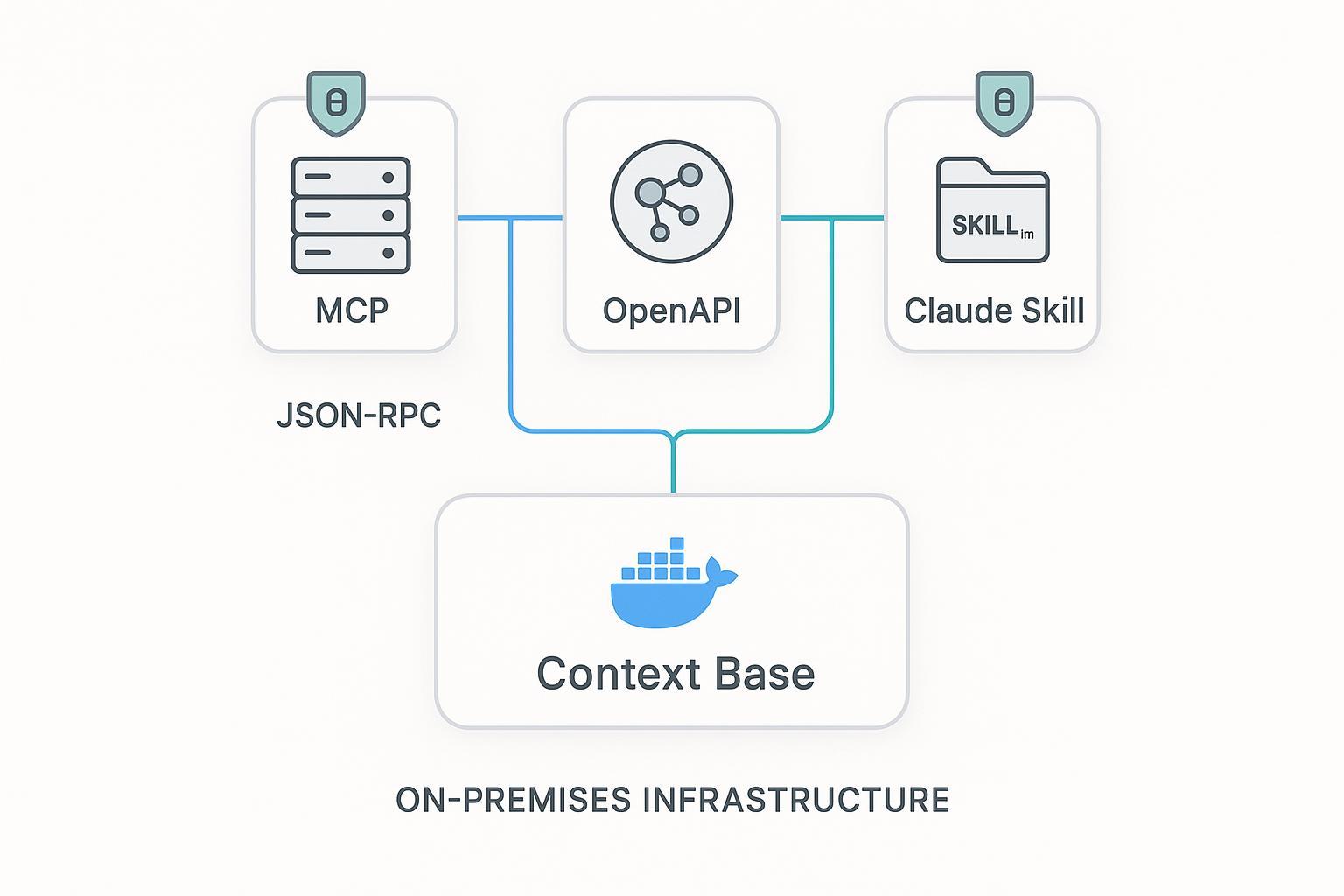
最容易把系统做复杂的方式,就是因为 MCP 很新,就强行把所有能力都塞进 MCP。更好的方法是,根据任务选择最合适的接口层。
| 接口层 | 最擅长什么 | 短板 | 适合什么场景 |
|---|---|---|---|
| MCP server | 能力发现、agent 原生调用、host 互操作 | 你仍然需要自己设计稳定 payload 和策略控制 | 调用方本身就是 agent host,并且能从 tools/resources 语义里获益 |
| REST API | 契约稳定、网关策略成熟、鉴权与缓存体系完善 | 智能体必须先理解端点语义 | 需要给智能体、Web 应用和内部系统同时复用的长期接口 |
| Skills | 打包工作流说明、约束和操作习惯 | 单独使用时不适合作为实时数据平面 | 想分发一套可复用流程,再通过 MCP 或 API 拉实时数据 |
一个很实用的判断规则是:
这往往才是更真实的生产栈:MCP 负责发现能力,REST 负责确定性接口,Skills 负责把流程经验打包给人和智能体。
看看 puppyone 如何交付治理过的 MCPGet started一个差的 MCP 工具通常长这样:“这里有个大而全的函数,自己想办法调用。” 一个更强的版本,则应该是职责清晰、输入收敛、输出稳定的窄工具。
通常意味着:
示意代码如下:
import { McpServer } from "@modelcontextprotocol/sdk/server";
const server = new McpServer({ name: "org-context" });
server.tool(
"get_knowhow_item",
{
description: "Read one governed Know-How item by id",
inputSchema: {
type: "object",
properties: { id: { type: "string" } },
required: ["id"],
additionalProperties: false
}
},
async ({ id }, ctx) => {
const item = await ctx.store.read(id);
if (!ctx.policy.canRead(ctx.user, item.policyTag)) {
return {
ok: false,
error: { code: "forbidden", message: "Access not permitted" }
};
}
return {
ok: true,
data: {
id: item.id,
title: item.title,
version: item.version,
summary: ctx.redactor(item.summary)
},
trace: {
requestId: ctx.requestId,
policyTag: item.policyTag
}
};
}
);
这段代码并不炫技,恰恰因为如此才适合生产。
它真正的价值,在于拒绝让工具变成一个对内部系统“无边界透传”的大口子。
很多 MCP 教程讲到“server 跑起来了”就结束了。但如果这个 server 能读取敏感知识、访问内网工具,甚至触发写动作,那远远不够。
如果你把 MCP 跑在容器里,最起码的加固基线应该是这些“无聊但必须做”的事情:
Docker 官方文档对 HEALTHCHECK、Compose healthcheck、rootless / 非 root 运行 和 只读挂载 都有很实用的说明。这些不是运维细枝末节,而是防止上下文服务进程权限过大、边界失控的关键。
示意容器模式:
FROM node:22-slim AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci --ignore-scripts
COPY . .
RUN npm run build && npm prune --omit=dev
FROM gcr.io/distroless/nodejs22-debian12:nonroot
WORKDIR /app
COPY --from=build /app/dist ./dist
USER 65532:65532
ENV NODE_ENV=production
CMD ["/nodejs/bin/node", "dist/server.js"]
哪怕你的运行环境不是 Docker,这个原则也一样成立:只有运行边界清晰,本地优先或私有化部署才真正可信。
MCP 很适合 agent 原生调用,但确定性 API 仍然重要,因为它能提供:
所以很多团队会把同一份受治理的上下文同时通过 MCP 和 REST 暴露出来。Microsoft 的 Web API design 指南 对版本、分页和响应 envelope 仍然很有参考价值,而 RFC 6585 与 RFC 9110 则适合用来处理限流和 Retry-After 语义。
这里的关键不是“为了双写而双写”,而是接口分工:
如果你的智能体体系同时需要两者,这很正常。
Skills 的价值,在于它可以把一套可复用的操作意图打包出来:该做什么、该避免什么、什么顺序更安全、引用哪些证据更合适。
所以它很适合承载:
但 Skills 本身并不适合单独承担实时数据平面,因为说明文字不能替代 freshness、鉴权和结构化检索。Anthropic 关于 skills 的文档 以及公开的 anthropics/skills 仓库 都很适合作为格式参考。
更稳妥的模式通常是:
这样就能让“说明”和“数据交付”各归其位。
如果一个智能体错误地调用了某个工具,你至少要能回答这些问题:
这也是 OpenTelemetry 和结构化日志从“平台加分项”变成“生产必需品”的原因。没有这些,你连事故回放都要靠猜。OpenTelemetry 关于 context propagation 和 traces 的文档很适合作为起点;而 NIST 的 SP 800-92 修订草案 与 SP 800-53 Rev.5 则适合用来校对日志留存和审计控制。
一个最小可用日志结构可以长这样:
{
"ts": "2026-04-03T09:15:00Z",
"event": "tool.execute",
"requestId": "req_7ad2",
"tool": "get_knowhow_item",
"actor": "agent_ops_reader",
"decision": "allow",
"resultHash": "sha256:ab12...",
"latencyMs": 42
}
如果你的系统做不到这种级别的可回放,那眼下最核心的问题还不是协议选型。
多数 MCP 项目失败,并不是因为协议本身不清楚,而是因为协议背后的上下文太乱:
这正是“受治理的 context base”应该补上的空缺。
在实践里,团队评估 puppyone 时,往往会把它当成这样一层:把企业 Know-How 结构化、做 hybrid indexing,并把同一份受治理知识通过 MCP、API 或工作流封装持续分发出去。这样一来,MCP server 不再需要每次调用都临时拼上下文,而是直接服务一个经过整理、带权限和可追溯信息的上下文工件。
这个模式尤其适合这些场景:
如果你想继续往相邻的架构模式看,可以读这几篇:
如果你还处在早期,不要一上来就搞一场“大协议迁移”。先挑一个读多写少的工作流,把它做得足够扎实:
等这套基础打稳了,再往上加更多 tools、更多 Skills 和更复杂的 orchestration,风险会小很多。
用 puppyone 规划受治理的 MCP 落地Get started不会。MCP 非常适合面向智能体的原生调用,但在需要主机无关的稳定契约、成熟网关控制和跨系统复用时,REST 仍然是更好的选择。
不应该。边界过宽的工具很难治理,也更难调试。更好的方式是从职责窄、输入严格、输出可预测的能力开始。
通常不够。Skills 很适合打包流程意图,但如果你关心数据新鲜度、权限控制和可审计性,它仍然需要依赖 MCP tools 或 API 来获取受治理的运行时数据。